






最近新入职,闲来之余,写点东西和我自己的思考。水平比较菜,和大家一起进步。
本着抓主要矛盾的原则,本文不涉及到配环境这种教程性内容,相信大家上班以后可能也没时间打磨精益求精,这里只写设计和重要实现。
这里引用一个hadoop设计的总结,个人认为用精简的语言清晰描述了map-reduce的架构和原理:

1. 问题重述
本lab实现一个map-reduce(后简称mr)框架。
一次mr作业的主要工作内容如图:
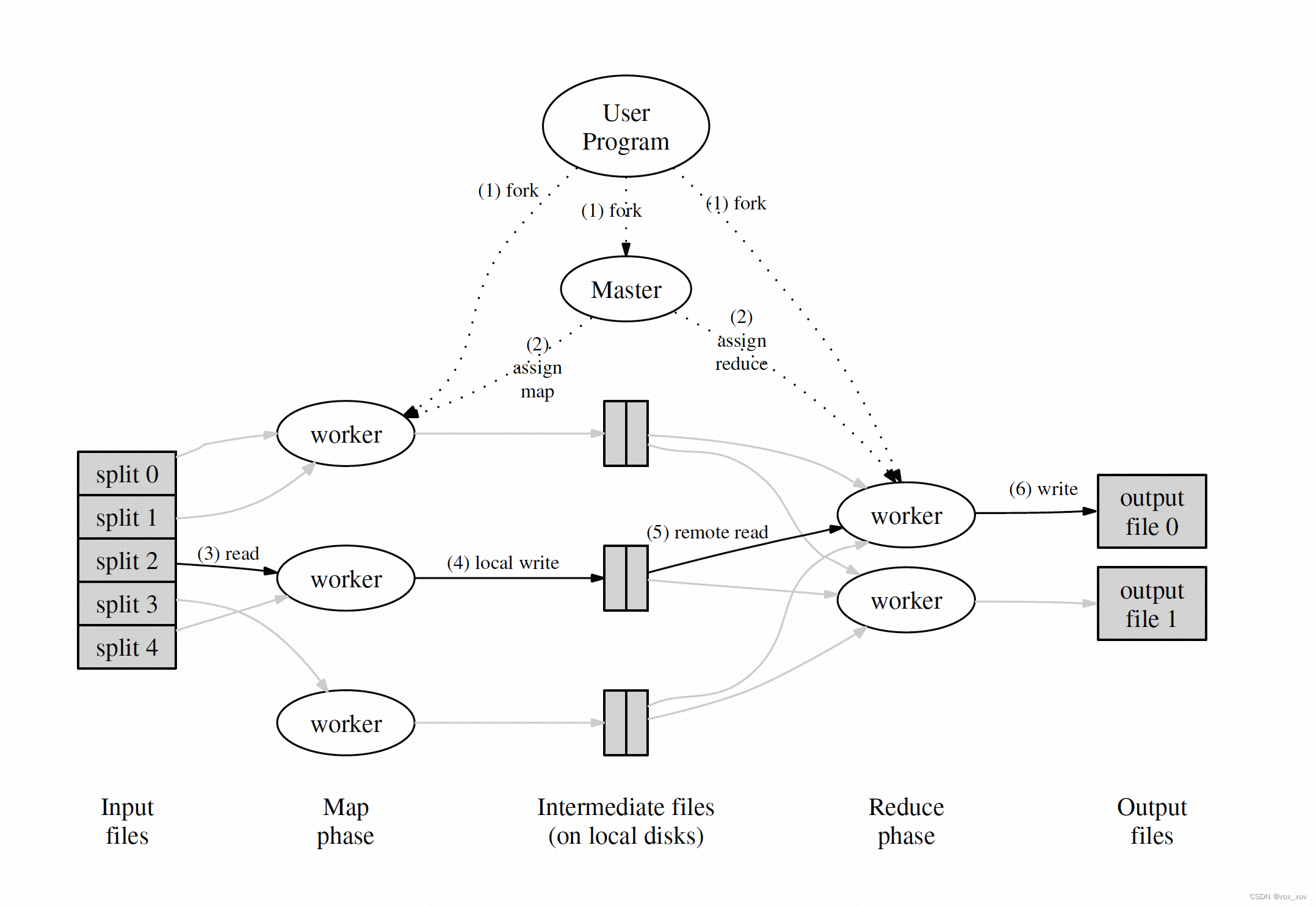
工作节点可以分成两类,master和worker。其中,master负责工作调度,worker负责map操作和reduce操作的实际执行,一次mr批处理可以分为M个map任务和N个reduce任务,这些任务用push/pull的方式发送给worker,让worker进行真实的任务执行。
- 将输入文件进行split,分成M等分,master产生M个map任务,交给worker处理。每个map任务读取split的文件,按照用户传入的函数将文件内容映射成若干k-v对,并将k-v对均分至N个中间文件中(可以根据hash值),这N个文件都存在worker的本地,一共产生M*N个中间文件。
- 全部map任务完成后,master就可以开始调度reduce任务,一共产生N个reduce任务。reduce任务需要读取每个map产生的中间文件的一部分,如下图所示
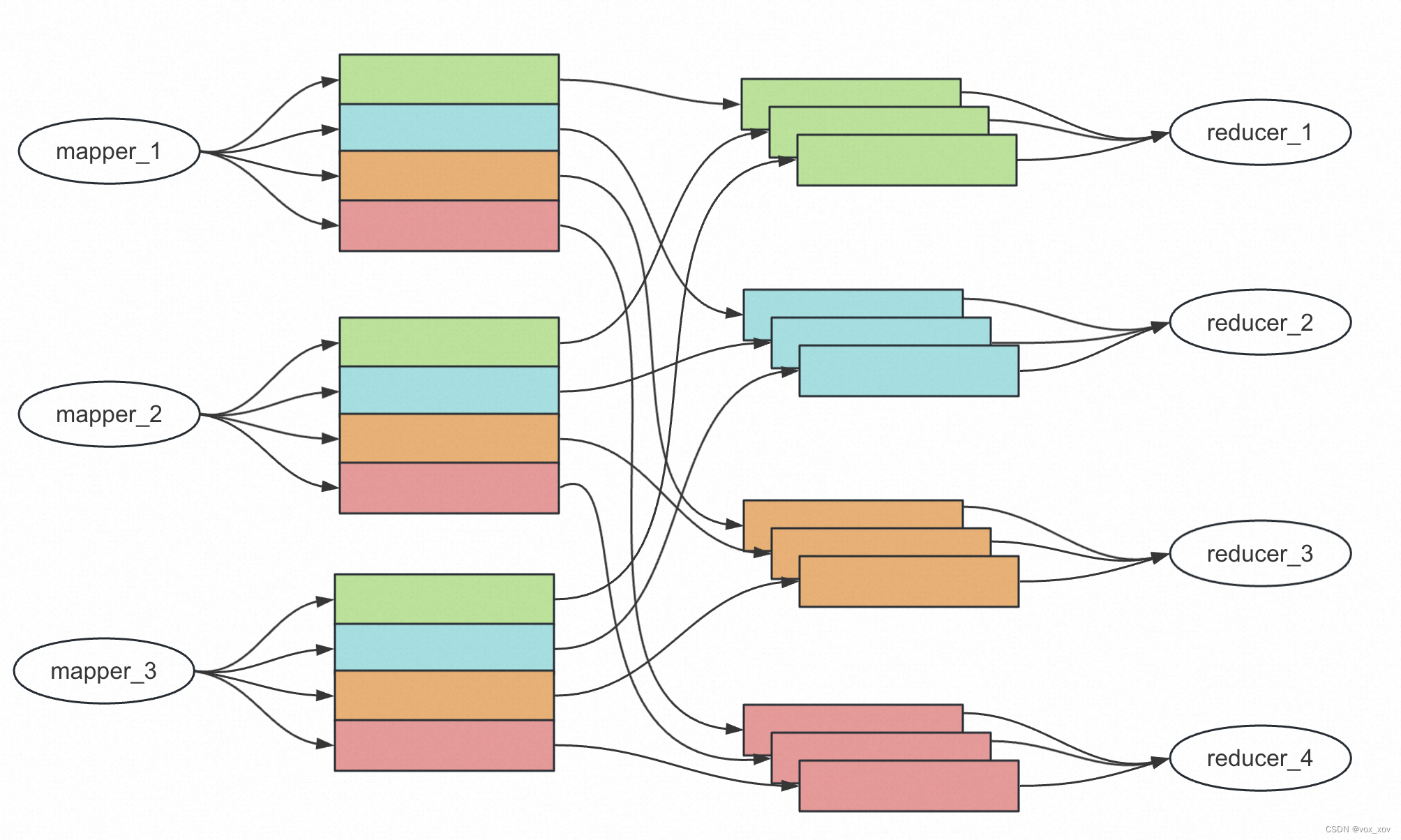
这个整合读取的过程叫做shuffle。在真实分布式环境中,shuffle过程需要多次远程rpc调用,比较耗费资源。
再次通过例子解释一下shuffle的初衷:不同的map任务处理的是split过后不同的文件,如mapper_1处理的是file_1,mapper_2处理的是file_2,而不同file之间是水平切割的,导致file_1和file_2中含有相同的key,这些相同的key应该被同一个reducer处理。但是,mapper_1和mapper_2所产生的中间文件分布在不同的机器上,这就需要reducer去每个机器上分别去取相同的key对应的内容,整个过程就是shuffle。与此同时需要注意的是,上述例子中所述的key不仅仅单指一个key,也可以指一群key的集合,比如他们的hash值具有相同的特征等。我们不可能为每一个key都分配一个reducer去处理,更多情况下一个reducer处理的是一批key,比如上图的reducer_1处理的就是绿色部分的key集合。
3. 在每个reducer上,对shuffle的结果进行合并,并交给用户的reduce函数进行处理,最后输出到文件系统中。
2. 设计思路
总体思路
本lab采用master-worker架构,master负责调度任务,worker负责执行任务。
任务(后称task)有两种,map-task与reduce-task。
