








文章目录
前言:翻自己博客 发现缺少mysql数据结构和索引相关内容
两年前整理的mysql知识点 一直存在于博主的笔记本里面
(是的 纸质的那种笔记本 不是程序员吃饭用的笔记本)
二叉树
二叉树特点 小数在左 大数在右
如下图 (鼠标不太方便画图 将就着看吧 能看懂就行):
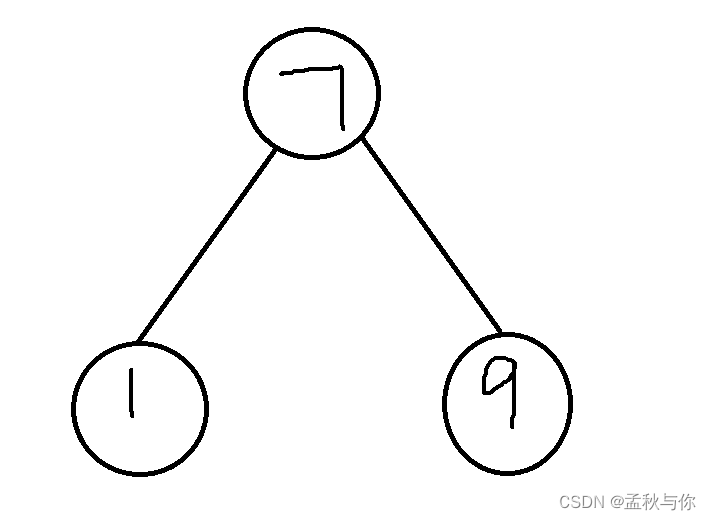
当数据不规律的时候 二叉树就会变化成链表 ,所以MySQL放弃二叉树
如下图 : (具体的数字单纯是博主方便鼠标好画 随意举例的)
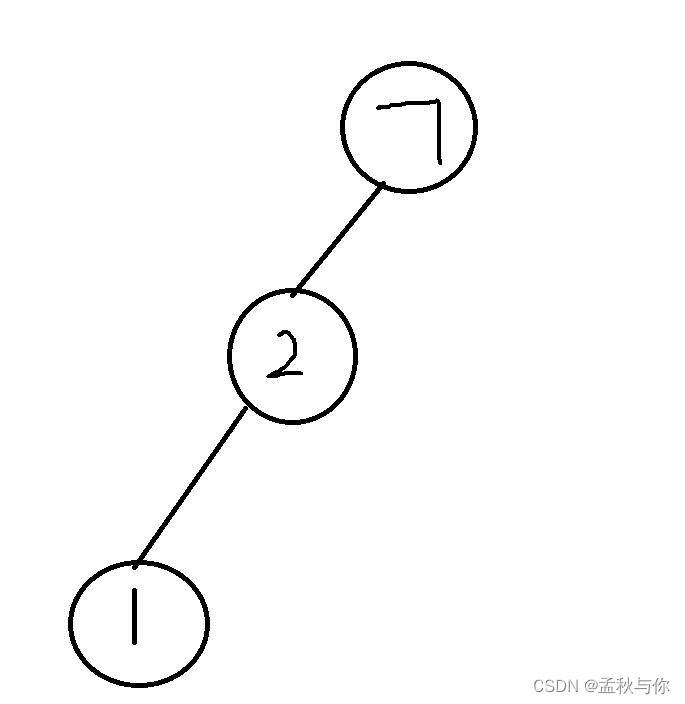
红黑树
红黑树也叫平衡二叉树,会自动旋转
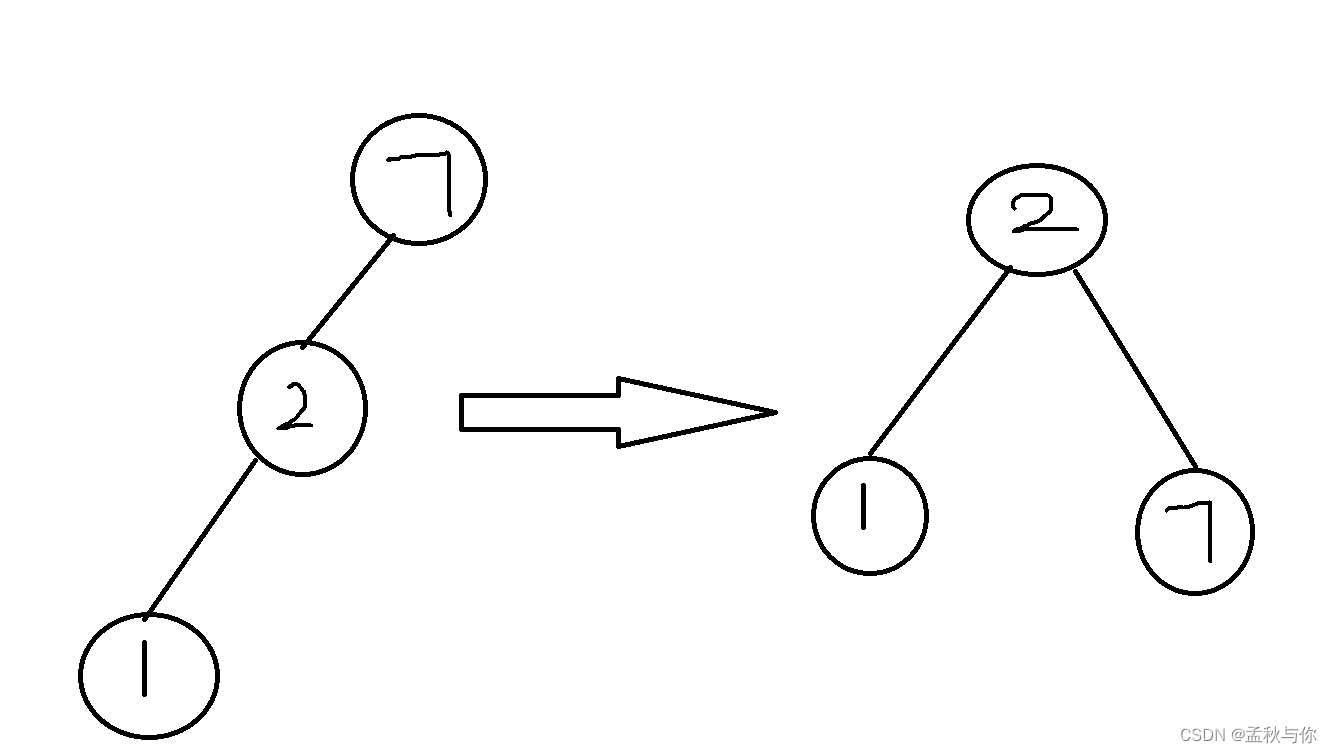
那既然会自动旋转了,解决了变成链表的问题 会不会有其它问题呢?答案是肯定的,当数据量大的时候,树的高度就会增加,如下图:
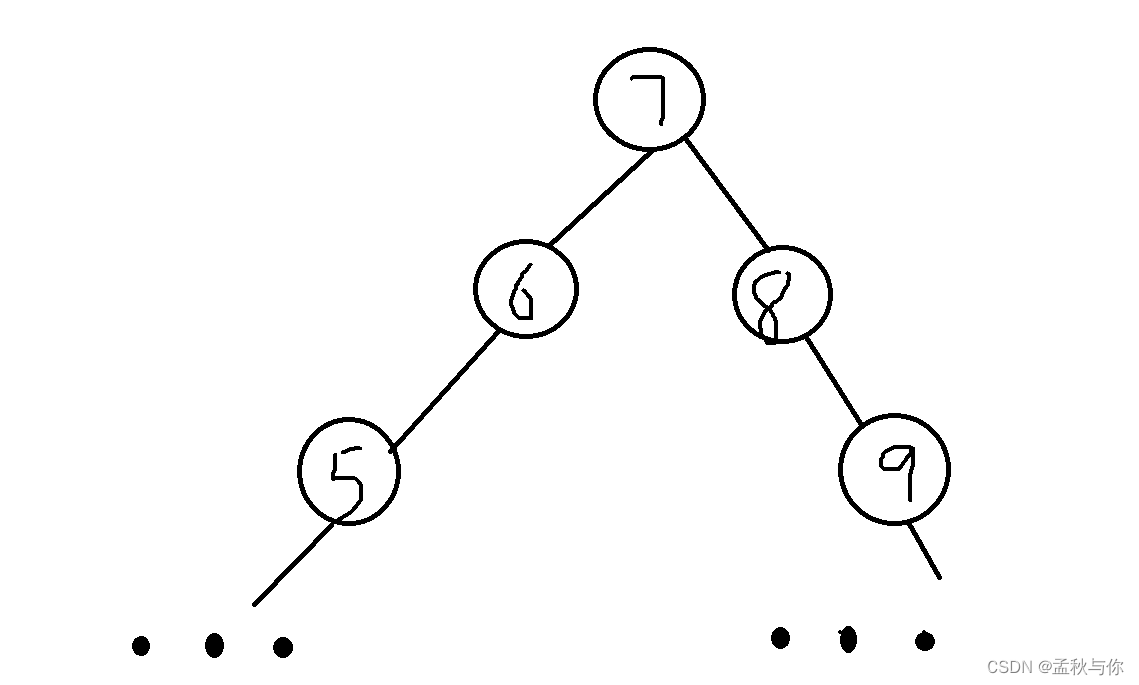
