







 文章探讨了现有内存缓存的局限性,特别是在多核环境下。作者提出FrozenHot,通过将缓存分为冻结缓存和动态缓存,解决数据倾斜和热点问题,显著提升吞吐量,减少延迟。实验证明其在Twitter和MSR轨迹数据集上的优越性能。
文章探讨了现有内存缓存的局限性,特别是在多核环境下。作者提出FrozenHot,通过将缓存分为冻结缓存和动态缓存,解决数据倾斜和热点问题,显著提升吞吐量,减少延迟。实验证明其在Twitter和MSR轨迹数据集上的优越性能。
问题
缓存对于加速数据访问至关重要。随着核心数量的增加,以及缓存和现代存储设备之间的延迟差距的缩小,命中路径的可扩展性变得越来越重要。
挑战
现有的内存缓存通常使用基于列表的管理,并对每个缓存命中进行升级,这需要大量的锁,并且在扩展到几个核心之外时会带来很大的开销。随着线程数的增加,现有缓存实现的命中延迟显著增加,同时每个核的吞吐量显著下降。
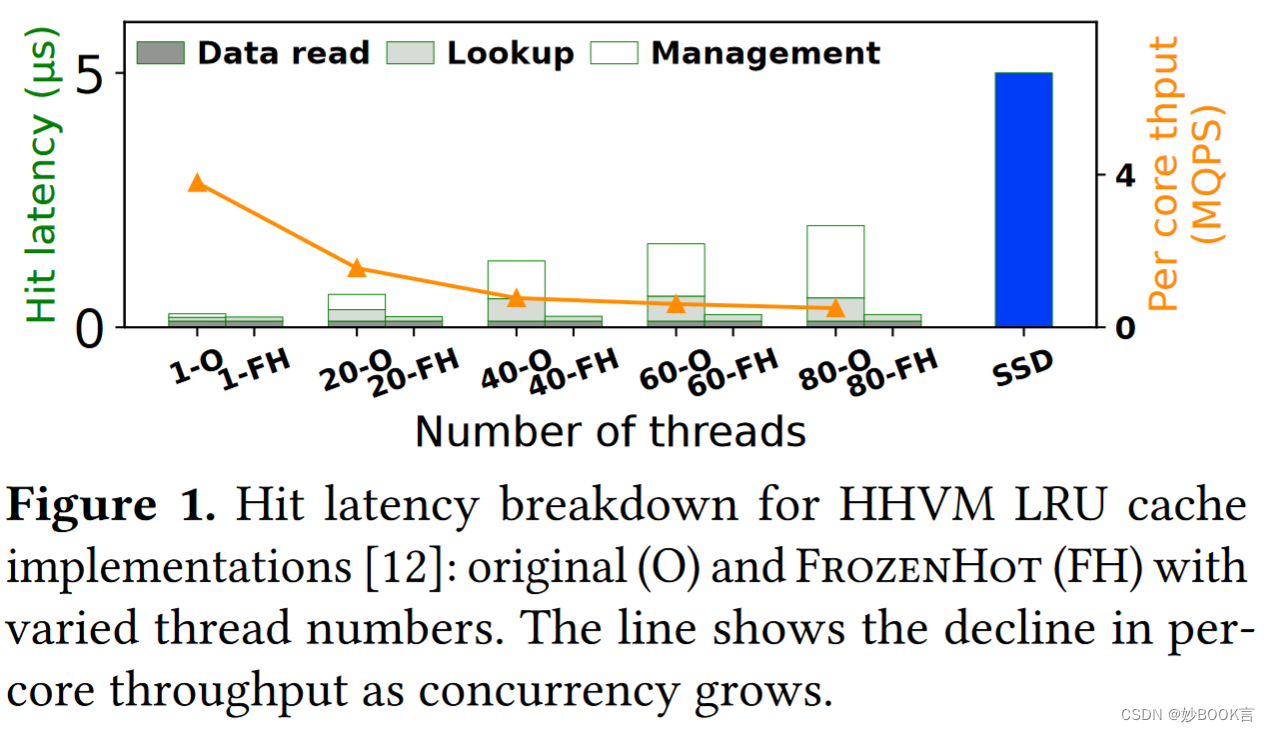
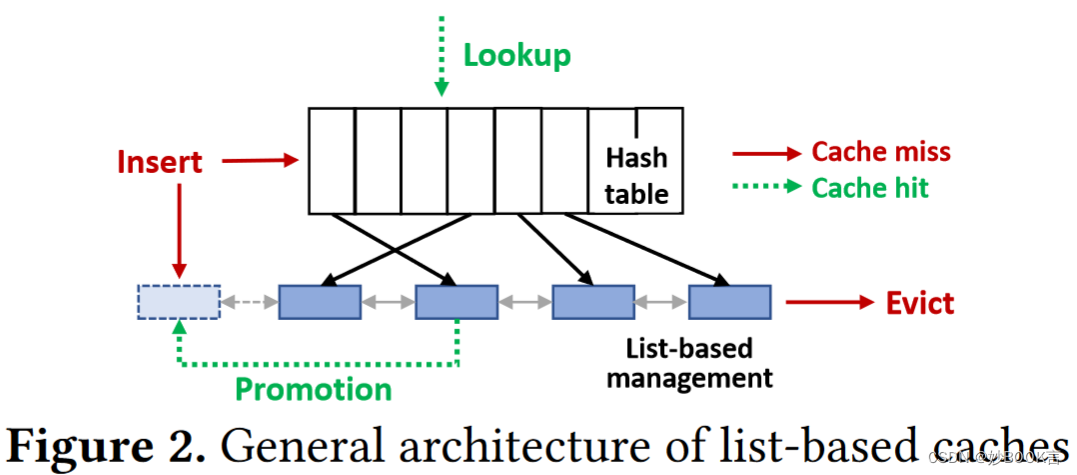
这种由缓存引发的管理甚至对最友好的缓访问流量也会造成性能下降:(1)对不同数据对象的独立用户访问,经历了对共享缓存数据结构的激烈竞争;(2)由于缓存元数据更新,原始读取量大甚至只读的用户访问现在变得写密集型。