采用worker pull task的方式,即worker不断轮询,如果master侧有空闲的task,就分配给worker,否则一直轮询。
worker设计
- 主线程启动定时器,开始轮询
- 发送GetTask请求至master,获取master当前可用的task。与此同时,还作为心跳,有一个续命(keep-alive)的作用。
2.1 如果是map-task,读取相应file,并运行user传入的map函数,得到若干kv对。按照hash(key)%N,将输出写到N个本地file中。第m个map-task一共产生N个中间file,分别为 file-m-1,file-m-2,…,file-m-N
2.2 如果是reduce-task,首先进行shuffle。第n个reduce-task一次性读取file-1-n,file-2-n,…,file-M-n个文件,并进行合并。然后按照key进行排序。之后运行user传入的reduce函数,得到output,写入文件output-n中。一共N个reduce-task,所以一共产生output-1~output-N 这N个输出文件。
2.3 GetTask得到结果后,为了不阻塞心跳,应当异步运行map-task/reduce-task。
2.4 如果是GetTask得到任务已经完成的消息,直接退出轮询,结束工作。 - 如果map-task/reduce-task任务完成,向master发送FinishTask请求,异步工作线程结束。
- 为了防止worker挂掉时,正在运行的map-task/reduce-task失效,需要考虑容错,设计如下:worker在定时轮询时同时上报心跳,上报心跳的方式是在GetTask请求中携带自己目前正在运行的task,这样master看到后就能知道这些task目前正在有worker跑。如果某个task长时间不向master更新状态(master会维护一个定时器去定时查看这些task有没有过期,下一节具体介绍),master会认为worker已经失效,从而重新调度task。
master设计
- master中需要维护若干数据结构,主要有:
1.1 map-task的数组,包括每个map-task的状态(IDLE,RUNNING,FINISH),每个map-task对应的location(split后文件的存放位置),每个map-task的过期时间(worker容错设计)
1.2 reduce-task的数组,包括每个reduce-task的状态(IDLE,RUNNING,FINISH),每个reduce-task对应的location集合(file-1-n,file-2-n,…,file-M-n),每个reduce-task的过期时间(worker容错设计)
1.3 lock,控制共享变量并发 - master启动后,先生成M个map-task,供worker去消费,同时等待worker的消费结果。
- 收到M个FinishTask后,就生成N个reduce-task,供worker去消费,同时等待worker的消费结果。