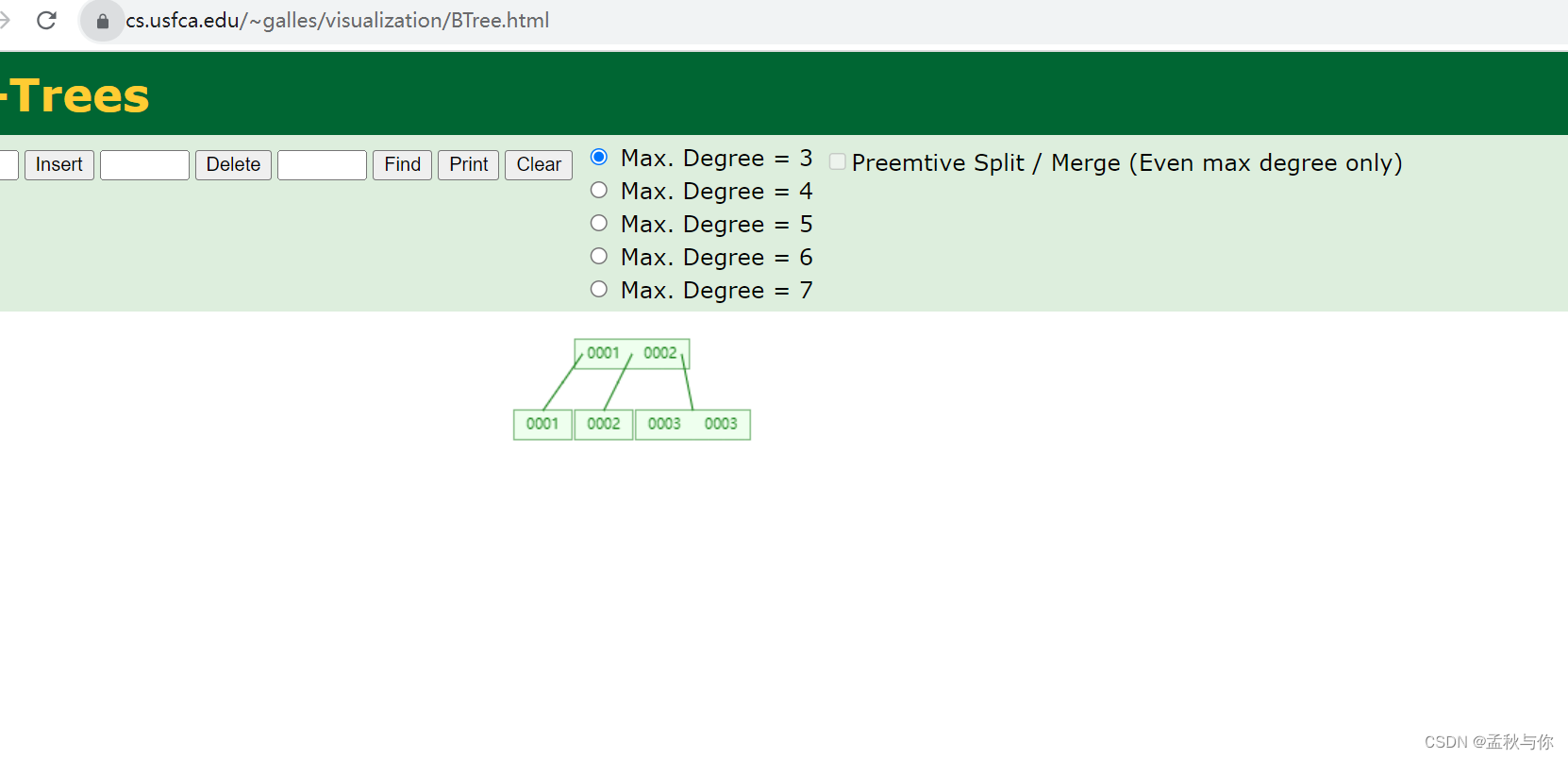
b tree
既然红黑树会有高度的问题,那么 b tree就在优化这个问题:
btree在红黑树的基础上,有了更多的根节点,降低了树的高度,从而降低了磁盘访问次数。
当然 根节点是完全可能因为数据的变化而变化的
这也是博主自认为最通俗的理解了,我们可以借助工具网站来观察:
hash结构
在介绍b+tree之前 我们也简单提一下hash结构,当前mysql版本两大结构就是hash和b+tree了。
hash结构拥有快速的插入和查找速度,但是由于hash的无序性,它并不适合范围查找。
hash结构的主要两大缺点:
- 不支持范围查找
- 极小概率hash冲突
b+ tree
b+tree在btree的基础上,子节点之间都有指针连接,且子节点是个有序链表,更适合作为数据库索引的结构,更利于查询,自然也更好的支持范围查找。
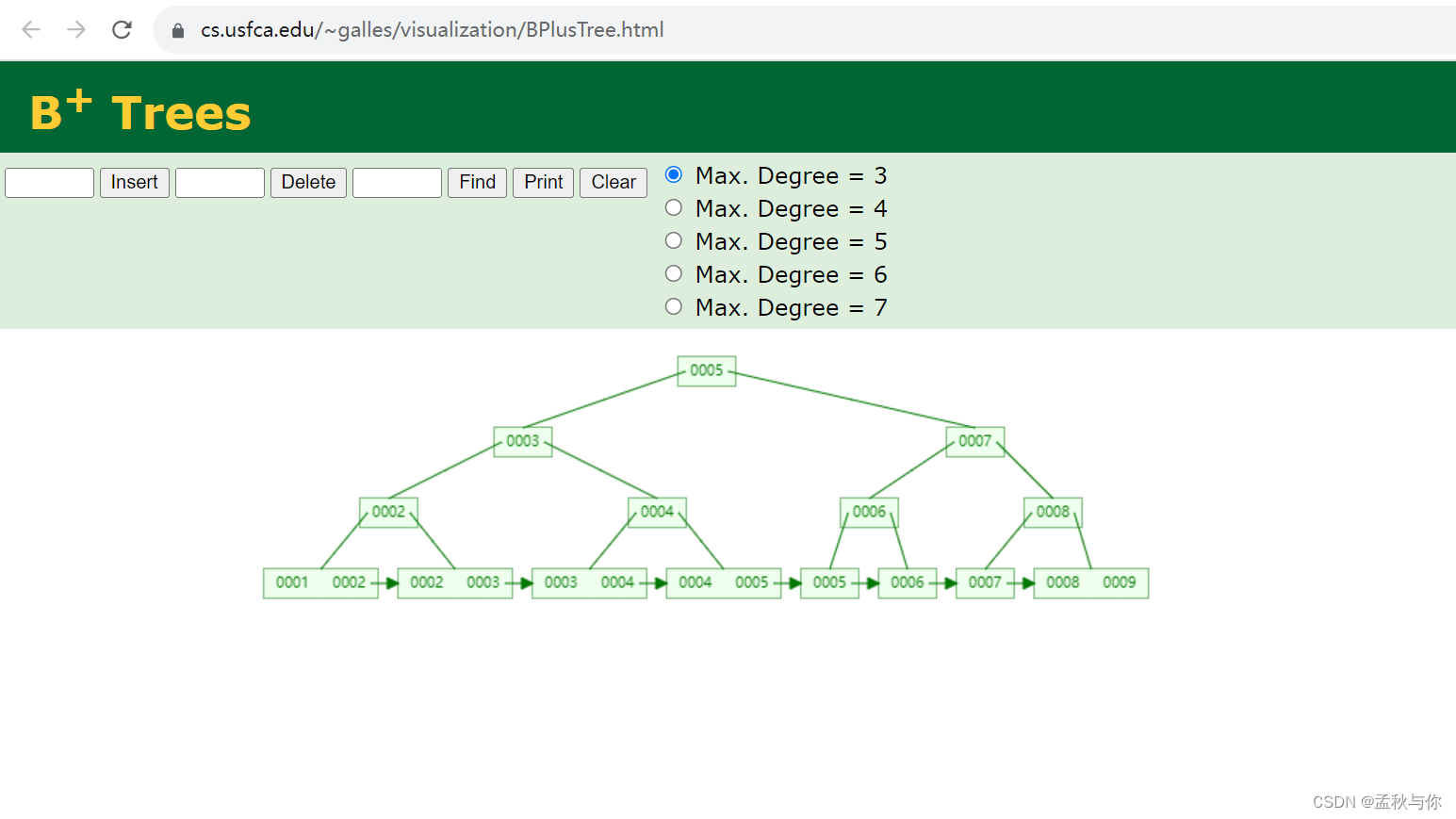
索引存放特点
安装过mysql的同学应该都知道 会有一个data文件夹,data文件夹即存放我们的数据
