







1、线程间的内存同步模型
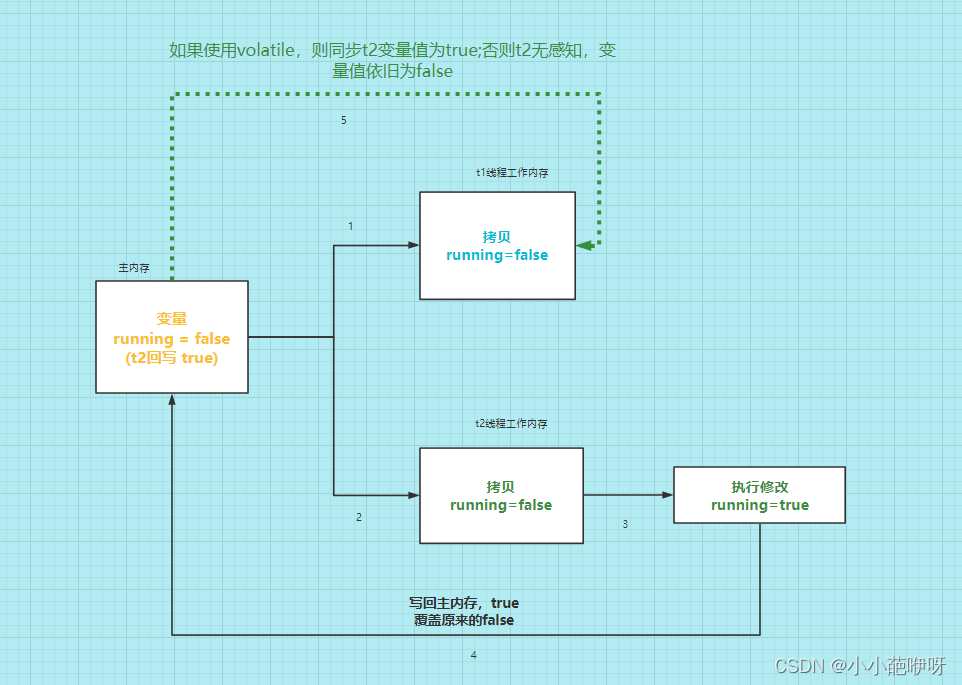
2、volatile修饰变量,保证变量在线程之间的可见性,以下示例是使用volatile的情况
package com.yang.Threads;
import java.util.concurrent.TimeUnit;
/**
* @Author: Gy
* @Description: 测试线程之间的可见性
* @Date
* @Modified By:
*/
public class TestVolatile {
private static volatile boolean running = false;
public static void main(String[] args) throws InterruptedException {
childThread1();
TimeUnit.SECONDS.sleep(2);
childThread2();
}
public static void childThread1(){
Thread t1 = new Thread(() -> {
System.out.println("t1 start");
while (!running) {
// System.out.println("t1 go on");
}
System.out.println("t1 has been stoped");
});
t1.start();
}
public static void childThread2(){
Thread t2 = new Thread(() -> {
running = true;
});
t2.start();
}
}
实践后可得出结论,线程t2修改了running = true后,线程t1能够正常停止,说明t1工作内存中的running变量被同步更新了;相反如果不适用volatile修饰running变量,t2修改变量值后,仅仅刷新了主内存中的值,t1中的变量值不能同步更新,所以t1一直运行,不能停止。
3、在不使用volatile的情况下,使用线程的某些阻塞方法(如sleep())和唤醒方法以及system.out.println中的synchronized关键字都会触发变量在线程之间的可见性,也就是内存同步的操作
package com.yang.Threads;
import java.util.concurrent.TimeUnit;
/**
* @Author: Gy
* @Description: 测试线程之间的可见性
* @Date
* @Modified By:
*/
public class TestVolatile {
private static boolean running = false;
public static void main(String[] args) throws InterruptedException {
childThread1();
TimeUnit.SECONDS.sleep(2);
childThread2();
}
public static void childThread1(){
Thread t1 = new Thread(() -> {
System.out.println("t1 start");
while (!running) {
System.out.println("t1 go on");
