







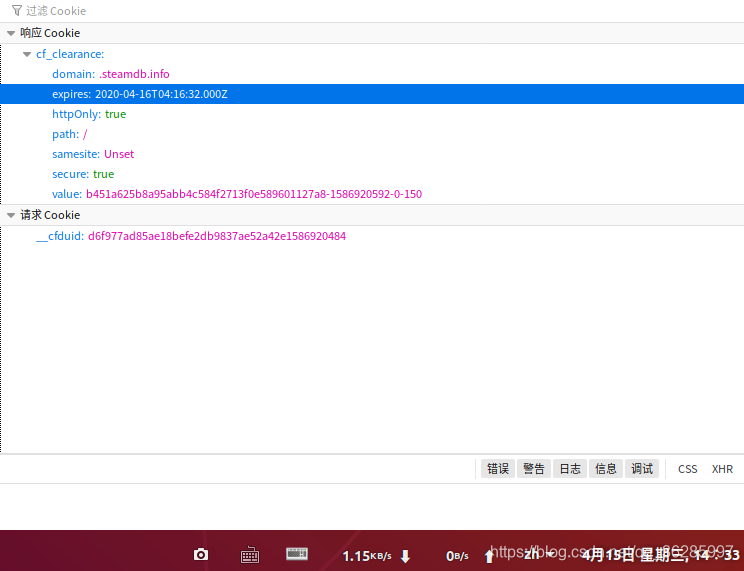
steamdb爬取时,需要验证cookie,分析可知cookie有效时间为一天
接下来开始正文,分析cookie如何获取。
一. 网站访问需求
经尝试得知,网站主要验证cookie中的 __cfduid 与 cf_clearance
只有俩同时有,网站才能正常访问。
二. 分析网站逻辑
2.1 接下来分析,__cfduid 与 cf_clearance 是如何得到的

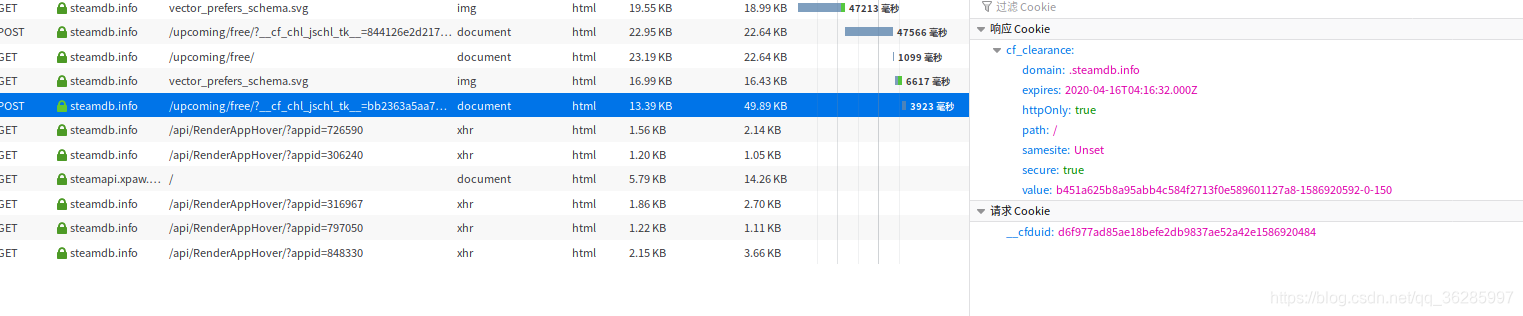
可以看出,在访问网站时,进行了俩次访问。第一次访问时,返回了503,在第二次访问时,返回了200。
第一次访问时,不带cookie, 进行get, 返回了503 ,以及 cookie中的__cfduid值。
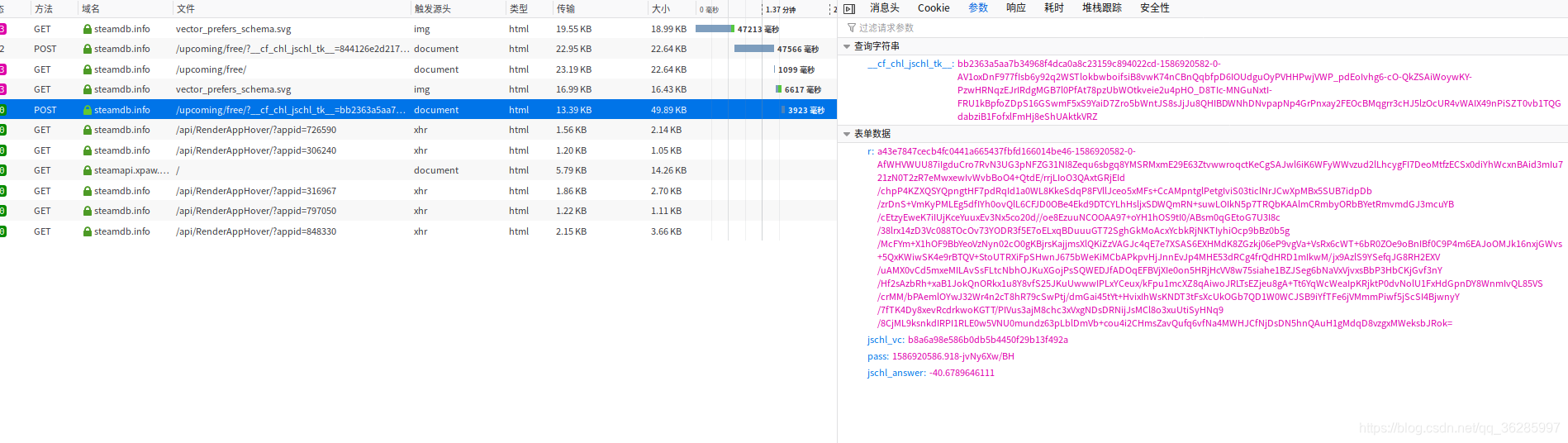
第二次访问时,为post, 分析可以看出,cf_clearance值就是在这次请求中返回的。只要解决掉这次post就可以得到cf_clearance。