myisam
(data文件夹下)
存放着三种格式的文件,它们分别存放的内容:
.frm文件: 表结构
(这些文件存储表的定义信息,包括列名、数据类型等表结构相关信息。)
.MYD文件:表数据
( 这些文件是MyISAM表的数据文件,存储着实际的行记录和数据内容。)
.MYI文件: 表索引
(这些文件是MyISAM表的索引文件,存储了表的索引信息)
MYI文件的索引其实就是指向数据真实地址的指针
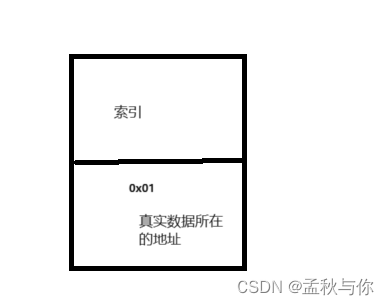
聚集索引:叶节点包含了完整的数据记录
myisam是非聚集索引(表数据和索引分开存放) 是回表查询,即通过索引,再去.MYD文件中查找数据。
InnoDB
(data文件夹下)
存放着两种格式的文件,它们分别存放的内容:
.frm文件: 表结构
(和myisam一样这些文件存储表的定义信息,包括列名、数据类型等表结构相关信息。)
.idb文件 表数据,表索引
(InnoDB存储引擎的数据和索引都存储在共享的数据文件中,通常以.ibd文件的形式存在。.ibd文件包含了表的实际数据以及与之相关的索引信息。)