- 收到N个FinishTask后,将Done标志位变为true,worker轮询到Done为true时会自动退出。
- 为了防止worker挂掉,需要进行容错设计。在master端需要维护一个后台线程,去定时轮询每一个RUNNING的map-task/reduce-task的过期时间(last_modified_time),用time.now-last_modified_time后,判断是否大于阈值(这个阈值时提前设定好的),如果大于阈值,说明已经超时,就将这个map-task/reduce-task的状态改为IDLE,等待重新被调度。
- master-worker架构中,如果master挂掉没有什么比较好的容错方法,因为master必须完全可靠。可以采用持久化状态到DB/多节点raft的方法维护master的状态,这里不做延伸。
3. 重要实现
worker的定时轮询代码
ticker := time.NewTicker(500 * time.Millisecond)
for {
select {
case <-ticker.C:
// CallExample()
ret := w.getTask()
if ret != nil {
if ret.Finished {
return
} else {
if ret.Type == MAP {
w.lock.Lock()
w.runningTasks[fmt.Sprintf("%s-%d", MAP, ret.Index)] = true
w.lock.Unlock()
go w.handleMap(w.mapf, ret.MapLocation, ret.Index) // async
} else if ret.Type == REDUCE {
w.lock.Lock()
w.runningTasks[fmt.Sprintf("%s-%d", REDUCE, ret.Index)] = true
w.lock.Unlock()
go w.handleReduce(w.reducef, ret.ReduceLocations, ret.Index) // async
}
}
}
}
}
需要注意的是,我对每个map-task和reduce-task的执行都采用了异步线程执行方式,这样的方式可能会出现的问题是,如果某一个task本身挂掉了(不是这个worker挂掉了),可能会导致无法再被运行一遍。但是这种情况真的是框架的问题么,我持怀疑态度。如果某个goroutine挂掉了,只能有一种可能就是用户的代码运行时出现了错误,这种错误再跑一次也会是错误的,所以我认为不用考虑这种情况(或者可以加入一个重试次数,不过有点麻烦且不影响主要实现,就不做了)
master的调度代码
func (c *Coordinator) Schedule(args *TaskArgs, reply *TaskReply) error {
c.lock.Lock()
