







问题
通过稀疏激活的专家混合物(MoE),可以很容易地将大规模模型扩展到万亿个参数,这显著提高了模型质量,同时只需要亚线性增加计算成本。与传统的密集层(针对每个输入进行计算)相比,MoE层由多个密集层(专家)组成,只有少数专家被动态激活以计算每个输入数据的输出[18]。因此,与密集模型相比,每个MoE层的专家人数为E人,模型大小可缩放至E倍,而且MoE的计算成本仅略大于密集模型。
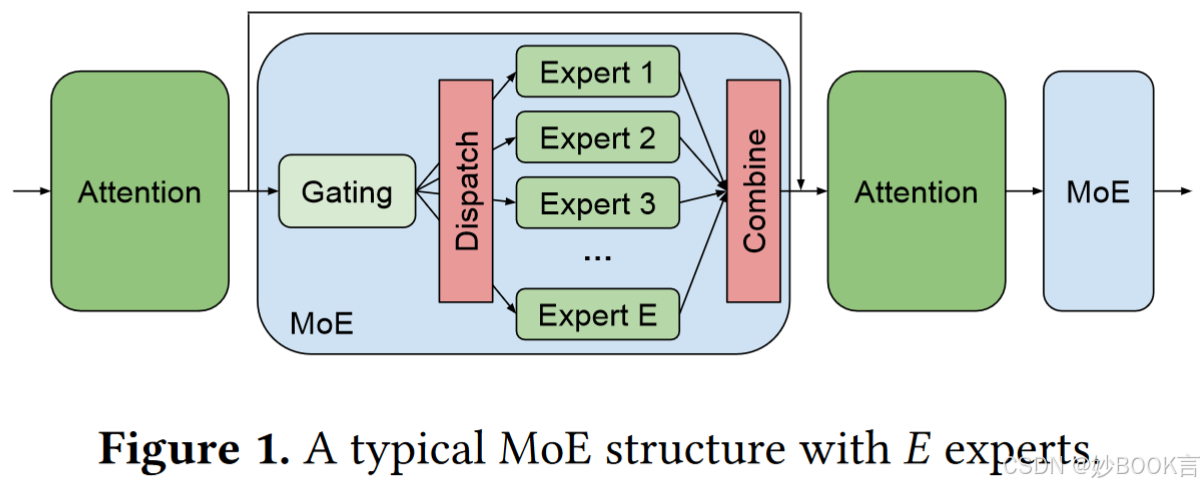
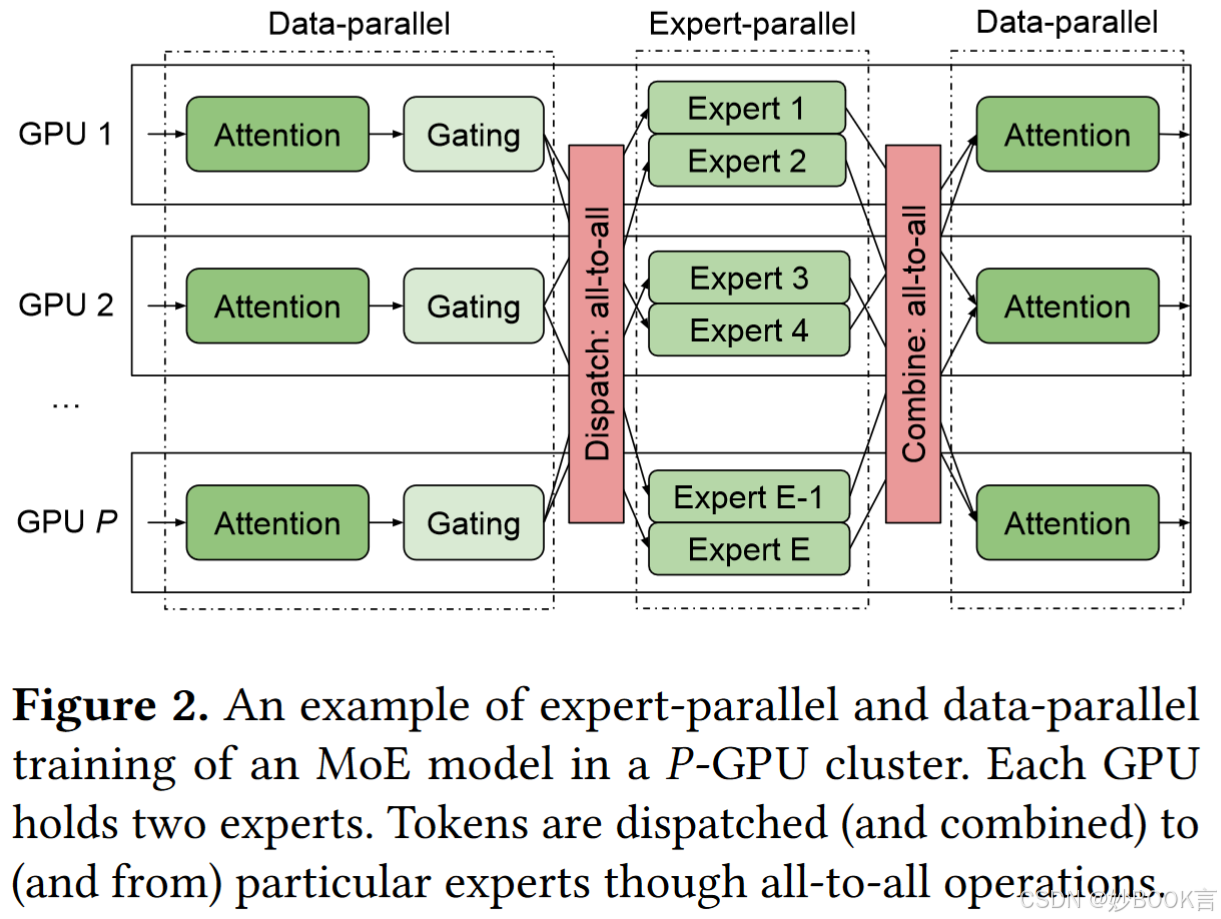
使用MoE训练模型时,MoE层的输入数据(例如,令牌)应动态地(每个小批量)路由到不同的专家进行计算,但当一个GPU无法存储所有专家时,专家可能位于不同的GPU上。