innoDB是聚集索引
但在它的二级索引(主键之外的索引)查询操作时,会先查找所在的主键,通过主键再去查找具体数据,也是回表查询。
最左原则
联合主键和模糊查询 都遵循最左前缀原则。
在联合主键中,如果由多个列组合而成,那么查询或者排序时会按照主键中列的顺序从左至右依次进行。也就是说,查询或者排序的效率会受到最左边的列的影响,后面的列则会在前面列的基础上进行进一步的筛选。
例如 t 表中,c1 ,c2是联合索引:
select c1 ,c2 from t where c1 = 1; 这是正确的使用姿势
在模糊查询中,最左原则同样适用,例如 like ‘xx%’ 是可以有效利用索引的 俗称走索引, like '%xx’则不能。
主键相关知识点
- 主键推荐用整型,因为b+tree要比较大小,整型比较快
- 自增id效率是最高的
那为什么很多项目不用自增id呢? 自增id两大致命缺点:
- 不适合分表(分布式系统中不适用)
- 很容易被猜到相邻数据 (数据隔离问题)
所以一般都是使用雪花算法,而雪花算法常见的(面试)问题就是时钟回溯,正常发生时钟回溯的概率 是可以忽略不计的,百度的算法是直接抛异常 人工处理,美团有解决方案。
缓存池
InnoDB缓冲池: InnoDB存储引擎使用缓冲池来缓存数据页和索引页,以加快对数据的访问速度。通过在内存中缓存热门数据,可以减少对物理存储设备的访问次数,从而提高系统的性能和响应速度。
淘汰机制
LRU算法:
InnoDB缓冲池会根据LRU(最近最少使用)算法来管理缓存的数据页,确保内存中始终缓存最常访问的数据。
InnoDB下的执行流程及undo redo binlog的作用
tips: 库的crud都是直接操作buffer pool的,buffer pool一般设置为内存的60-70%
( 图片截至诸葛老师的课)
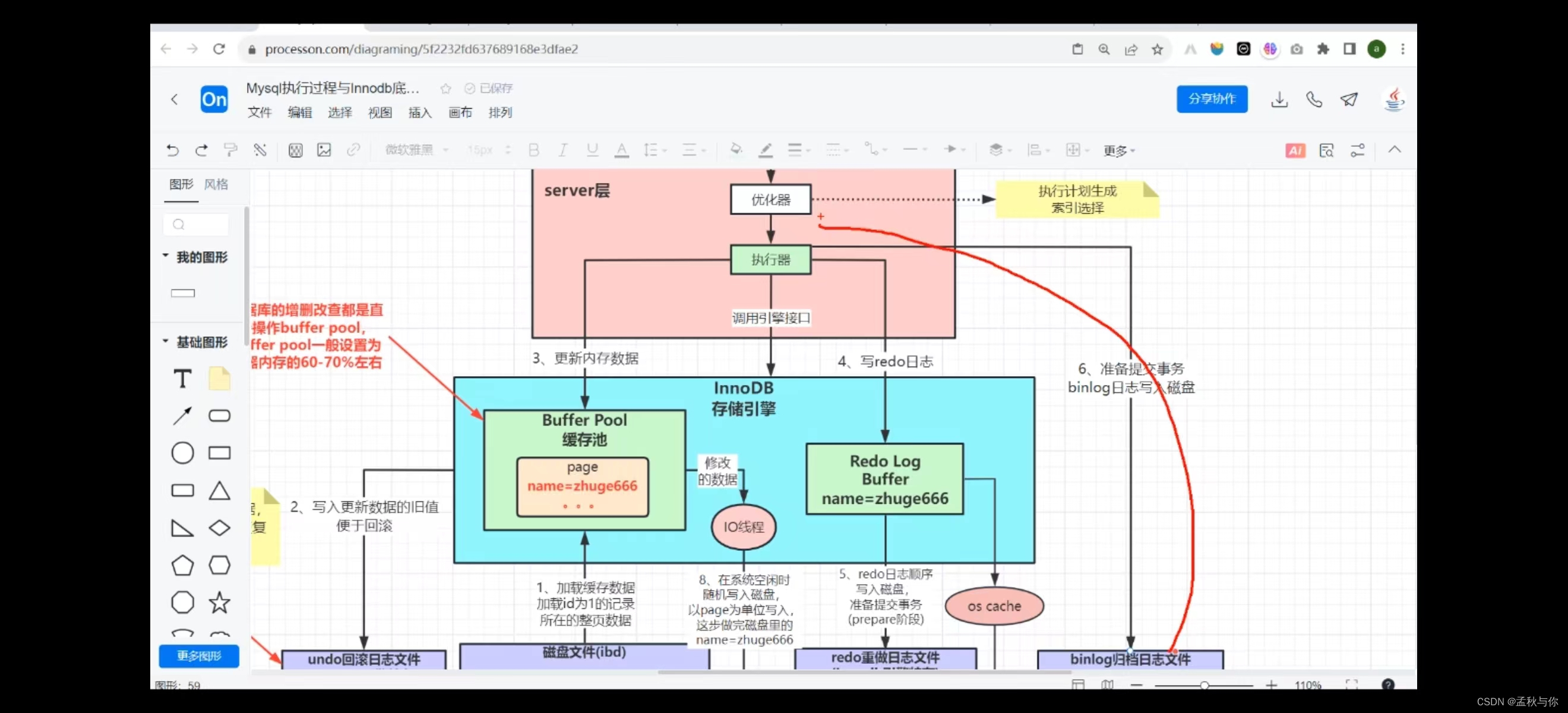
以更新数据为例,博主进行简述:
更新 ->
写undo文件 ->
更新缓存池 ->
写redo文件 ->
写binlog文件 ->
写入commit标记至redo文件(告知客户端已提交事务) ->
系统空闲时 随机将缓存池的数据IO写入磁盘
