










kafka
kafka, 是一种高吞吐率, 多分区, 多副本, 基于发布订阅的分布式消息系统, 支持海量数据传递
- 高吞吐量, 低延迟: 每秒可以处理几十万条消息, 延迟最低只有几毫秒, 每个主题可以分多个分区, 消费组可对不同分区进行操作
- 可扩展性: 集群支持热扩展
- 持久化, 可靠性: 消息被持久化到本地磁盘, 且支持数据备份防止丢失
- 容错性: 允许集群中节点失败(若副本数量为n, 则允许n-1个节点失败)
- 高并发: 支持数千个客户端同时读写
安装与部署
- 下载安装包 (前提已安装 JDK)
cd /usr/local
wget https://archive.apache.org/dist/kafka/3.0.1/kafka_2.13-3.0.1.tgz
- 解压
tar -zxvf kafka_2.13-3.0.1.tgz
- 启动zookeeper
由于kafka是基于zookeeper做集群节点维护和管理的, 会把节点信息存到zk中, 所以要先启动zookeeper, kafka有自带的zookeeper
cd kafka3.0.1/
# 修改zookeeper配置文件
vim ./config/zookeeper.properties
# 修改数据持久化存储路径
dataDir=/opt/tmp/zookeeper
# 保存并退出
启动zk
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
- 启动kafka
修改kafka配置文件
vim ./config/server0.properties
# 搭建集群时的唯一标识
broker.id=0
# 部署的机器 IP 和对外提供服务的端口, 默认9092
#listeners=PLAINTEXT://:9092
# 修改数据文件路径
log.dirs=/opt/kafka/kafka-logs
# 连接 zookeeper
zookeeper.connect=192.168.10.100:2181
# 保存并退出
启动
./bin/kafka-server-start.sh -daemon ./config/server.properties
- 客户端登录zk, 查看节点信息
./bin/zookeeper-shell.sh 47.98.100.76:2181 ls /
# 查看kafka节点
./bin/zookeeper-shell.sh 47.98.100.76:2181 ls /brokers/ids/0
实现
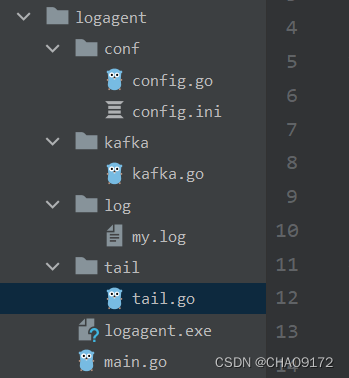
conf 为配置文件目录
- config.ini
[kafka]
addr=192.168.100.76:9092
topic=chao2022
[tail]
filename=./log/my.log
- config.go
配置文件结构体, 将配置文件信息映射到该结构体, 方便获取值
package conf
type Cfg struct {
KafkaCfg `ini:"kafka"`
TailCfg `ini:"tail"`
}
type KafkaCfg struct {
Addr string `ini:"addr"`
Topic string `ini:"topic"`
}
type TailCfg struct {
Filename string `ini:"filename"`
}
kafka 专门往kafka写数据的模块
- kafka.go
package kafka
import (
"fmt"
"github.com/Shopify/sarama"
)
var (
producer sarama.SyncProducer
err error
)
// Init 初始化 client
func Init(addr []string) error {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll
config.Producer.Partitioner = sarama.NewHashPartitioner // 设置选择分区的策略为Hash
config.Producer.Return.Successes = true // 成功交付的消息将在success channel返回
// 生产者
producer, err = sarama.NewSyncProducer(addr, config)
if err != nil {
return err
}
return nil
}
func SendMsg(topic, key, value string) error {
// 构造一个消息
msg := &sarama.ProducerMessage{}
msg.Topic = topic // 指定主题Topic
