







 Ceph通过BlueStore解决本地文件系统限制,包括低效的事务、元数据性能差和新硬件支持慢的问题。BlueStore将元数据存储在RocksDB中,优化文件系统性能并支持向后不兼容的存储硬件。
Ceph通过BlueStore解决本地文件系统限制,包括低效的事务、元数据性能差和新硬件支持慢的问题。BlueStore将元数据存储在RocksDB中,优化文件系统性能并支持向后不兼容的存储硬件。
SOSP 2019 Paper 分布式元数据论文阅读笔记整理
问题
Ceph分布式文件系统在本地文件系统之上构建存储后端,这是当今大多数分布式文件系统的首选。原因有3点:
-
允许将数据持久性和块分配的难题委派给经过良好测试且具有高性能的代码。
-
提供了一个熟悉的接口(POSIX)和抽象(文件、目录)。
-
允许使用标准工具(ls,find)来探索磁盘内容。
挑战
分布式文件系统利用本地文件系统构建存储后端面临的挑战:
-
很难在现有文件系统之上实现高效的事务。大量工作旨在将事务引入文件系统[39,63,65,72,77,80,87106],但由于这些方法的性能开销高、功能有限、接口复杂性或实现复杂性,它们都没有被采用。其他选择,如利用文件系统的有限内部事务机制、在用户空间中实现预写日志记录或使用事务键值存储,也会带来较差的性能。
-
本地文件系统的元数据性能会显著影响整个分布式文件系统的性能。一个关键挑战是快速枚举具有数百万个条目的目录,以及返回结果缺乏排序。基于Btrfs和XFS的后端都遇到了这个问题,而且分配元数据负载的目录拆分操作与文件系统策略冲突,从而削弱了整体系统性能。
-
支持新兴存储硬件的速度非常缓慢。文件系统平均需要十年的时间才能适应新兴硬件。针对数据中心的新型存储硬件引入了向后不兼容的接口,需要进行剧烈的更改。例如,SMR 技术[38,62,82]使用向后不兼容的区域接口[46];ZNS SSD 消除了FTL,暴露了区域接口[9,26]。分布式文件系统由于在本地文件系统中延迟采用新设备而陷入停滞。
本文方法
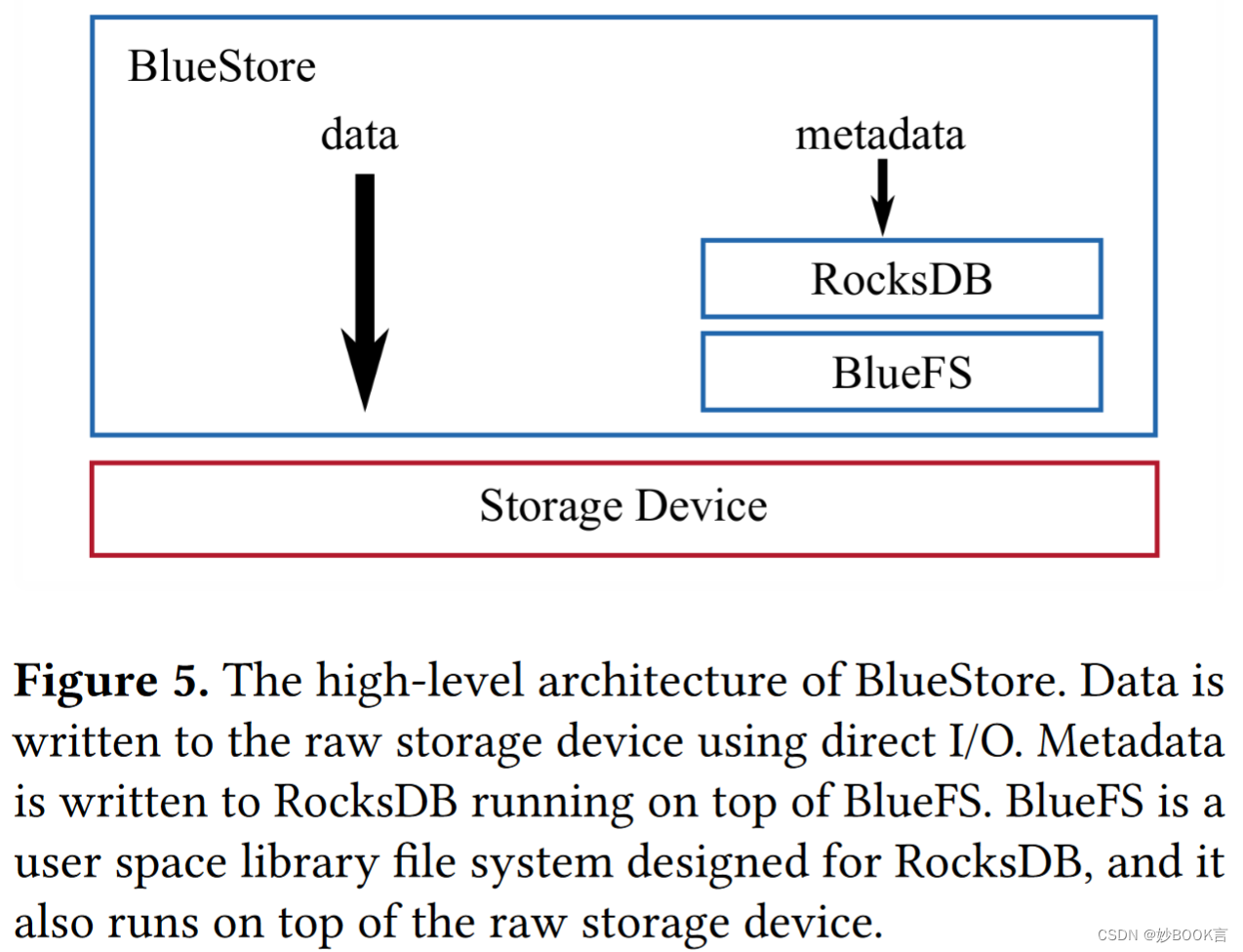
Ceph通过BlueStore解决了这些问题,BlueStore是用于直接在原始存储设备上运行的新后端。通过在用户空间中运行并完全控制I/O堆栈,实现了节省空间的元数据和数据校验和、擦除编码数据的快速覆盖、内联压缩、降低了性能可变性,并避免了本地文件系统的一系列性能陷阱。最后,它使采用向后不兼容的存储硬件成为可能,可以接受硬件多样性。
-
将低级文件系统元数据(如扩展位图)存储在键值存储中,从而避免了磁盘格式的更改,降低了实现的复杂性。
-
通过仔细的接口设计来优化克隆操作并最小化由此产生的扩展引用计数的开销。
-
BlueFS,一个用户空间文件系统,使RocksDB能够在原始存储设备上更快地运行。
-
空间分配器,其具有每TB磁盘空间固定的35MB存储器使用率。
总结
分布式文件系统通常使用本地文件系统作为存储后端,但受到本地文件系统的三个限制:事务机制不高效;元数据性能不足;支持新存储硬件速度慢。因此Ceph提出BlueStore,用于直接在原始存储设备上运行的新后端。包括4个工作:(1)将低级文件系统元数据(如扩展位图)存储在RocksDB中,从而避免了更改磁盘格式。(2)设计用户空间文件系统BlueFS,使RocksDB能够在原始存储设备上更快地运行。(3)通过接口设计来优化克隆操作,并最小化由此产生的扩展引用计数的开销。(4)空间分配器,其具有每TB磁盘空间固定的35MB存储器使用率。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











