







APPT 2024 Paper CXL论文阅读笔记整理
问题
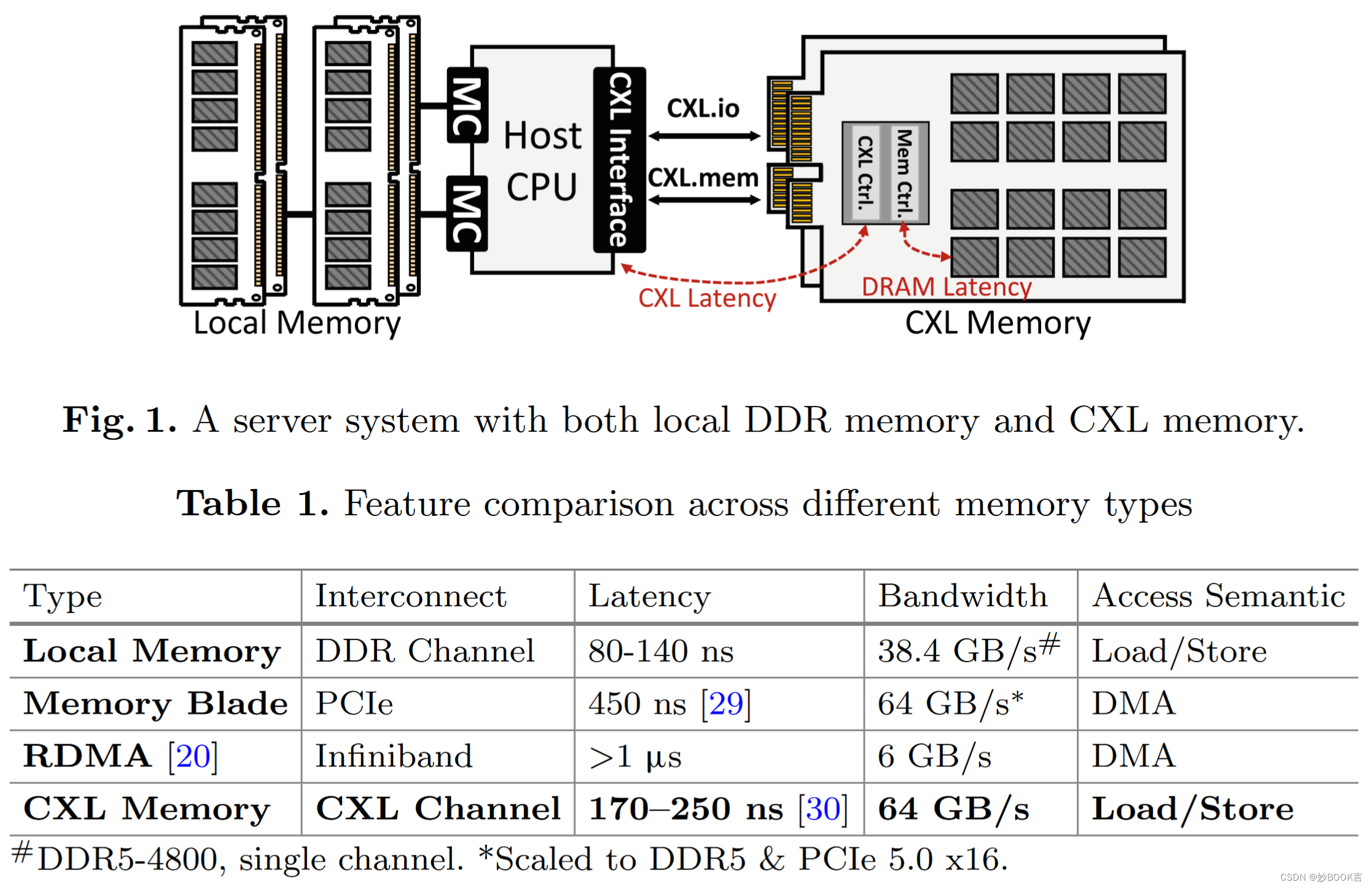
由于控制和传输开销,与本地内存相比,基于CXL的内存扩展器会增加延迟,并对延迟敏感的任务产生负面影响。虽然缓存预取可以减少内存延迟,但需要提高CPU预取覆盖率。然而,为CXL内存调整CPU预取器需要昂贵的CPU修改,并且可能导致缓存污染和内存带宽浪费。
本文方法
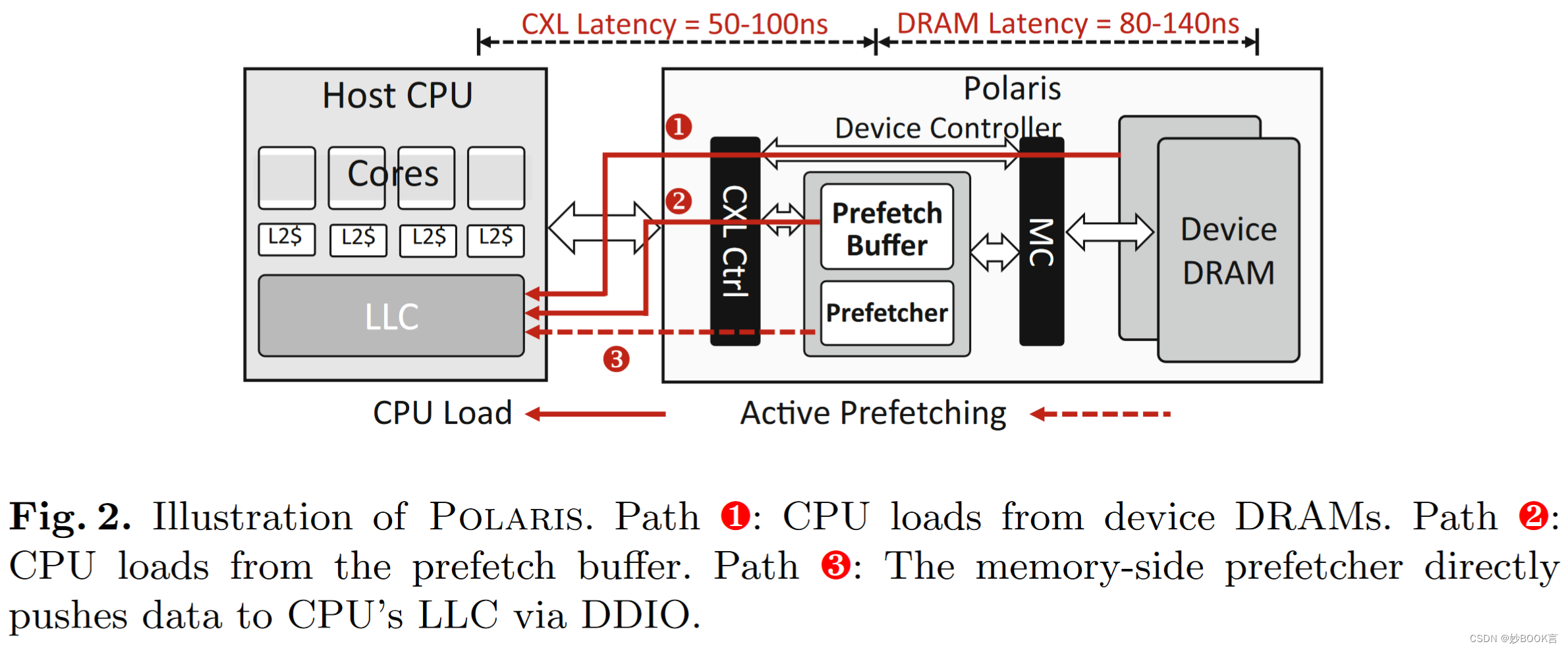
本文提出了Polaris,将硬件预取器集成到CXL内存控制器芯片中。
-
分析传入的内存请求,并将缓存行预取到专用SRAM缓冲区,而无需修改CPU或软件。
-
在预取命中时,从预取缓冲区中读取数据,大大缩小了CXL和本地DDR内存之间的性能差距。有几个优势:(1)硬件修改仅限于内存扩展器,有助于将兼容的方案引入现有的数据中心服务器。