}
System.out.println("t1 has been stoped");
});
t1.start();
}
public static void childThread2(){
Thread t2 = new Thread(() -> {
running = true;
});
t2.start();
}
}
此示例中,因为t1的while循环内部有System.out.println(“t1 go on”),而这句底层包含synchronized关键字,所以触发了线程之间的内存同步,t1的工作内存中也是可以获取最新值的,所以线程t1可以正常停止。那么我们是不是就可以利用这个特性来实现线程之间的可见性呢?答案是否定的,试想一下,sout相当于是加锁操作,势必会导致程序的执行效率,所以该用volatile就用volatile。
4、volatile修改引用类型,只能保证引用本身的可见性,不能保证该引用内部字段的可见性,示例如下
package com.yang.Threads;
import java.util.concurrent.TimeUnit;
/**
* @Author: Gy
* @Description: volatile修饰引用类型(Inner的引用),该引用中的字段改变不能触发可见性(除非修改该引用的地址值,如新建一个引用赋值给该引用
* @Date
* @Modified By:
*/
public class TestVolatile3 {
private static class Inner{
boolean running = true;
void inner_m(){
System.out.println("inner_m start");
while (running){
}
System.out.println("inner_m stop");
}
}
private volatile static Inner inner = new Inner();
public static void main(String[] args) throws InterruptedException {
new Thread(inner::inner_m,"t1").start();
TimeUnit.SECONDS.sleep(2);
inner.running = false;
}
}
上边示例,子线程t1不能停止,如果要引用的内部字段可见,可用volatile直接修饰引用类型内部字段,示例如下
package com.yang.Threads;
import java.util.concurrent.TimeUnit;
/**
* @Author: Gy
* @Description: volatile直接修饰引用类型的内部字段,实现内部字段在线程之间的可见性(即内存同步)
* @Date
* @Modified By:
*/
public class TestVolatile3 {
private static class Inner{
volatile boolean running = true;
void inner_m(){
System.out.println("inner_m start");
while (running){
}
System.out.println("inner_m stop");
}
}
private static Inner inner = new Inner();
