







引言
随着深度学习在各个领域的迅速发展,情感计算逐渐成为人工智能的重要研究方向。在现实场景中,情感信息往往由多种模态(如文本、图像、音频)共同表达。如何充分利用不同模态中的互补信息,实现更高准确率和更强鲁棒性的情感识别,成为当前亟待解决的问题。
本文介绍的项目正是针对这一问题展开研究:“基于自监督神经符号混合模型的跨模态情感认知”。该模型结合了自监督学习、跨模态特征融合以及符号推理机制,通过无监督数据预训练和有监督微调两大阶段,最终实现高效、可解释的情感分类。
在下文中,我们将详细解析项目的设计思路、系统架构、关键代码实现、训练与调优策略,并通过丰富的可视化结果展示实验效果。
一、项目背景与研究动机
1.1 多模态情感识别的必要性
传统情感识别主要依赖单一数据源,如文本情感分析或图像情感检测。但在实际应用中,例如社交媒体评论、在线视频和语音对话中,情感信息往往是多模态交织的。仅依靠单一模态的信息,模型容易丢失关键信息,导致识别效果受限。
1.2 自监督学习与神经符号混合模型的优势
-
自监督学习:
自监督学习通过设计伪标签任务(如自编码、对比学习等),充分利用大量无标注数据,能够学习到更通用、更鲁棒的特征表示。这对于多模态数据尤其重要,因为各模态之间往往存在潜在关联,但标注数据十分有限。 -
神经符号混合模型:
纯神经网络虽然在大规模数据中表现优异,但其“黑盒”特性使得决策过程缺乏可解释性。符号推理模块可以在一定程度上补充这一不足:将基于规则的知识注入到模型中,不仅能对结果进行校正,还能为模型决策提供解释。神经网络负责从数据中自动学习特征,而符号模块则利用先验规则对结果进行“二次判断”,使整个系统更健壮。
二、系统架构概览
本项目主要分为两个阶段:
-
自监督预训练阶段
利用大量无标签数据,对文本、图像和音频三种模态分别训练自编码器,并设计了跨模态对比损失,拉近同一数据中各模态的特征距离。该阶段主要目的是获得高质量的模态编码器参数。 -
微调阶段
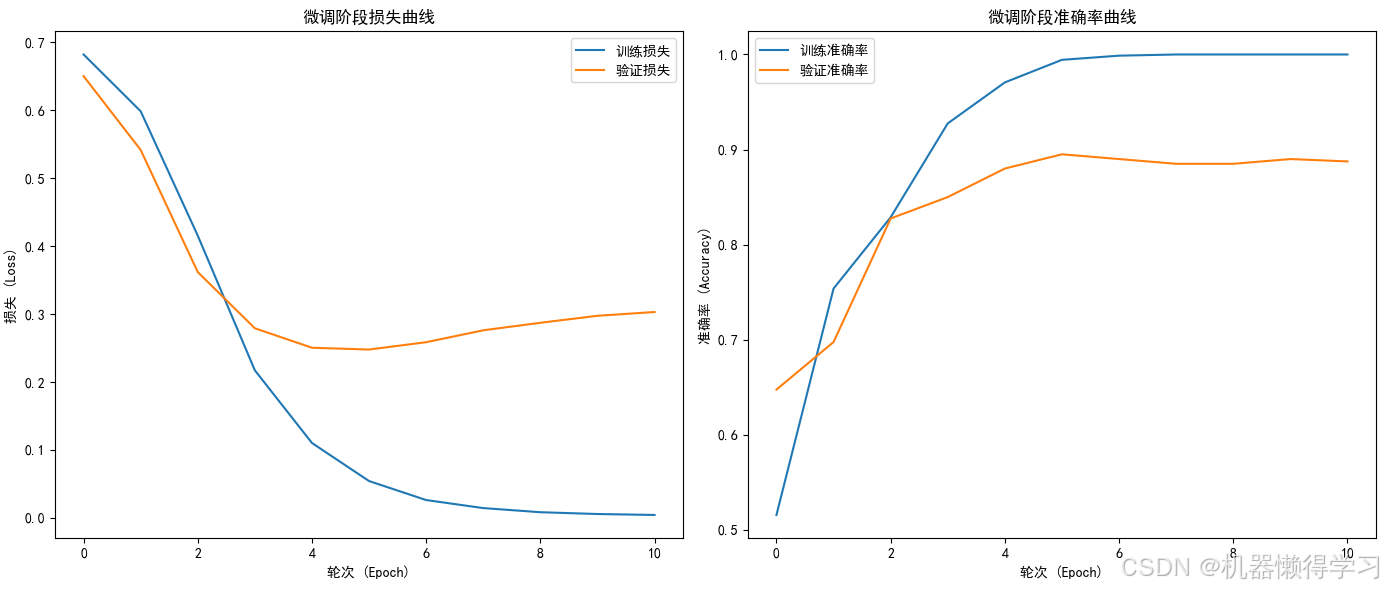
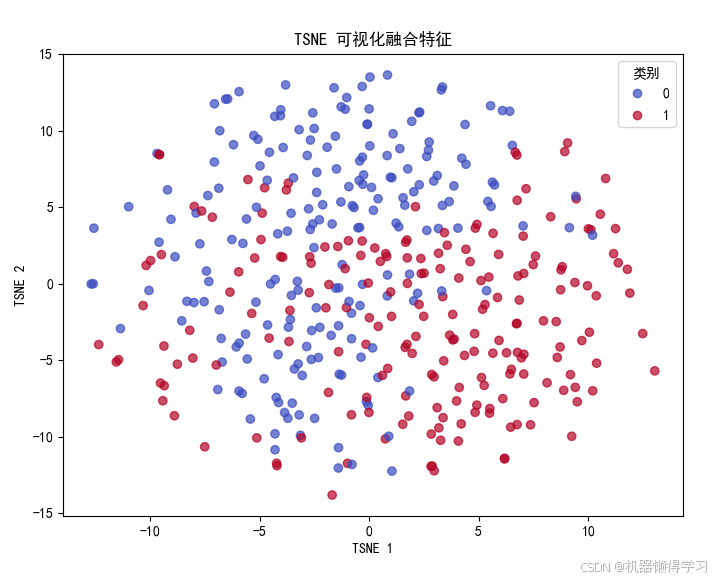
固定预训练好的编码器(或仅对编码器进行微调),构建融合分类器,将各模态的特征进行拼接,再结合符号推理规则进行情感分类。在此阶段引入了学习率调度、早停机制,并使用 TensorBoard 记录训练过程。
下图描述了整个系统的主要流程(注:图示仅为文字描述,实际可以使用流程图工具绘制):
+----------------+
| 数据预处理 |
+----------------+
│
▼
+--------------------------------+
| 自监督预训练阶段(无标签数据) |
+--------------------------------+
| 文本/图像/音频自编码器训练 |
| 跨模态对比损失联合反向传播 |
+--------------------------------+
│
▼
+--------------------------------+
| 微调阶段(有标签数据) |
+--------------------------------+
| 融合分类器 & 编码器微调 |
| 符号规则调整(解释性增强) |
+--------------------------------+
│
▼
+--------------------------------+
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