(2) 使用专用的预取缓冲区,可以在不污染CPU缓存的情况下,通过积极的预取,解锁比CPU预取器更多的预取覆盖范围。(3) 可以获得比CPU端更高的设备端DRAM带宽用于预取。(4) 与CPU侧预取器相比,独立芯片中的存储器侧预取机在复杂的预取器方面有更多的预算,以获得更高的预取精度。
-
如果允许对CPU进行更改,例如扩展Intel的数据直接IO(DDIO)。Polaris可以主动将高置信度预取推送到CPU的最后一级缓存(LLC),进一步减少CXL内存访问开销。
运行流程:
-
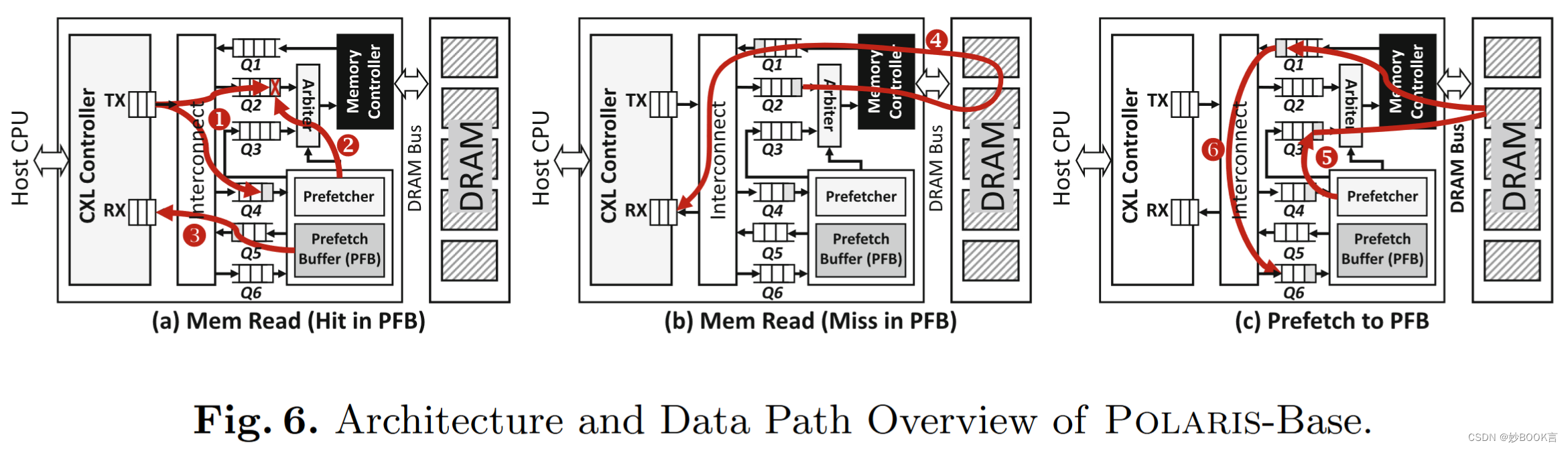
如图6(a),解码后的内存地址同时发送到Q2(正常读取队列)和Q4(PFB读取队列),即路径1。如果地址在PFB中命中,而同一请求仍在Q2中等待,则它将从Q2(路径2)中删除,以节省DRAM带宽。命中缓存线通过Q5(PFB返回队列)从PFB中读出,并发送回CXL控制器进行分组(路径3)。如果请求在PFB中命中,但其分支请求已被发送到内存控制器(不在Q2中),CXL控制器将两次接收同一缓存行,一次来自PFB,另一次来自DRAM,并直接丢弃后一个。