public static void main(String[] args) throws InterruptedException {
new Thread(inner::inner_m,"t1").start();
TimeUnit.SECONDS.sleep(2);
inner.running = false;
}
}
此时,线程t1可以正常停止。
5、三级缓存及线程之间变量的可见性

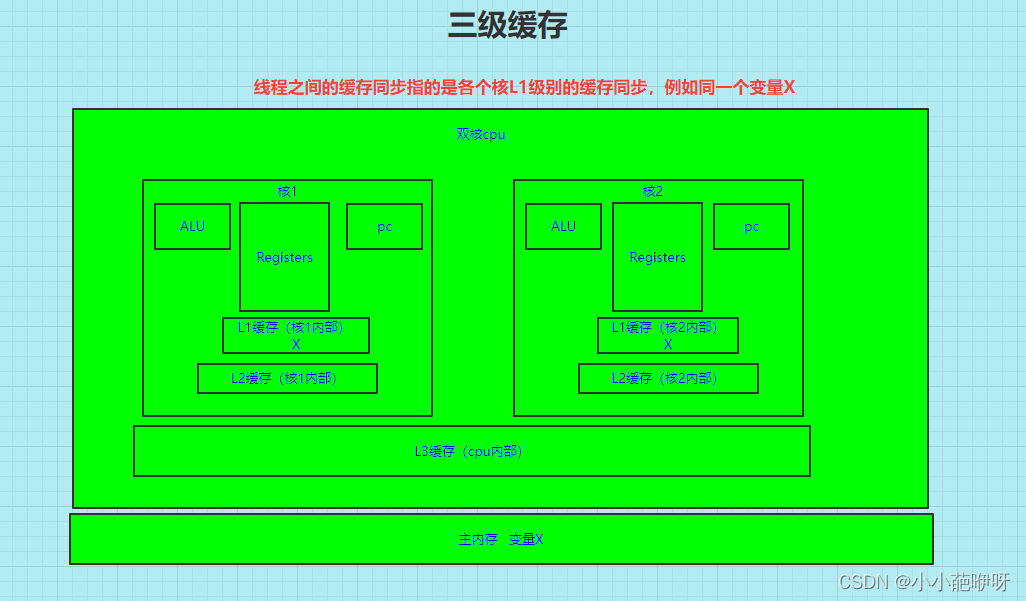
接下来,借用一个实例,引入缓存行(cache line)的概念,假如现在有个小程序,我们需要从主内存中读取变量x(int类型4个字节长度),那么这个变量是依次被缓存进L3->L2->L1中的吗?那么一万个变量呢?也是一个一个的被逐级缓存进去的吗?答案是否定的,事实上,变量的读取是按块读取的,这个块也就是一个缓存行(大小是64个字节长度),所以每次都是读取一个缓存行,并不是一个变量一个变量的存进缓存,相当于每次都是批量读取的,有利于提高效率。当线程读取x变量的时候,也会把x附近的y变量一同放进缓存,见下图
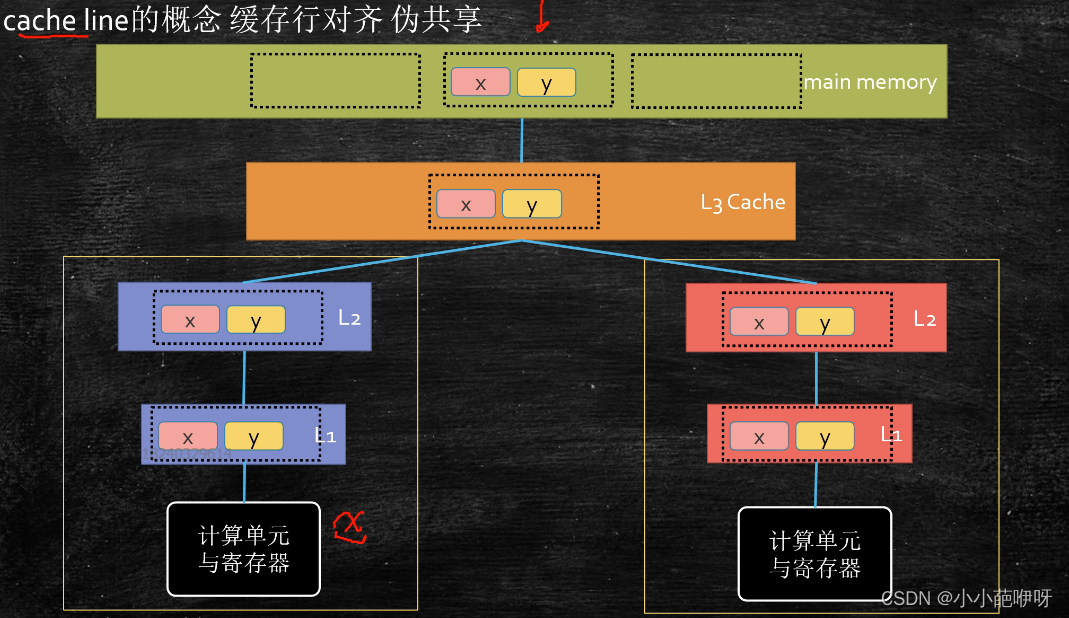
下面通过两个小程序认识缓存行
程序一
package com.yang.Threads;
import java.util.concurrent.CountDownLatch;
/**
* @Author: Gy
* @Description:
* @Date
* @Modified By:
*/
public class TestCacheline {
private static long COUNT = 1000000000L;
private static class T{
// private long a,b,c,d,e,f,g;
private long h = 0L;
// private long i,j,k,l,m,n,o;
}
public static T[] array = new T[2];
static {
array[0] = new T();
array[1] = new T();
}
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(2);
Thread t1 = new Thread(() -> {
for (long i = 0; i < COUNT; i++) {
array[0].h = i;
}
countDownLatch.countDown();
});
final Thread t2 = new Thread(()->{
for (long i = 0; i < COUNT ; i++) {
array[1].h = i;
}
countDownLatch.countDown();
});
final long startTime = System.nanoTime();
t1.start();
t2.start();
countDownLatch.await();
System.out.println((System.nanoTime()-startTime)/1000000);
}
}
该程序的执行时间为335毫秒。
程序二,释放掉程序一中注释的变量
package com.yang.Threads;
import java.util.concurrent.CountDownLatch;
