







arXiv Paper CXL论文阅读笔记整理
问题
日益专业化的趋势导致了加速器和替代处理设备的激增,当嵌入传统计算机体系结构时,将CPU连接到这些设备的PCIe链路会成为瓶颈。CXL是PCIe之上的一种互连协议,具有更现代、更强大的接口,使用CXL可以在机架中的机器之间构建共享内存系统。
这些变化将对数据库引擎和数据处理系统产生重大影响,虽然云支持横向扩展方法,但CXL引入了垂直扩展体系结构。在本文中,描述了CXL如何实现这种体系结构,以及与新兴的大规模异构硬件平台相关的研究挑战。
背景
CXL扩展了一致性域

CXL性能
-
延迟:针对给定类型的CXL连接的内存执行加载指令比等效的NUMA内存访问长35%,在相同条件下执行存储可能会带来略低但相当的开销。
-
带宽:衡量可以达到标称存储器带宽容量的百分比。当仅考虑load时,从NUMA节点的传输效率可以达到70%,通过CXL互连读取相同类型的内存传输效率为46%。如果将store定向到CXL设备,则其带宽效率可能比邻居NUMA套接字高12%。原因是存储到CXL设备可以绕过NUMA节点上必须进行的几个一致性检查。
CXL互联
CXL互连效率预计比传统网络、基于RDMA的网络高。原因是RDMA需要在Infiniband/RoCE协议和PCIe协议之间进行转换,NIC使用PCIe与其主机进行通信,但Infiniband/RoCE用于与系统的其他部分进行交互。如DirectCXL[15]中得出,CXL通信的延迟在300纳秒左右,RDMA中最快的交换至少需要2.7微秒,相差8.3倍。
CXL 3.1中,两个对等外围设备可以独立于服务器访问彼此的内存,同时引入了全局集成内存(GIM)的概念,允许多个服务器和外围设备贡献全局映射的内存区域,即多个服务器与外围设备共享同一区域。
共享内存架构
内存扩展

