







问题
缓存可以有效地减少请求延迟和网络流量,驱逐策略是其中的核心组件。驱逐策略的性能通常使用两个关键指标来衡量:(1)对象未命中率,反映缓存未命中的请求比例;(2)字节未命中率,反映缓存丢失的数据量。
现有方法的局限性
为了降低未命中率,已经提出了各种启发式驱逐策略[14,15,32,45,53,56,67,84,87],基于学习的策略[20,37,39,50,62,64,65,73,79,80]。但基于学习会带来的大量计算开销,限制了它们在生产系统中的部署。
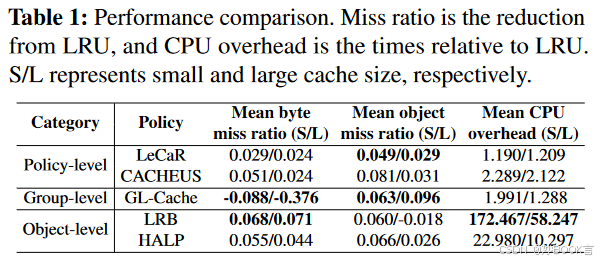
基于学习的驱逐分为三类。
-
策略级:例如,LeCaR[73],CACHEUS[62]。使用强化学习直接做出驱逐决定。但未命中率受到强化学习对工作量变化的延迟适应的显著影响。
-
组级:例如,GL Cache[80]。将相似的对象聚类到组中,在组级执行学习和驱逐,大大降低了计算开销。但由于分组方法和组定义的限制,该类别只在部分跟踪上表现良好。
-
对象级:例如,LRB[64],HALP[65],Raven[37],Parrot[50]。对每个对象进行训练和预测。通过预测重用距离,模仿Belady MIN算法[19],在缓存的所有对象中驱逐未来请求最远的对象。
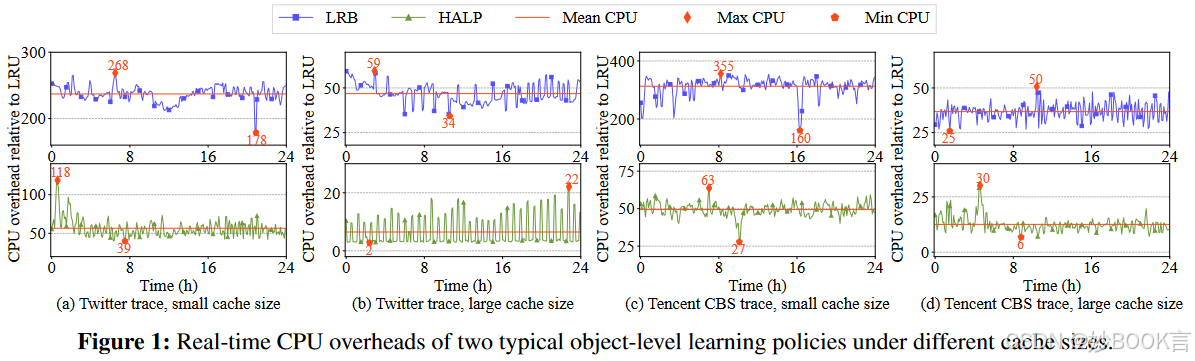
虽然对象级学习可以实现最低的未命中率,但训练和预测的开销约占总开销的70%。缓存大小小时,预测是主要开销;缓存大小大时,训练是主要开销。

要对其进行优化面临3个挑战:
-
如何在不影响模型准确性的情况下减少训练开销浪费?在一定程度上降低训练频率只会略微影响未命中率,并显著降低计算开销。
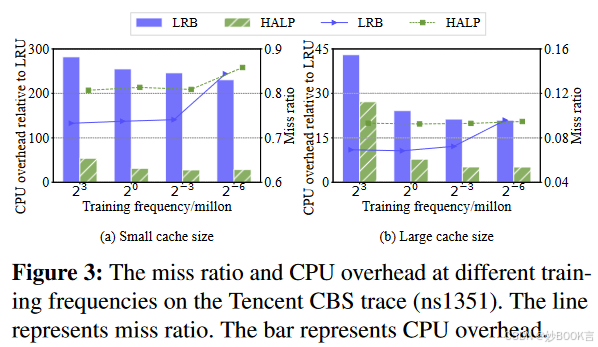
-
如何在不牺牲未命中率的情况下减少预测开销?如何对不受欢迎的对象进行采样,如何从候选对象中选择被驱逐的对象。
-
如何提高泛化能力?在保持低计算开销的同时提高通用性,确保始终保持良好的性能。
本文方法
本文提出了3L Cache,一种具有低计算开销的对象级学习策略,同时实现了低对象缺失率和低的字节缺失率。
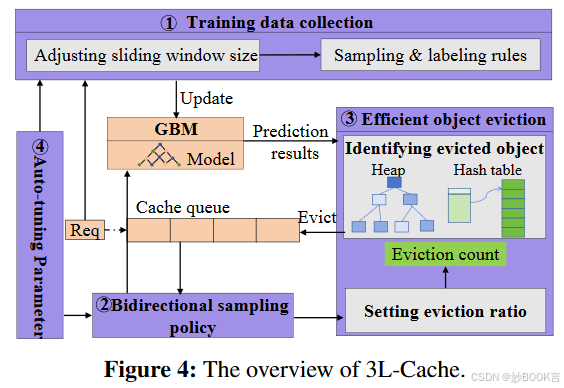
-
提出了一种高效的训练数据收集方案。动态滑动窗口,过滤掉不必要的历史缓存请求。当窗口中未缓存对象的训练数据不足1% 时,增加窗口大小;当未缓存对象的训练数据比例过高时,缩小窗口大小。采样策略,只在窗口中采样同时避免重复采样。动态调整训练频率,使用GBM进行训练。
-
设计了一种低开销的驱逐策略。集成了双向采样策略,从缓存队列的头部和尾部采样,来优先考虑不受欢迎的对象。集成了高效的驱逐策略,利用最大堆(max heap)和哈希表存储预测结果,每次淘汰预测下次访问时间最长的对象。
-
采用参数自动调整方法来增强跨轨迹的适应性,调整窗口大小、采样范围、采样比例、新对象缓存比例等。
开源代码:GitHub - optiq-lab/3L-Cache
使用4855条迹线评估3L Cache。结果表明,3L Cache的平均CPU开销与HALP相比降低了60.9%,与LRB相比降低了94.9%。对于小缓存大小,3L Cache的平均开销仅为LRU的6.4倍,对于大缓存大小,其平均开销为3.4倍。在十二种最先进的策略中实现了最佳的字节丢失率或对象丢失率。
总结
针对基于学习的缓存策略,现有方法受限于计算开销高、对象未命中率高、字节未命中率高。本文提出3L Cache,包括3个技术:(1)训练数据收集方案:动态滑动窗口,过滤掉不必要的历史缓存请求。采样策略,只在窗口中采样同时避免重复采样。动态调整训练频率,使用GBM进行训练。(2)驱逐策略:双向采样策略,从缓存队列的头部和尾部采样。驱逐策略,利用最大堆和哈希表存储预测结果,每次淘汰预测下次访问时间最长的对象。(3)参数自动调整。调整窗口大小、采样范围、采样比例、新对象缓存比例等。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











