







目录
0. == 和equal的区别。以及为什么要重写hashcode()和equal()
2.3 类A实现Callable接口,重写call方法,有返回值
3.synchronized 和ReentrantLock的区别
9.JVM新生代和老年代如何区分,新生代垃圾回收用什么算法,copy算法内存是怎么分的
12.public、private、protect、default的区别
0. == 和equal的区别。以及为什么要重写hashcode()和equal()
==比较的是地址,equal如果没有重写的话其实比较的还是地址。但是String/Integer比较的时候重写了equal,比较的是实际的内容。
hashmap中是通过hashcode决定元素放入哪个索引(桶)中,然后通过equals判断和索引中中对应链表中的每个元素是否相同。所以如果自己写了一个类,再比较对象相同时,如果用到了hashMap那么两个方法都要重写。也就是说:先判断hashcode再判断equals,如果只重写equals,那么使用hashmap也不会认为他们二者相等。
0.1默认的hashCode方法:
s[0]*31^(n-1) + s[1]*31^(n-2) + ... + s[n-1] 其实就是求31进制转10进制的值。
1.hashMap
内部采用数组+链表+红黑树的方法。在数组长度大于等于64且链表长度大于8时,链表转换为红黑树。红黑树节点小于等于6时,退化为链表(防止一直变来变去)
1.1hashMap大小为什么是2的倍数
初始化默认大小为16,每次扩容大小翻倍。
好处1:在大小为2的n次方时,hashData%len==hashData&(len-1):
因为这样(数组长度-1)正好相当于一个“低位掩码”。“与”操作的结果就是散列值的高位全部归零,只保留低位值,用来做数组下标访问。以初始长度16为例,16-1=15。2进制表示是00001111。和某散列值做“与”操作如下,结果就是截取了最低的四位值。
00100101&
00001111好处2:扩容的时候,可以快速得到一个节点是否需要移动,以及移动的位置。这是由于扩容是扩大为原数组大小的2倍,用于计算数组位置的掩码仅仅只是高位多了一个1,举个例子:
0000 0001 数字1
0001 0001 数字17
0000 1111 扩容前长度为16,用于计算 (n-1) & hash 的二进制n - 1
0001 1111 扩容后为32后的二进制就高位多了1
可以看出根据原数字的高位是否为1就可以判断出是否需要移动。如果是0那就不动。如果是1,那就移动16个位置(旧数组的容量)。1.2 红黑树
是一个比较平衡的二叉查找树。到达叶子结点的最长路径最大不超过最短路径的两倍的。绝对平衡的二叉查找树太耗时了。
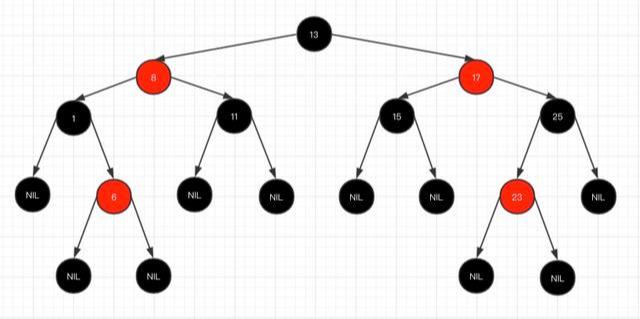
- 每个节点要么是红色,要么是黑色,但根节点永远是黑色的;
- 每个红色节点的两个子节点一定都是黑色;
- 红色节点不能连续(也即是,红色节点的孩子和父亲都不能是红色);
- 从任一节点到其子树中每个叶子节点的路径都包含相同数量的黑色节点;
- 所有的叶节点都是是黑色的(注意这里说叶子节点其实是上图中的 NIL 节点);
如何保持红黑树的平衡:hashmap为什么8转成红黑树_深入分析HashMap的红黑树实现方式_喵杀的博客-CSDN博客
1.3 线程安全