内存扩展方法如图2(a),产生的问题:
-
应该如何处理内存扩展?作为带有分页的块设备,还是作为可寻址存储器?前者使集成更容易,但后者可能会带来更多的性能和设计机会。
-
对于OLTP来说,内存扩展足够快吗?还是主要适用于OLAP?它可以在同一台机器上同时执行吗?有什么含义?
-
哪些数据结构应该保存在本地内存中,哪些数据结构在内存扩展中?这些数据结构是否适合CXL内存造成的内存访问不均匀性的增加?
分离式内存
如图2(b),优势是跨机器的迁移和弹性,产生的问题:
-
实现这些功能需要重新思考内部数据库体系结构,以消除所有内容都在本地内存中的假设。哪些需要是本地的,哪些可以放在分解的内存中,需要进行广泛的实验来确定引擎的哪个部分可以承受CXL内存的额外延迟。
-
通过适当的体系结构方法,引擎可以变得更有弹性。这应该在整个引擎的级别上完成,还是可以将弹性向下推到运行查询的线程级别?
-
通过将运行查询的线程的状态和工作空间保存在分解的内存中,可以将它们从一台机器移动到另一台机器。或者,可以根据工作负载的要求创建它们。在动态变化的多道程序设计级别下,引擎将如何运行?
共享内存
如图2(c),应用于分布式数据库,进行横向扩展,产生的问题?
-
由于基本数据操作是围绕哈希和排序构建的,如何在机架级规模上进行这些操作吗?是否完全了解何时使用哪个?
-
考虑到每个核心现在可以访问比以前多一到两个数量级的内存,用来组织和索引数据的数据结构在这些新的规模下仍然有效吗?特别是,典型的数据结构是如何生成一致性流量的?考虑到无效消息可以支配访问时间,是否可以改进?
-
假设可以自由地使用大量资源来解决单个查询运算符,那么如何在相互竞争的查询中调度机器资源?
近数据处理
CXL控制器的部分计算能力可以用于执行近数据处理,如图3顶部。
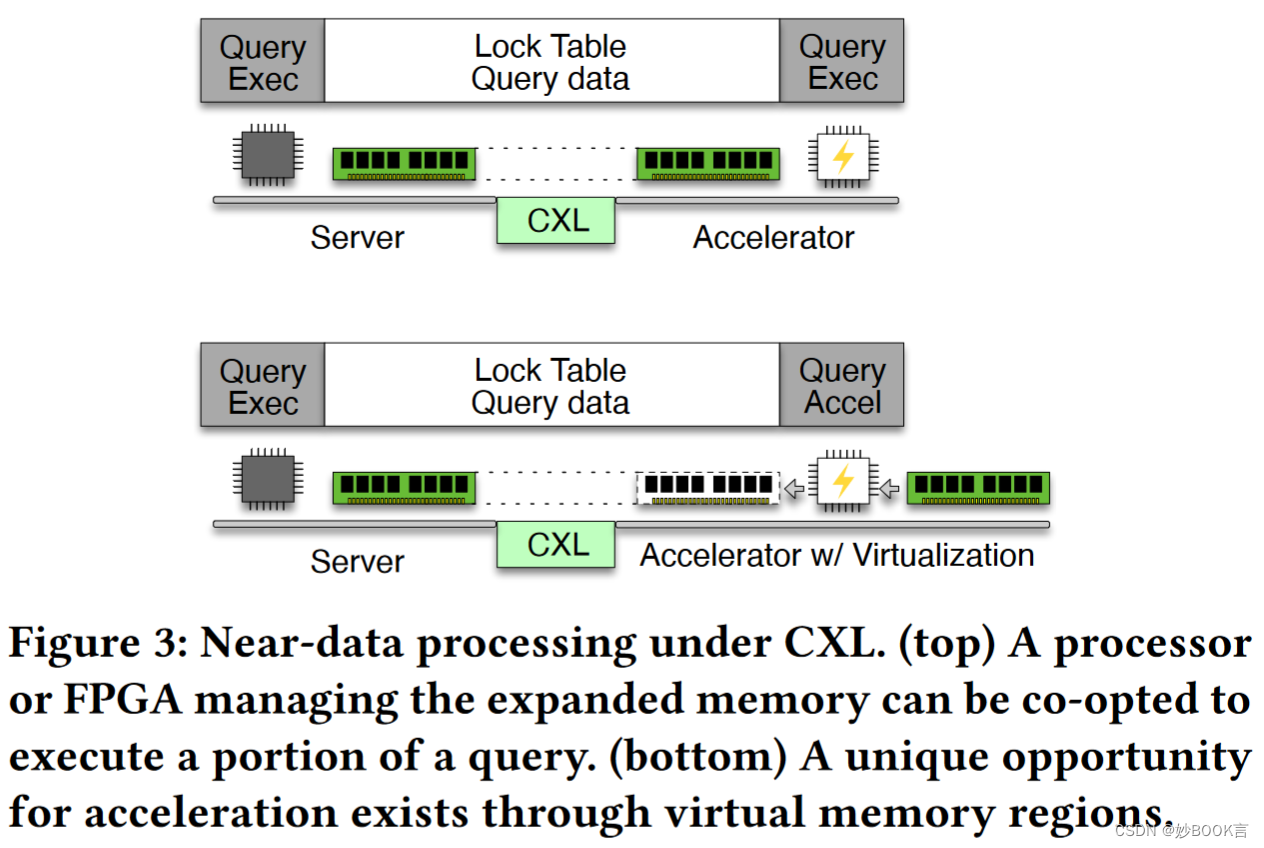
产生的挑战:
-
如何在数据附近进行查询处理?
-
是利用控制器来实现功能,还是在CXL路径中连接加速器?这样的控制器或加速器是什么样子的?
-
如果锁表也被放置在共享内存区域中,那么甚至可以从查询的两侧执行对公共数据结构的更新。什么是适合双方都可以操作的数据结构?
-
一个想法是使用CXL控制器来实现一个虚拟内存区域,该区域与实际内容不对应,而是与一个服务相对应,该服务从内存中获取数据并在将其发送给请求者之前对其进行转换,使其看起来一直存储在内存中。图3底部展示了这样一个用例。在数据库中,可以用于实现:动态视图;数据类型转换;从列到行、从行到列或矩阵的数据换位[16];动态数据立方体和统计摘要;集成数据库和智能存储系统[17]。
总结
对CXL在数据库领域的使用前景的分析,利用CXL带来的新功能,可以更好的实现内存扩展、分离式内存、近数据处理。文中提出了许多CXL带来的新问题,有待后续进行优化。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