了解流程后,我们可以分析三种文件的作用:
undo log: 用于回滚
redo log: 当缓存写入磁盘时,如果mysql服务挂了,缓存数据还没来得及写入磁盘 就会数据丢失,redo文件的记录,就可以避免这种情况,mysql会将redo的内容写入磁盘中。
此外,redo还有种写入策略 可以写入到操作系统的缓存中 (os cache) ,
这样mysql挂了 也不会导致数据丢失,且效率会更高,但是当操作系统宕机时,会发生数据丢失。
(只要会数据丢失,都不太适用于大部分场景下的生产环境)
binlog: 二进制文件 主要用于数据复制、备份和恢复等
为什么有了binlog 还要有redo log
首先注意,问题不是为什么有了redo log 还要有binlog , binlog 本身就是早于redo log的,在server层, 而redo log 是InnoDB存储引擎层特有的
binlog 用于在不同数据库实例之间同步数据,实现主从复制
Redo Log 不提供这种跨数据库实例的同步机制,它专注于单个数据库实例的崩溃恢复
binlog是逻辑日志,记录的是一条SQL语句的原始逻辑
redo log是物理日志,记录是"在xxx表空间xxx页xxx偏移量做了什什么修改,值是多少"
binlog不限制大小,追加写入,不会覆盖以前的日志,binlog是追加写,写到一定大小会切到下一个,但是并不会覆盖之前的,日志是全量保存的。
redolog是循环写入,空间一定是会被用完,会产生覆盖。需要write pos和checkpoint搭配使用
不知道各位同学 看到概念可能还是不太容易理解 似乎redo log目的就是为了恢复数据,然而binlog也可以恢复数据 ?
博主的理解:其实关键点在于 redo log是物理日志,省去了原始的逻辑处理过程,而binlog是逻辑日志。
举个不是很专业的例子,binlog就像我们写的java代码,声明了各种逻辑, redo log就像字节码指令 ,所以redo log可以快速的还原数据。















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