-
如果CPU读取请求在PFB中未命中,设备内存会像往常一样返回未命中的缓存行,如图6(b)中的路径4。存储器访问请求由存储器控制器提供服务,读取的数据通过Q1(DRAM返回队列)反馈到CXL控制器。
-
接收到的读取请求由预取器进行分析,如图6(c)所示。预取器获取Q4中存储的读取地址,分析并向存储器控制器发出预取请求。如路径5所示,要预取的缓存行地址被放入Q3(预取队列)。仲裁器调度来自Q2和Q3的请求,以保证正常的存储器读取具有更高的优先级。预取的数据通过PFB填充队列Q6(路径6)存储在PFB中。这些队列在逻辑上是分开的,其中一些可以在物理实现中合并。对于CPU写入,在收到内存写入请求时,Polaris会更新PFB(如果命中)和DRAM中的缓存行,以保持一致。
实验表明,结合各种CPU端预取器,Polaris能够有效地容忍高达85%的常见工作负载(平均43%)的CXL内存较长的延迟。
实验
实验环境:ChampSim模拟器
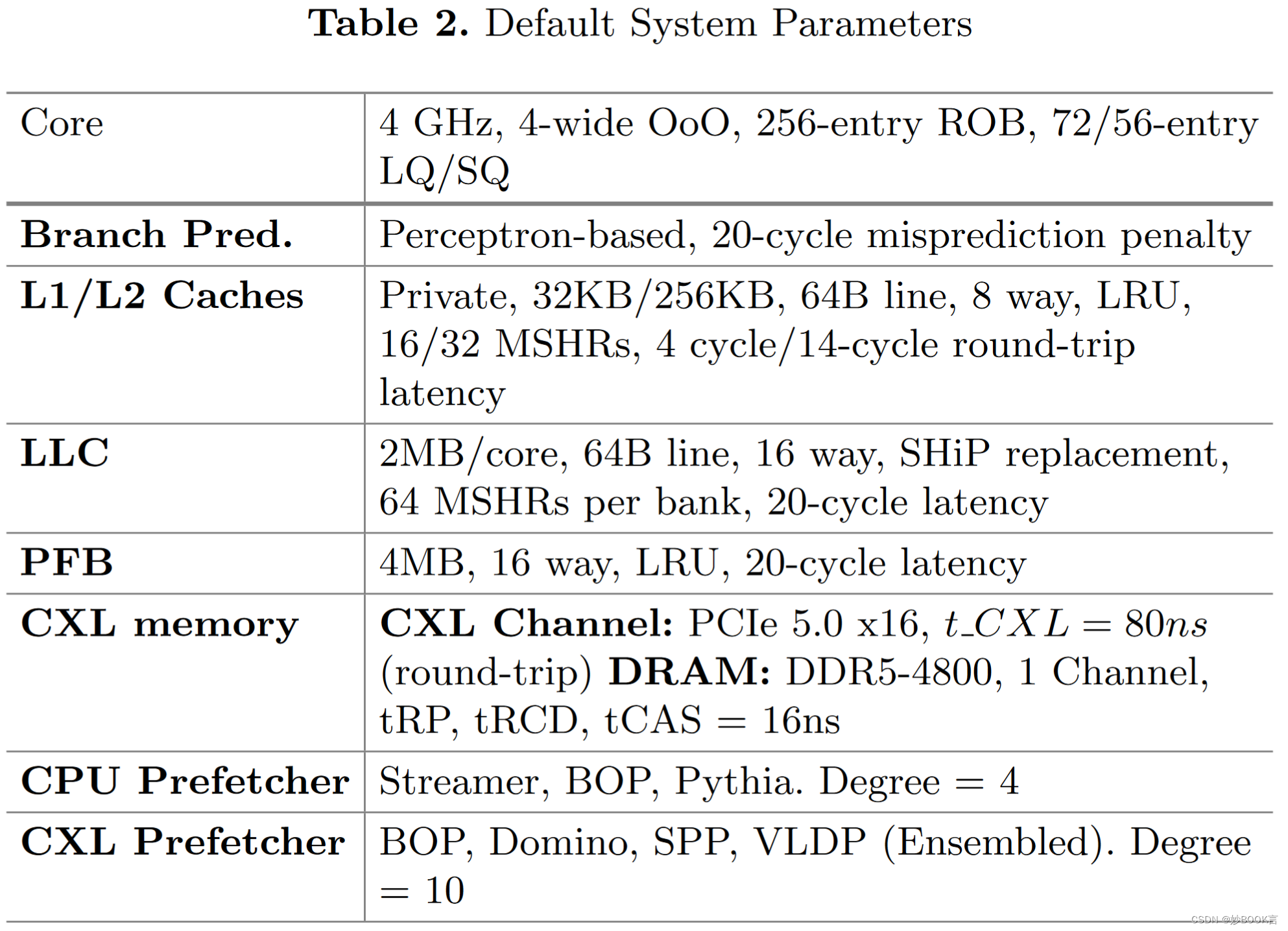
数据集:SPEC2006[21]、SPEC2017[14]、PARSEC-2.1[1]、GAPBS[8]

实验对比:减速比
总结
针对CXL内存的预取,本文提出Polaris,将硬件预取器集成到CXL内存控制器芯片中。在CXL中增加额外缓存区,将预取数据存入缓存区中,预取命中时降低CXL内存访问延迟。支持将预取结果主动推送到CPU的LLC,进一步降低延迟。
优势:(1)在硬件修改,兼容现有数据中心服务器;(2)避免预取污染CPU缓存,具有更大预取范围;(3)利用设备端DRAM带宽进行预取;(4)可以利用硬件性能实现更高预取精度。
















 793
793











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