 2.2 分析第二次post的网址以及参数是如何得到的。
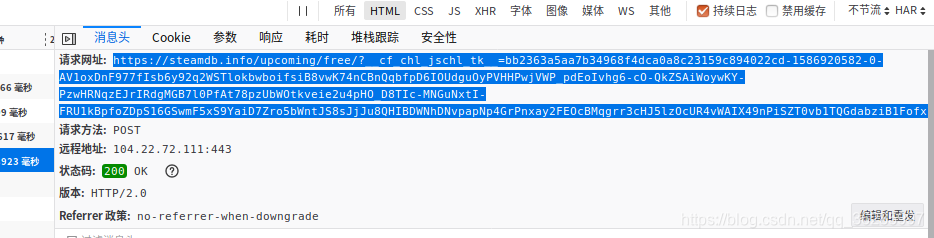
2.2 分析第二次post的网址以及参数是如何得到的。
这次post,需要知道的有:
1.请求字符串,就是网址后面的一串,经尝试,每次请求都是不同的。
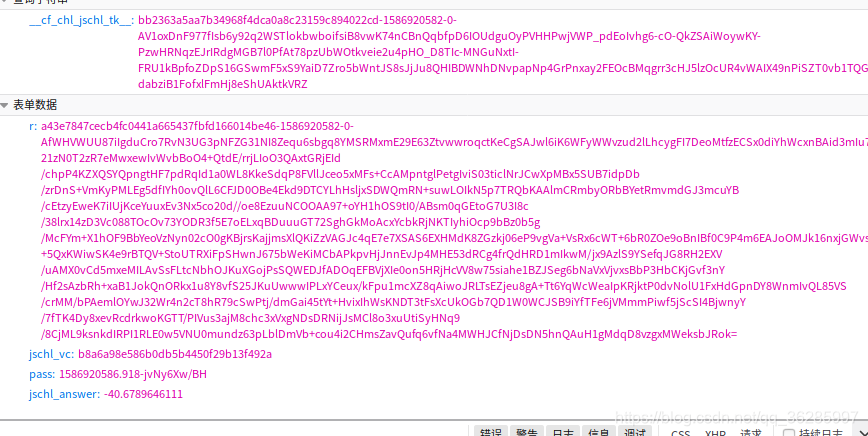
2. 表单数据 r、jschl_vc、pass、jschl_answer
既然每次请求均不同,且我们只访问了俩次网址,那么,这些参数必然是第一次get时返回的信息中获取的。
2.3 分析第一次get返回的信息
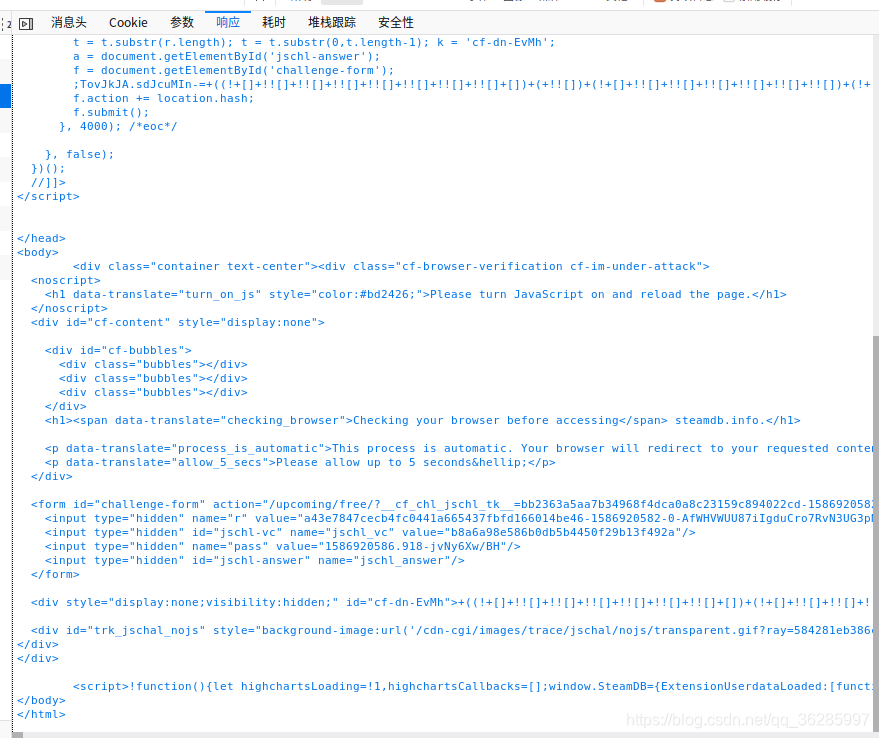
尝试分析,第一次get返回的数据,在form表单中,我们可以很明显的获取 请求字符串,r、jschl_vc、pass 的值,但是jschl_answer 并没有值,继续分析返回的数据,