hashMap线程不安全,两个线程同时put,会导致覆盖。解决方法:
- hashTable。直接将整个哈希表锁住,效率低。
- 1.8以前的concurrentHashMap:将hashMap分成多个segment,锁住segment,提高并发效率
- 1.8以后的concurrentHashMap:JDK1.8 的时候已经摒弃了 Segment 的概念,⽽是直接⽤ Node 数组+链表+红⿊树的数据结构来实现,并发控制使⽤ synchronized 和 CAS 来操作。为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。如果不是空,那就是用synchronized把节点锁住
2.如何创建线程、构建线程池原理
(61条消息) Java创建线程的四种方式_上校的小金鱼_的博客-CSDN博客_java创建线程
2.1 类A继承Thread类,重写run方法
A a = new A()
a.start()
2.2 类A实现Runnable接口,重写run方法
A = new A()
newThread(a,"name").start()
2.3 类A实现Callable接口,重写call方法,有返回值
//new 一个对象
Callable<String> callable =new MyThread();
//使用futureTask承接对象
FutureTask <String>futureTask=new FutureTask<>(callable);
//new一个Thread对象,把futureTask放进去
Thread mThread=new Thread(futureTask);
//启动线程
mThread.start();
//得到线程的结果
System.out.println(futureTask.get());2.4 线程池
1核心线程数,2最大线程数,3阻塞队列,4超时销毁时间,5饱和拒绝策略。6核心线程超时是否关闭
简单来说:当一个请求过来时,如果当前线程数少于核心线程数,则创建一个线程工作。
如果当前线程数大于等于核心线程数,则将请求放在阻塞队列。
如果阻塞队列满了,就拿阻塞队列中的一个任务新建线程来跑。
如果线程数超过了最大线程数,那就执行饱和拒绝策略。
具体:java多线程之ThreadPoolExcutor_weixin_34343000的博客-CSDN博客
3.synchronized 和ReentrantLock的区别
- synchronized是Java的关键字,是JVM层面的锁,不需要手动释放。ReentrantLock是API,需要使用lock和unlock来实现。
- synchronized可以用在方法或代码块上,但是ReentrantLock只能用在代码块上
- ReentrantLock可以设置超时,可以设置公平锁或非公平锁
- ReentrantLock可以绑定多个条件,synchronized不行。
具体看:面试官:谈谈synchronized与ReentrantLock的区别? - 知乎
4.进程 VS 线程
- 进程是资源的分配和调度的独立单元。进程拥有完整的虚拟地址空间,当发生进程切换时,不同的进程拥有不同的虚拟地址空间。而同一进程的多个线程是可以共享同一地址空间
- 线程是CPU调度的基本单元,一个进程包含若干线程。
- 线程比进程小,基本上不拥有系统资源。线程的创建和销毁所需要的时间比进程小很多