/**
* @Author: Gy
* @Description:
* @Date
* @Modified By:
*/
public class TestCacheline {
private static long COUNT = 1000000000L;
private static class T{
private long a,b,c,d,e,f,g;
private long h = 0L;
private long i,j,k,l,m,n,o;
}
public static T[] array = new T[2];
static {
array[0] = new T();
array[1] = new T();
}
public static void main(String[] args) throws InterruptedException {
CountDownLatch countDownLatch = new CountDownLatch(2);
Thread t1 = new Thread(() -> {
for (long i = 0; i < COUNT; i++) {
array[0].h = i;
}
countDownLatch.countDown();
});
final Thread t2 = new Thread(()->{
for (long i = 0; i < COUNT ; i++) {
array[1].h = i;
}
countDownLatch.countDown();
});
final long startTime = System.nanoTime();
t1.start();
t2.start();
countDownLatch.await();
System.out.println((System.nanoTime()-startTime)/1000000);
}
}
执行时间为291毫秒。
可以明显看出,程序二的执行效率更高,节省的时间是同一个缓存行数据同步的时间。先分析程序一,array数组中包含T1和T2两个对象,每个对象各包含一个长度为8个字节的变量,两个对象的长度分别比8个字节稍微大一点,总体小于64个字节,所以这俩对象大概率会出现在一个缓存行之中,当线程t1修改T1时,t1的L1缓存中包含T1和T2(前面说了T1和T2位于同一个缓存行),当t2线程修改T2时,t2的L1缓存中也包含T1和T2,也就是说,两个线程中要修改的变量存在同一个缓存行中,而这个缓存行有时两个线程L1缓存中共有的,所以根据缓存行的一致性协议(cpu硬件层面约定的缓存一致性),当t1线程修改L1缓存中T1的h属性时,会同步t2的L1缓存中T1做出修改从而保持一致。整个过程的图解见下图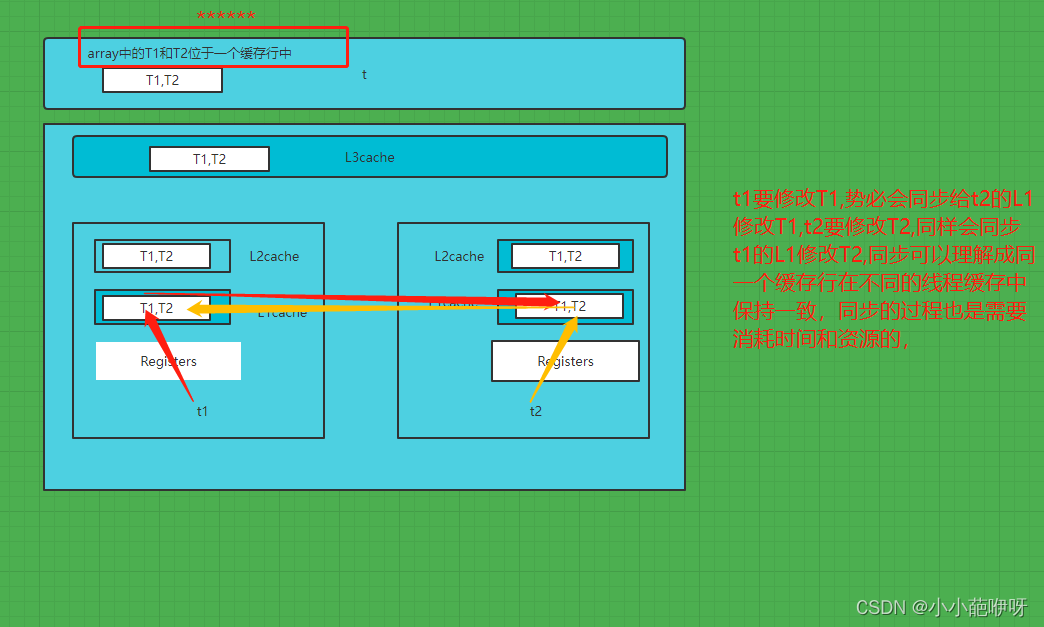
再分析程序二节省了时间的原因,程序二中在变量h前后分别填充了7个long类型的变量,所以T1和T2不可能在同一个缓存行中,所以t1和t2线程修改各自的变量的时候不涉及缓存行的同步过程,所以节省了时间,看下图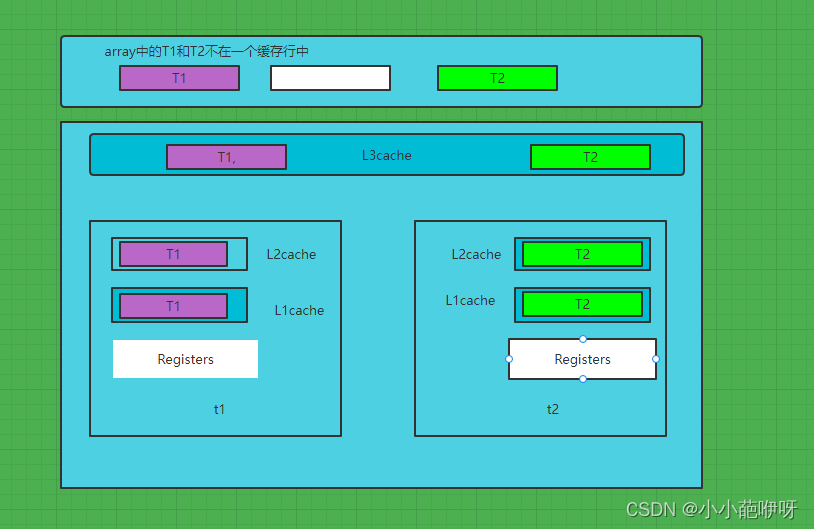
自此结束,以上内容是我学习后输出的成果,如果内容有错误,希望指教更正















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









