







问题
基于日志结构合并树(LSM-tree)的键值(KV)存储系统在硬盘驱动器(HDD)上为写入密集型应用提供了高吞吐量。新兴的交错磁记录(IMR)技术,使得基于IMR的HDD成为构建经济高效的KV存储系统的另一个理想选择,因为它具有高面积密度。然而,在IMR基础的HDD上部署基于LSM-tree的KV存储系统可能导致传入读/写的吞吐量明显下降。

挑战
IMR布局中,任何顶部轨道都可以自由更新,而对底部轨道的更新将在其两个相邻的顶部轨道上引入最多两个轨道重写。为了在确保崩溃一致性的情况下进行磁道重写,提出了读-修改-写(RMW)方法[25]。
在基于IMR的HDD上部署基于LSM树的KV存储,可能会显著降低传入读/写的吞吐量。原因是基于IMR的HDD的RMW过程会放大由压缩过程引入的背景I/O,而这种放大的背景I/O可能会降低压缩过程的效率,并进一步降低传入读/写的吞吐量[9,39,53]。
本文方法
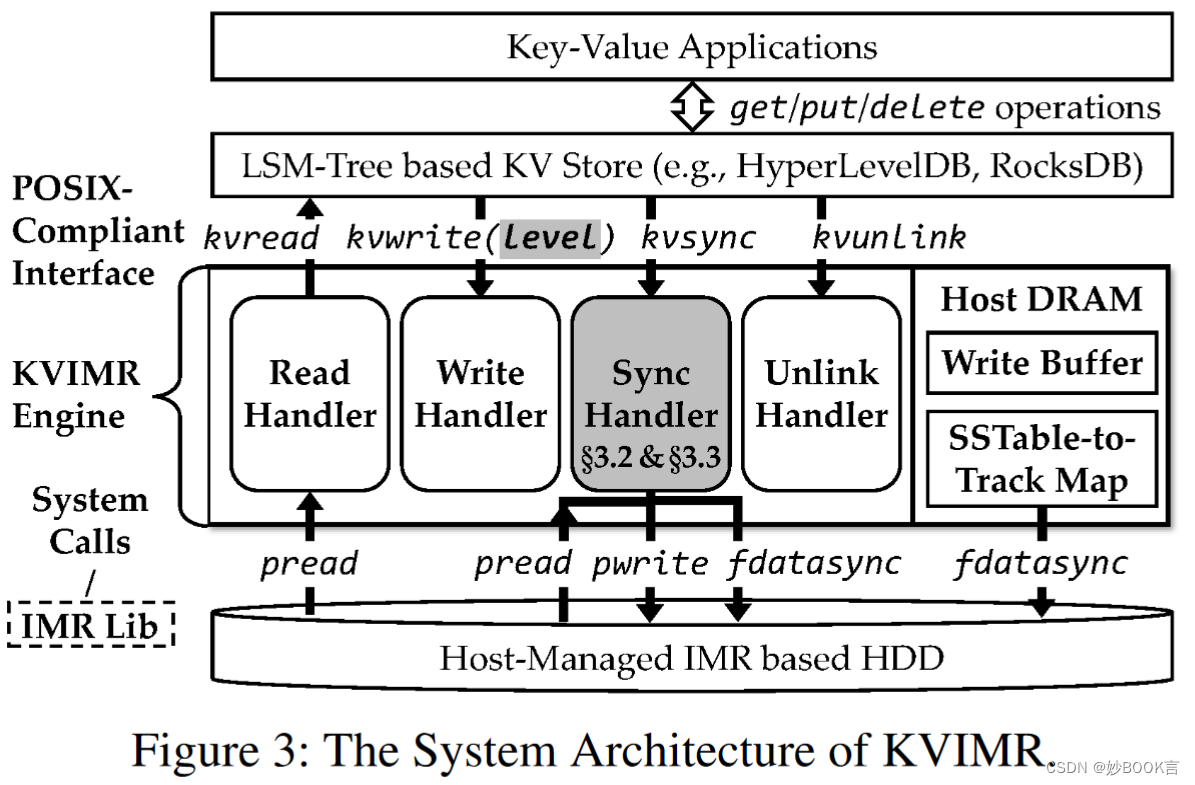
本文提出了KVIMR,在基于IMR的HDD上构建基于LSM-tree的KV存储系统,保持经济高效且高吞吐量。KVIMR为中间件,插入在基于LSM-tree的KV存储系统和基于IMR的HDD之间,以保持对主流LSM-tree KV存储系统的兼容性,并进行有限的修改。
-
采用了压缩感知的路径分配方案:在保持数据文件(即SSTables)同时最小化耗时的RMW;在压缩过程中有效地访问数据文件,补救了吞吐量下降,并提高了压缩效率。
-
利用了合并RMW方法,以提高将KV存储系统的多路文件持久化到IMR路径的效率,其关键思想是将多个逐轨RMW重新排序为一个合并的RMW,同时仍确保崩溃一致性。
评估显示,KVIMR在写入密集型工作负载下,将整体吞吐量提高了高达1.55倍,在HDD的高空间使用率下,实现了2.17倍的吞吐量。
实验
实验环境:仿真方法[39],用基于CMR的HDD(型号ST500DM002[1])来仿真100 GB的IMR HDD。
数据集:YCSB[14]
实验对比:吞吐量、压缩时间、IMR重写数量、同步调用数量
总结
针对基于IMR的HDD上的基于LSM-tree的KV存储优化。作者提出KV存储和HDD间的中间件:采用了压缩感知的路径分配方案,在保持数据文件(SSTables)同时最小化耗时的RMW,在压缩过程中有效地访问数据文件,补救了吞吐量下降,并提高了压缩效率;利用了合并RMW方法,以提高将KV存储系统的多路文件持久化到IMR路径的效率,其关键思想是将多个逐轨RMW重新排序为一个合并的RMW,同时仍确保崩溃一致性。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