- 由于线程之间能够共享地址空间,因此,需要考虑同步和互斥操作
- 一个线程的意外终止会影像整个进程的正常运行,但是一个进程的意外终止不会影响其他的进程的运行。因此,多进程程序安全性更高。
5.线程VS协程
协程(Coroutine,又称微线程)是一种比线程更加轻量级的存在,协程不是被操作系统内核所管理,而完全是由程序所控制。
- 协程可以比作子程序,但执行过程中,子程序内部可中断,然后转而执行别的子程序,在适当的时候再返回来接着执行。协程之间的切换不需要涉及任何系统调用或任何阻塞调用
- 协程只在一个线程中执行,是子程序之间的切换,发生在用户态上。而且,线程的阻塞状态是由操作系统内核来完成,发生在内核态上,因此协程相比线程节省线程创建和切换的开销
- 协程中不存在同时写变量冲突,因此,也就不需要用来守卫关键区块的同步性原语,比如互斥锁、信号量等,并且不需要来自操作系统的支持。
原文链接:https://blog.csdn.net/bjweimengshu/article/details/107776724
6.偏向锁/轻量级锁/重量级锁
这三种锁是指锁的状态,并且是针对Synchronized。通过引入锁升级的机制来实现高效Synchronized。这三种锁的状态是通过对象监视器在对象头中的字段来表明的。
- 偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。
- 轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。
- 重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低
7.线上oom怎么排查
- 使用top命令看一下线上的CPU、内存是否正常。
- 定位异常进程,看日志。
- 如果是OOM,用jstat -gc pid 1000 100(每秒)监控JVM内存运行状况和gc频率。
- jmap -dump:live,format=b,file=dump3.hprof pid ,使用jmap dump内存快照。
- 使用MAT工具进行分析。
(61条消息) Java线上环境OOM问题排查_方木丶的博客-CSDN博客_线上oom怎么排查
8.Java内存模型和Java内存结构
1.Java内存模型:线程可以把变量保存本地内存(⽐如机器的寄存器) 中,⽽不是直接在主存中进⾏读写。这就可能造成⼀个线程在主存中修改了⼀个变量的值,⽽另 外⼀个线程还继续使⽤它在寄存器中的变量值的拷⻉,造成数据的不⼀致。要解决这个问题,就需要把变量声明为 volatile ,这就指示 JVM,这个变量是共享且不稳定的, 每次使⽤它都到主存中进⾏读取。
2.Java内存结构:
JVM内存结构指的是Java虚拟机在运行程序的过程中会把内存分为不同的区域,根据JDK1.8以前,运行时数据区域包括程序计数器(Program Counter Register)、虚拟机栈(VM Stack)、本地方法栈(Native Method Stack)、Java堆(Heap)、方法区(Method Area)、运行时常量池。
Java堆中包含新生代、老年代和永久代。在1.8之后永久代+方法区+运行时常量池都被放到了元空间里,也就是直接内存里面,不需要分配一块大小了。
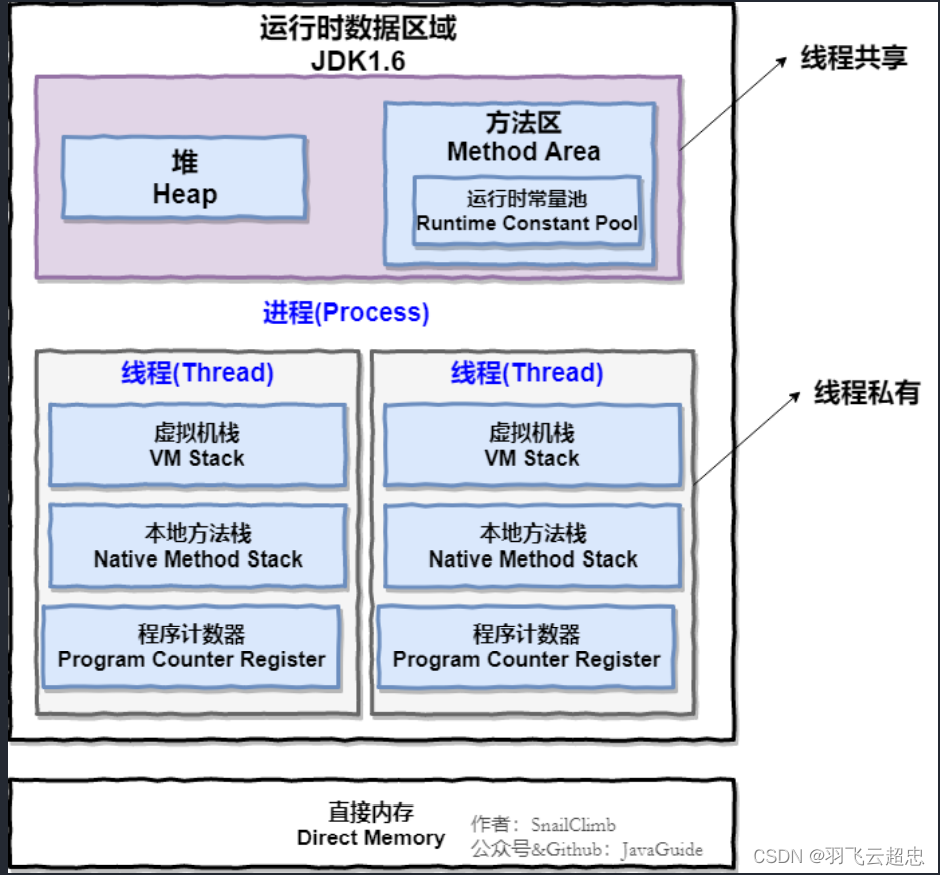
