







ISCA 2024 Paper CXL论文阅读笔记整理
问题
基于深度学习的推荐模型(DLRM)是当今最重要的互联网服务之一。训练和部署推荐模型的一个关键挑战是它们的高内存容量和带宽需求,例如嵌入层占用数百GB到TB的存储空间。这种嵌入层的特点是低计算强度和大量不规则的内存访问,因此,嵌入层训练依赖于具有大容量优化主内存的CPU[6]。然而,随着推荐系统模型尺寸的扩展速度超过内存容量,对内存资源的需求将很快超过单个服务器的限制[33]。
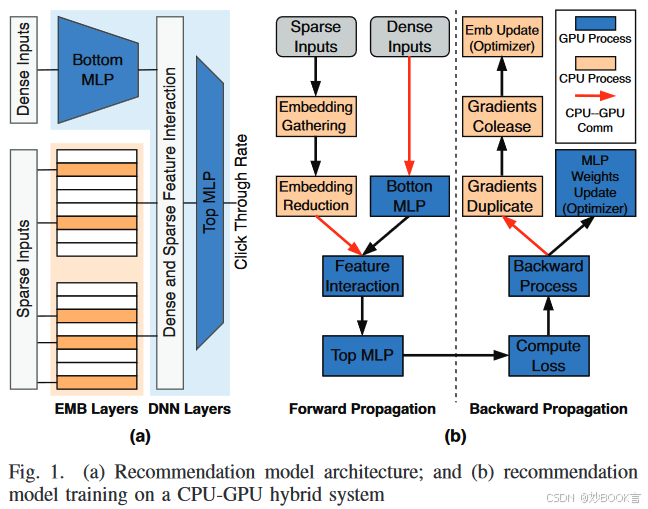
内存分解技术和Compute Express Link(CXL)的出现为内存容量扩展提供了一种有前景的解决方案。但是,将内存密集型嵌入层直接迁移到CXL内存会导致明显的性能下降,因为其传输带宽(例如,PCIe5.0×8为32GB/s)远低于主机内存带宽(例如,对于8通道DDR5-4800,速度超过300GB/s)。
近内存处理(NMP)是解决内存墙问题的一种有前景的解决方案[16、48、50],通过在设备内集成处理单元,将低计算密集型操作直接卸载到内存中[11、35、40、41、54]。这种方法有两个好处
-
在内存中处理嵌入缩减操作,仅将结果传输回主机,大大减少了内存和主机之间的数据移动。
-
利用内存级并行性(如ranhk级或bank级)来提高内部内存带宽的利用率。
本文方法
本文提出了ReCXL,一个基于CXL的内存分解系统,利用近内存处理(NMP)进行可扩展、高效的推荐模型训练。
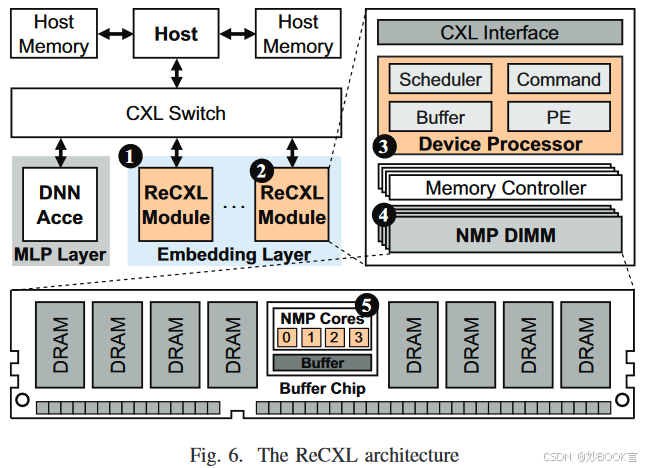
-
设计为CXL设备,将大量设备内存分割成一个池,可以很容易地用其他设备进行扩展,从而促进灵活和按需的内存扩展。
-
在嵌入训练过程中实现了统一的rank级NMP架构,包括前向传递和反向传播。通过利用内存级并行性,最大限度地减少了带宽受限的CXL链路上的数据移动,并增强了池内的内部内存带宽。
-
结合了两种软硬件协同优化:无依赖预取和细粒度更新调度。在ReCXL设备的空闲期间预取和调度即将到来的训练批次的输入,最大限度地提高硬件利用率并显著提高性能。
评估结果显示,ReCXL的性能分别比CPU-GPU基线和原始CXL内存高出7.1-10.6倍(平均9.4倍)和12.7-31.3倍(平均22.6倍)。
总结
针对推荐模型对内存需求过高的问题,利用CXL和近内存处理可以有效缓解推荐模型的嵌入层训练。本文提出了ReCXL,结合CXL和近内存计算(NMP)优化推荐模型训练。包括3个技术:(1)统一NMP架构,在CXL内存中集成了NMP单元,在前向和反向传播中减少传输数据量。(2)无依赖预取,在硬件空闲时提前预取下一批次数据。(3)细粒度调度,优化嵌入向量更新顺序,减少等待时间。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