在网站的js中,我们可以发现这么一行,a = document.getElementById('jschl-answer'); 从页面中获取jschl-answer元素。
在后续的js中,还可以发现 a.value = (+JAdEwio.gi).toFixed(10); '; 121;
得出,jschl-answer 的值是经过js计算得出的。
这样,我们就得到了第二阶段 post的地址,以及参数
2.4 进行第二次请求,获取cf_clearance
进行第二次请求,网站返回 cf_clearance 值,至此,通过携带cf_clearance与__cfduid,我们便可以任意的访问steamdb网站,获取我们需要的信息。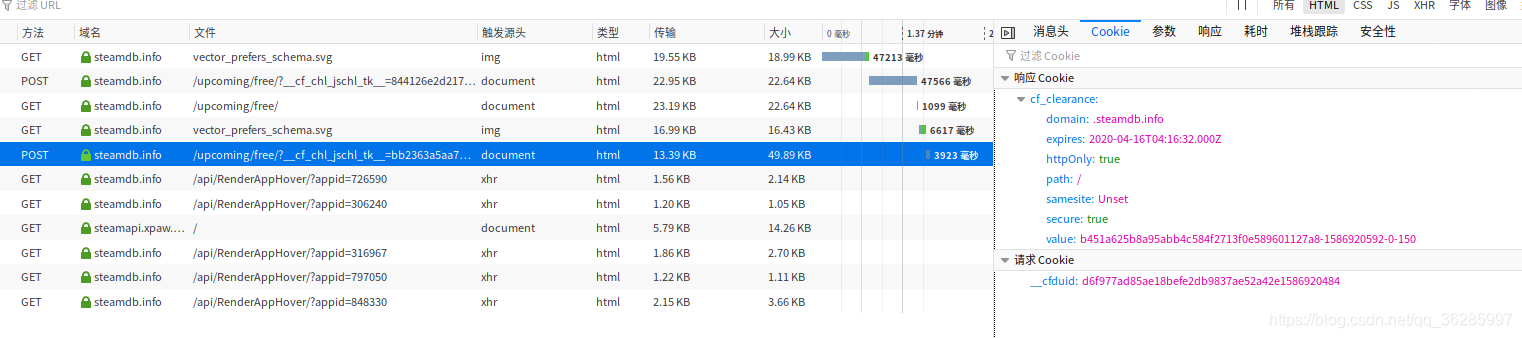
### 需要注意 如果是第一次访问,__cfduid在第一次和第二次直接会进行一次改变,记得更新。###

















 2500
2500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