JVM内存结构和Java内存模型 - 掘金 (juejin.cn)
9.JVM新生代和老年代如何区分,新生代垃圾回收用什么算法,copy算法内存是怎么分的
(1)JAVA堆中是JVM管理的最大的一块内存空间,主要存放对象实例。JAVA中堆被分为两个两块区域,即新生代(young,1/3)和老年代(old,2/3)
所谓的新生代和老年代是针对于分代收集算法来定义的。区别:存放对象生命周期不同,垃圾回收机制不同。
新生代GC(minor gc)主要是用来存放新生的对象,分为Eden和Survivor(from,to)两个区,这样划分是为了更好的管理堆内存中的对象,
方便GC算法---复制算法来进行垃圾回收。
老年代GC(major gc)主要存放应用程序中生命周期长的内存对象,指发生在老年代的垃圾回收动作,所采用是的标记--整理算法。
(2)新生代采用复制算法回收垃圾。
(3)copy算法基本思想:将内存分为两块,每次只用其中的一块,当这一块内存用完,就将还活着的对象复制到另一块上面。
具体地说,在GC开始的时候,对象只会存在到Eden区和From Survivor区中,而To Survivor区的内容是空的,紧接着进行GC,然后Eden区存活的对象都会被复制到“To”,而“From”区里面的对象年龄会加1,当年龄达到一定数值(年龄阈值),对象会被移动到老年代里,没有达到的被复制到“To”里面。因此经过GC后,Eden和“from”中的对象会被清空,这个时候,“From”和“To”交换角色,然后重复这样的过程,直到“To”区域被填满,“To”被填满后,会将所有的对象都移动到老年代中。
10.BIO 和NIO的区别。
BIO属于阻塞IO,每一个请求都是用一个专门的线程去处理,尽管这个请求暂时不需要进行IO操作,我们这个线程仍然被占用。我们可以使用多线程和线程池的方式去做复用,但是效率仍然比较低。
NIO是非阻塞IO,使用IO多路复用的想法,使用一个线程监视多个请求连接,只有当请求需要进行IO操作时,才会分配一个线程去处理。
11.单例模式
1.懒汉式,线程不安全。getInstance判断为空,直接new一个。
2.懒汉式,线程安全。getInstance方法使用synchronized关键字。效率低。
3.饿汉式,直接初始化的时候就new一个出来。占内存
4.双重检测锁。先判断,再加锁,再判断。可以使用反射修改构造方法的类型,破坏。
5.内部静态类。内部再套一个静态类,静态类里面直接new一个instance。这样尽管外面的类初始化了,但是只要不调用getInstance方法,就不会主动生成。
6.枚举法。使用枚举对象。多线程,抗反射。
一般来说用第三个饿汉式,其次用内部静态类,再次用枚举法,最后采用双重检测锁。
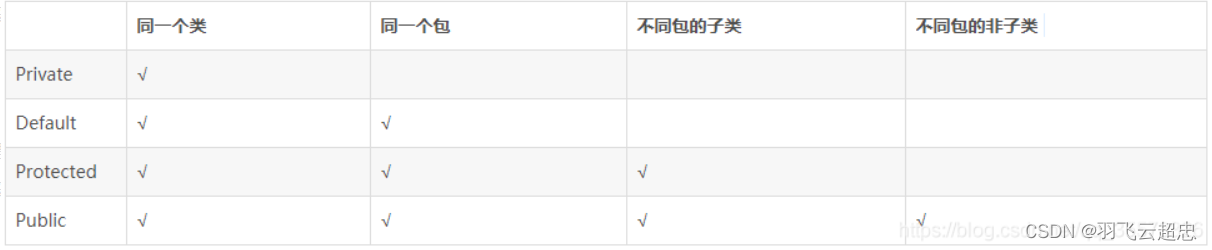
12.public、private、protect、default的区别
13.如何实现一个阻塞队列
一个队列我们可以用一个数组和头尾指针构成一个队列,或者使用链表的方法生成一个队列。
阻塞队列与普通队列的区别在于:普通队列在出队时应报错或者返回空。而阻塞队列需要一直等在这里,直到队列有元素时再出队。入队时也是如此,如果队列是满的,那么应该一直阻塞在这里。















 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