msg.Value = sarama.StringEncoder(value) // 消息内容
msg.Key = sarama.StringEncoder(key) // 设置key
// 分区ID, 偏移量
pid, offset, err := producer.SendMessage(msg)
if err != nil {
fmt.Println("send msg failed, err:", err)
return err
}
fmt.Printf("pid:%v offset:%v\n", pid, offset)
return nil
}
producer设置ack参数
- WaitForLocal: 消息同步到master之后返回ack信号,否则抛异常使应用程序感知到并在业务中进行重试发送。这种方式一定程度保证了消息的可靠性,producer等待broker确认信号的时延也不高。
- WaitForAll: 消息同步到master且同步到所有follower之后返回ack信号,否则抛异常使应用程序感知到并在业务中进行重试发送。这样设置,在更大程度上保证了消息的可靠性,缺点是producer等待broker确认信号的时延比较高。
订阅kafka的消费者如何按照消息顺序写入mysql, Kafka的消息在一个partition中是有序的,所以只要确保发给某个人的消息都在同一个partition中即可
- 全局一个partition, 这个最简单,但是在kafka中一个partition对应一个线程,所以这种模型下Kafka的吞吐是个问题。
- 多个partition手动指定, 生产消息的时候,除了Topic和Value,我们可以通过手动指定partition,比如总共有10个分区,我们根据用户ID取余,这样发给同一个用户的消息,每次都到1个partition里面去了,消费者写入mysql中的时候,自然也是有序的。但是,因为分区总数是写死的,万一Kafka的分区数要调整呢?那不得重新编译代码?所以这个方式不够优美。
- 多个partition自动计算, kafka客户端为我们提供了这种支持。在初始化的时候,设置选择分区的策略为Hash, 然后在生成消息之前,设置消息的Key值, Kafka客户端会根据Key进行Hash,我们通过把接收用户ID作为Key,这样就能让所有发给某个人的消息落到同一个分区了,也就有序了。
tail 读取日志文件的模块
package tail
import (
"github.com/hpcloud/tail"
)
var (
tailObj *tail.Tail
)
// Init 初始化
func Init(path string) error {
cfg := tail.Config{
ReOpen: true, // 重新打开, 在单个日志文件写满做切隔时, 重新打开新一个文件
Follow: true, // 是否跟随
Location: &tail.SeekInfo{ // 从文件的哪个位置开始读
Offset: 0,
Whence: 2,
},
MustExist: false,
Poll: true,
}
t, err := tail.TailFile(path, cfg)
if err != nil {
return err
}
tailObj = t
return nil
}
func Read() chan *tail.Line{
return tailObj.Lines
}
main
package main
import (
"fmt"
"logagent/conf"
"logagent/kafka"
"logagent/tail"
"gopkg.in/ini.v1"
"time"
)
var (
cfg conf.Cfg
err error
)
func main() {
// 0. 初始化配置文件
err = ini.MapTo(&cfg, "./conf/config.ini")
if err != nil {
fmt.Println("init config failed: ", err.Error())
return
}
// 1. 初始化kafka连接
addr := []string{cfg.KafkaCfg.Addr}
err = kafka.Init(addr)
if err != nil {
fmt.Println("init kafka failed: ", err.Error())
return
}
fmt.Println("init kafka success.")
// 2. 打开日志文件读取
filename := cfg.TailCfg.Filename
err = tail.Init(filename)
if err != nil {
fmt.Println("init tail failed: ", err.Error())
return
}
fmt.Println("init tail success.")