此外,现有的用于提高可扩展性的技术要么(1)只关注索引结构而不提高缓存管理可扩展性,要么(2)牺牲效率或缺失路径可扩展性。
本文方法
受高速缓存工作负载中数据高度倾斜性和短期热点稳定性的启发,传统缓存执行的连续管理往往是浪费。以LRU缓存为例:当工作负载具有较强的时间局部性时,许多时间都用于重新排列LRU列表前半部分内的项目;当工作负载具有较差的局部性(如扫描)时,会在替换上花费更多的时间,但不一定会提高缓存效率(命中率)。
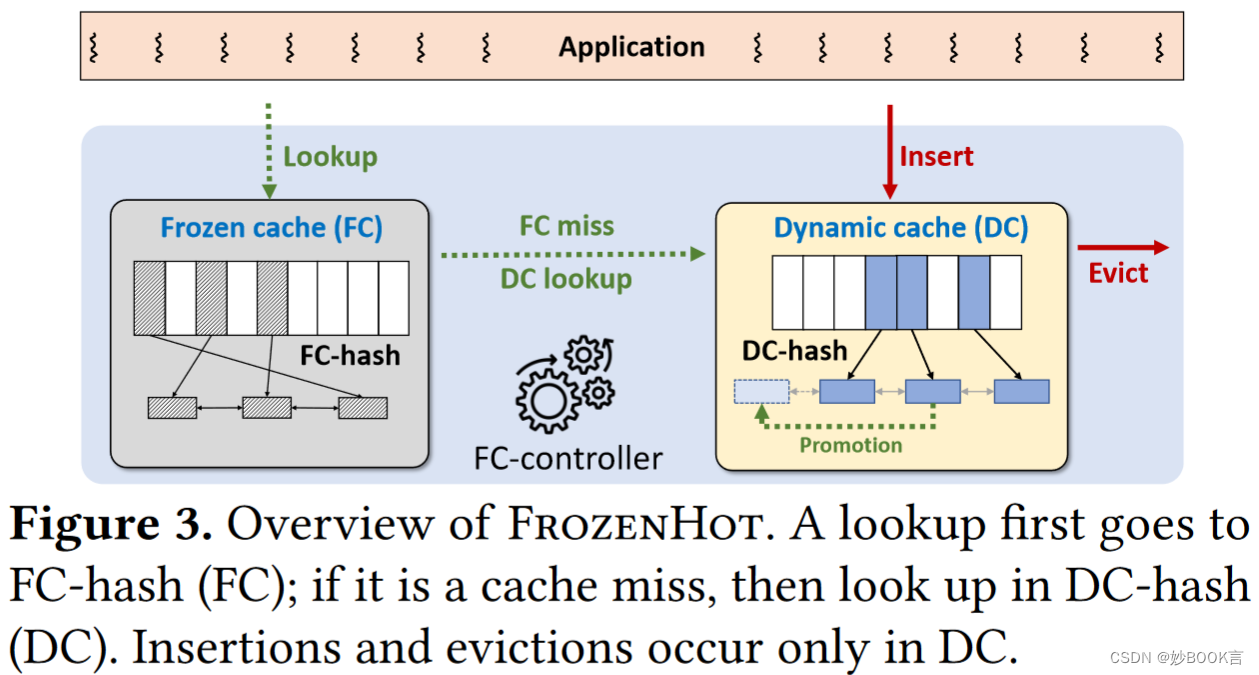
本文提出了FrozenHot,将缓存空间划分为两部分:冻结缓存和动态缓存。冻结缓存通过消除缓存管理和锁,以最小的延迟为热对象的请求提供服务,动态缓存利用现有的缓存设计来实现工作负载自适应。冻结缓存不随时更新,而是定期重建以适应工作负载的变化,使用轻量级后台冻结缓存控制器,根据访问模式、并发级别和缓存大小自适应地选择冻结缓存大小。
开源代码:GitHub - ziyueqiu/FrozenHot
本文将FrozenHot构建为一个可以集成到现有系统中的库。通过MSR和Twitter的生产跟踪进行评估,FrozenHot将三种基线缓存算法的吞吐量提高了551%。与RocksDB相比,FrozenHot增强型RocksDB在所有YCSB工作负载上都显示出更高的吞吐量,最高可提高90%,并减少了尾延迟。
实验
实验环境:两个双插槽服务器,分别带有Intel Xeon(R)Platinum 8360Y 36核处理器(运行Ubuntu 18.04.1)和8380 40核处理器(在CentOS 8.5上运行)。两者都有256GB的DRAM,前者用于轨迹实验,后者使用1.5TB Optane P5800X SSD进行存储,用于RocksDB运行。
数据集:Twitter轨迹[2,75],MSR剑桥轨迹[23,60],YCSB
实验对比:吞吐量、线程数、缓存命中率、缓存命中延迟、缓存大小影响、存储设备延迟影响
总结
本文对缓存算法进行优化,发现多数工作负载中数据高度倾斜,且短期热点稳定。本文提出FrozenHot,将缓存空间划分为两部分:冻结缓存和动态缓存。冻结缓存通过消除缓存管理和锁,以最小的延迟为热对象的请求提供服务。冻结缓存不随时更新,而是定期重建以适应工作负载的变化,使用轻量级后台控制器,根据访问模式、并发级别和缓存大小自适应地选择冻结缓存大小。动态缓存利用现有的缓存设计来实现工作负载自适应。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