因此输入数据应传输到特定的GPU,这通常由all-to-all(A2A)集体通信[7]来实现;然后通过另一个A2A操作(组合)收集位于不同GPU中的专家的结果[18]。A2A的通信时间对整体训练表现至关重要。如[16,18]所述,在大型TPU[18]或高端A100 GPU[16]上训练MoE模型需要大量的A2A通信时间,占总时间的40%-50%。更糟糕的是,A2A的通信时间随着令牌数量、专家数量、嵌入大小和GPU数量的增加而显著增加。
现有方法局限性
现有研究在三个正交方向上优化MoE模型的训练性能:
-
设计负载均衡路由函数[13,19,55],使分布式GPU的计算工作负载更加平衡。
-
设计高效的通信方法,包括通信效率高的1D或2D分层A2A算法[1,16,26,31,36]和数据压缩算法[52],以减少通信量。
-
设计任务调度算法[14,16,20,22,30],以交错通信任务和计算任务,从而隐藏通信成本。
在系统优化方面,后两个方向更适合提高分布式系统的扩展效率,同时保持MoE层的快速收敛特性,但它们仍然有几个局限性:
-
支持A2A操作中新设计的高效通信数据传输方法的可扩展性有限。
-
A2A算法在利用现代异构GPU集群上的内部和外部带宽方面的次优性。
-
交织计算任务和通信任务的调度算法的次优性。
本文方法
本文提出了一个可扩展且高效的MoE训练系统ScheMoE。
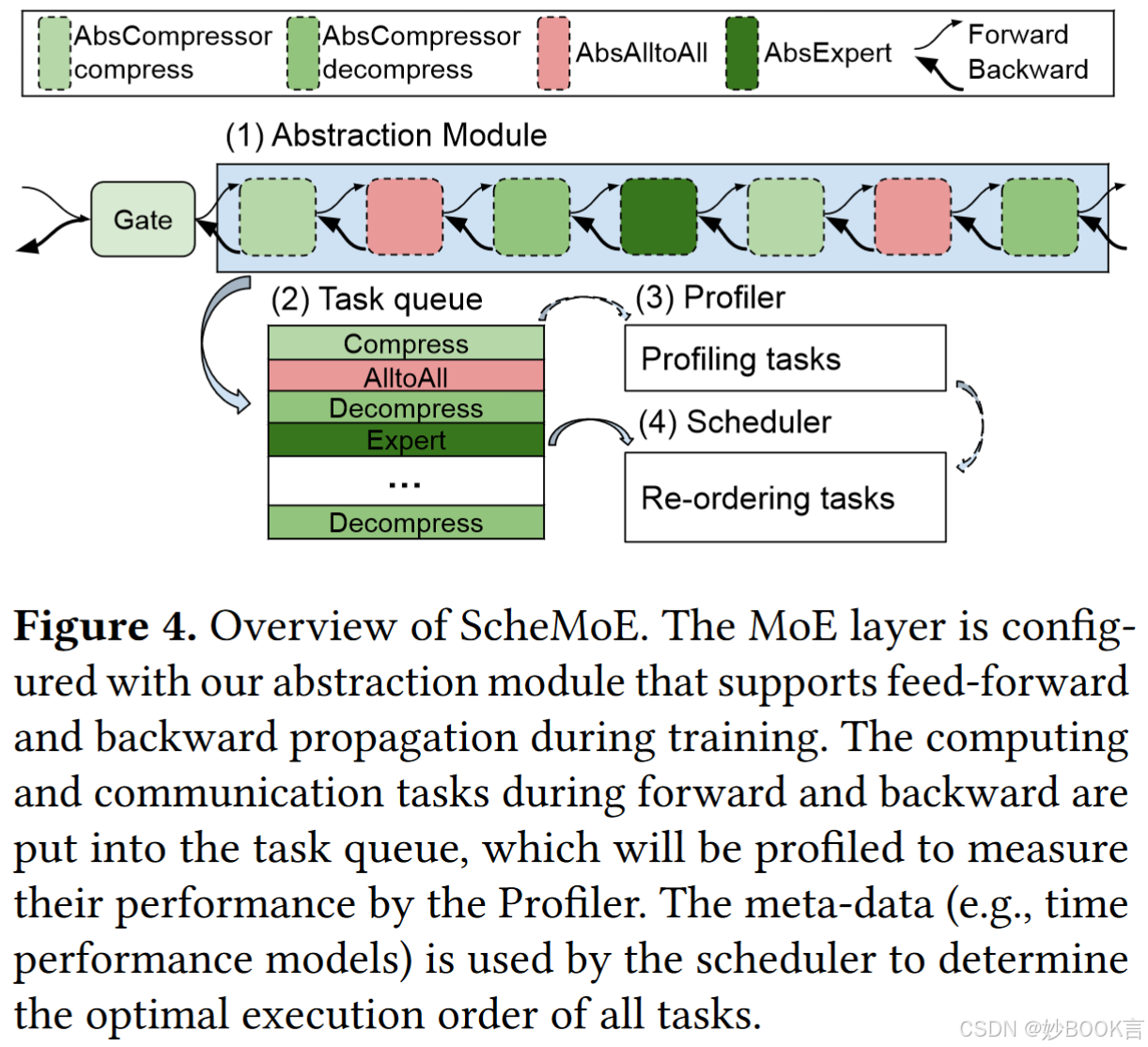
-
将耗时的操作模块化,包括数据压缩(一项计算任务)、集体通信(一项通信任务)和专家计算(一项计算机任务),以便使用新设计定制这些操作。
-
基于模块化操作,提出了一种自适应最优调度算法来处理通信和计算任务,以提高训练效率。
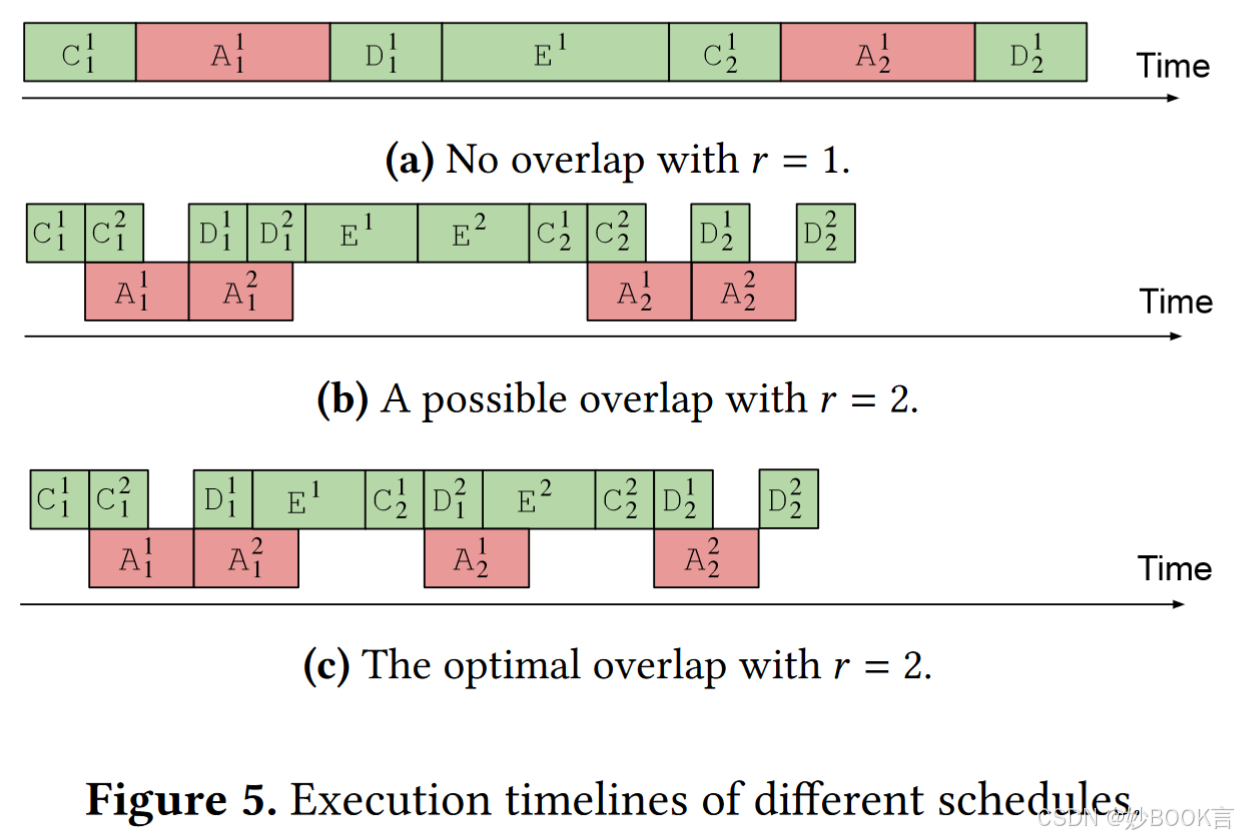
-
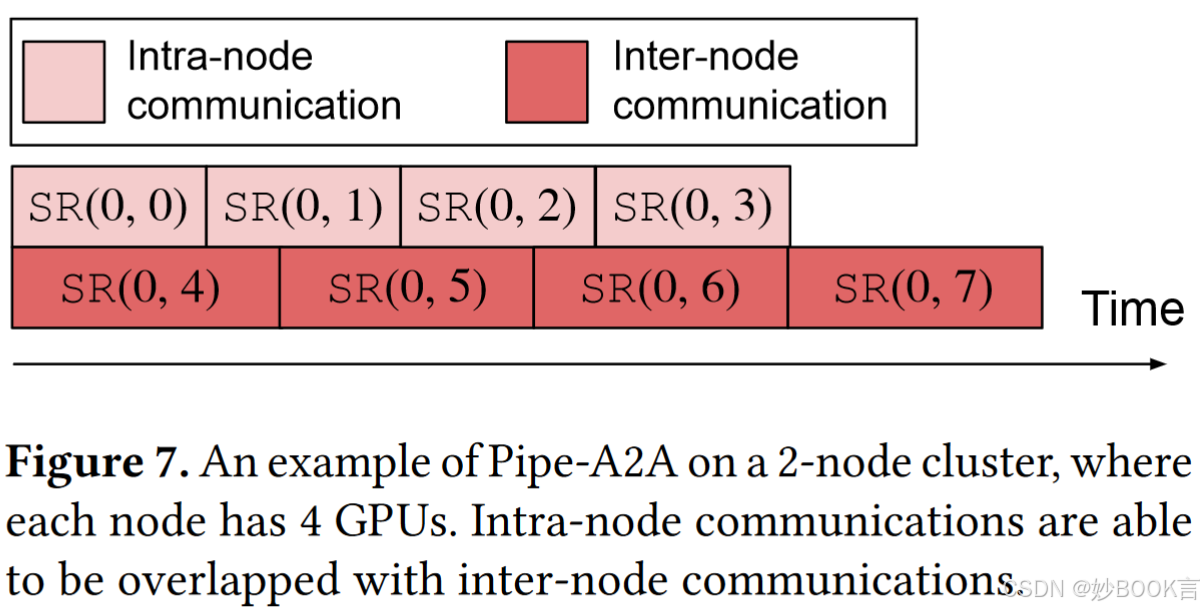
设计了一种新的A2A算法,即Pipe-A2A,对节点内通信和节点间通信进行流水线传输,同时利用节点内带宽和节点间带宽来提高通信效率。
在32-GPU集群上进行了广泛的实验,结果表明,ScheMoE比现有最先进的MoE系统Tutel和Faster MoE训练速度快9%-30%。
总结
针对模型训练的MoE层,现有方法受限于通信瓶颈和任务调度方法,在GPU集群上扩展性不佳。本文提出ScheMoE,包括3个创新点:(1)将操作模块化,包括数据压缩、集体通信和专家计算。(2)基于模块化操作,提出了一种自适应最优调度算法来处理通信和计算任务,以提高训练效率。(3)设计了新的A2A算法,即Pipe-A2A,对节点内通信和节点间通信进行流水线传输,同时利用节点内带宽和节点间带宽来提高通信效率。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