// 3. 执行
run()
}
func run() {
topic := cfg.KafkaCfg.Topic
key := "long"
// 将日志发送到kafka
for {
select {
case line := <-tail.Read():
// 有日志写入kafka
err = kafka.SendMsg(topic, key, line.Text)
if err != nil {
fmt.Println("kafka send failed: ", err.Error())
}
default:
time.Sleep(time.Second)
}
}
}
- 首先要初始化配置文件, 解析.ini文件, 并将数据映射到结构体
- 初始化kafka, 创建连接, 得到一个生产者
- 初始化读取文件
- 循环读取日志, 并发送到kafka中
效果
编译启动
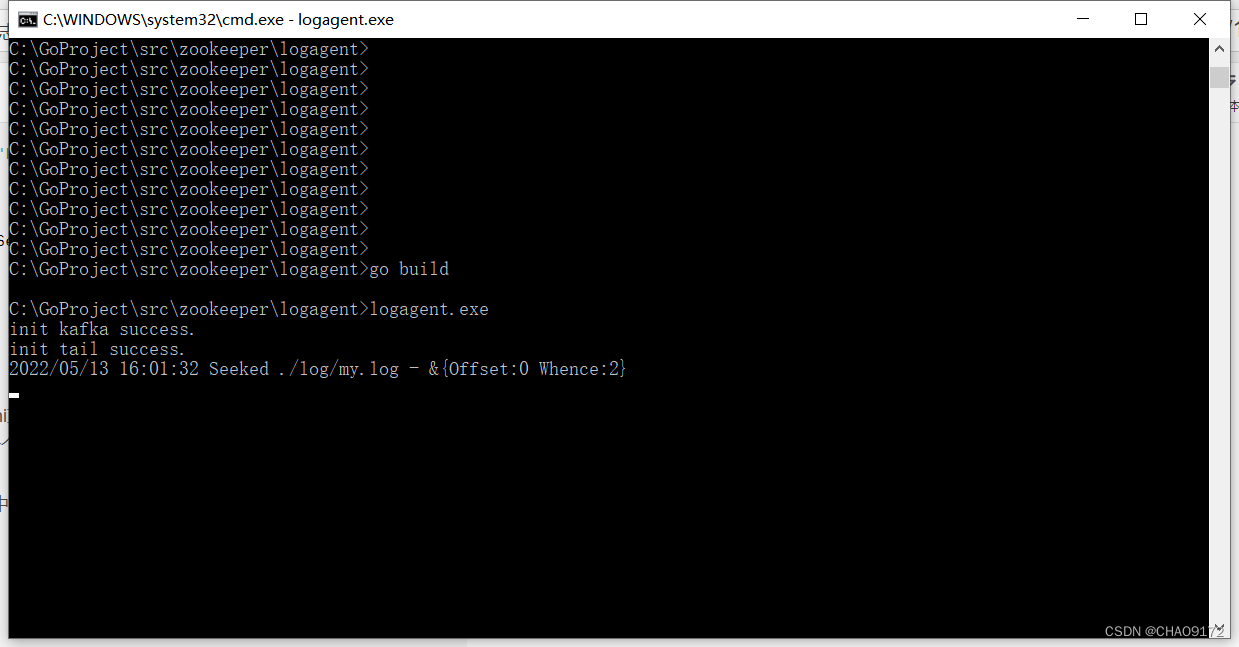
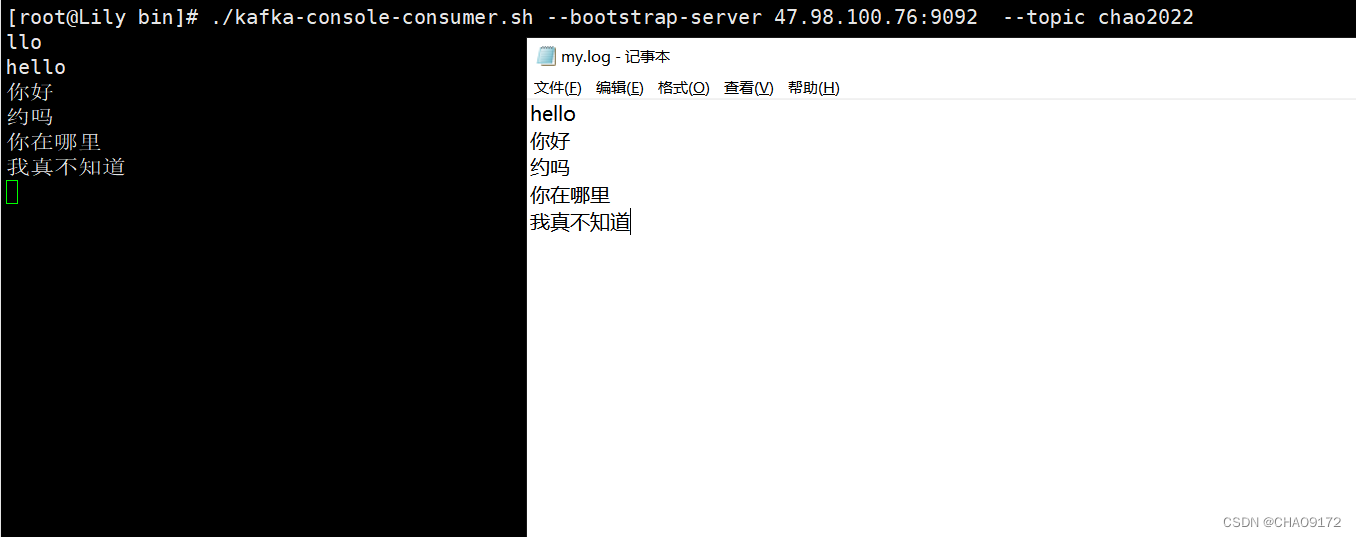
利用kafka终端工具, 开启一个消费者
./kafka-console-consumer.sh --bootstrap-server 192.168.100.76:9092 --from-beginning --topic chao2022
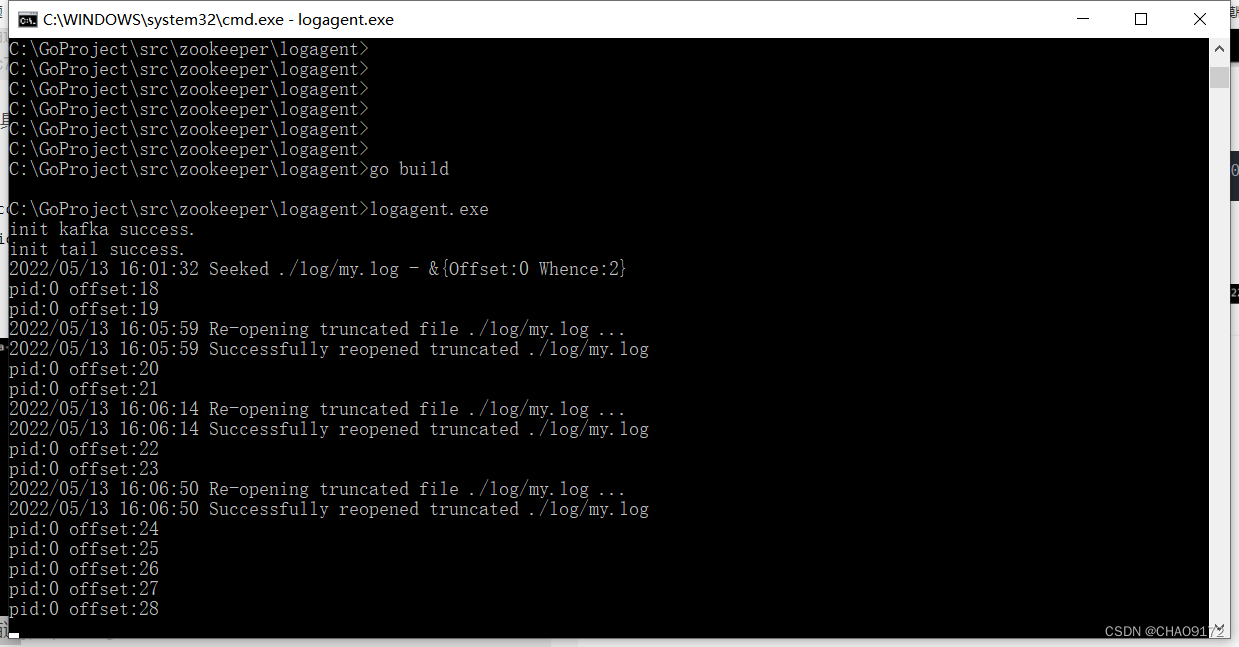
写入日志到my.log
















 1739
1739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