defer c.lock.Unlock()
if c.Finished {
reply.Finished = true
return nil
}
// deal with heartBeat
log.Printf("[heartBeat] running tasks are:%v\n", args.RunningTasks)
for i := 0; i < len(args.RunningTasks); i++ {
info := strings.Split(args.RunningTasks[i], "-")
taskType := info[0]
taskIndex, _ := strconv.Atoi(info[1])
if taskType == MAP {
c.MapTasks[taskIndex].LastModifiedTime = time.Now()
} else if taskType == REDUCE {
c.ReduceTasks[taskIndex].LastModifiedTime = time.Now()
}
}
// schedule map-task
for i := 0; i < len(c.MapTasks); i++ {
if c.MapTasks[i].State == IDLE {
reply.Index = i
reply.MapLocation = c.MapTasks[i].MapLocation
reply.Type = MAP
c.MapTasks[i].State = INPROGRESS
c.MapTasks[i].LastModifiedTime = time.Now()
log.Printf("[schedule] mapTask-%d\n", i)
return nil
}
}
// schedule reduce-task
for i := 0; i < len(c.ReduceTasks); i++ {
if c.ReduceTasks[i].State == IDLE {
reply.Index = i
reply.ReduceLocations = c.ReduceTasks[i].ReduceLocations
reply.Type = REDUCE
c.ReduceTasks[i].State = INPROGRESS
c.ReduceTasks[i].LastModifiedTime = time.Now()
log.Printf("[schedule] reduceTask-%d\n", i)
return nil
}
}
return nil
}
这里我采用了比较粗暴的方式,每次worker轮询master来GetTask时,master都会加锁,同时遍历map-task和reduce-task的数组,从而找到合适的task并返回给worker。与此同时,master还会根据worker上报的task的状态,去更新每个RUNNING task的过期时间
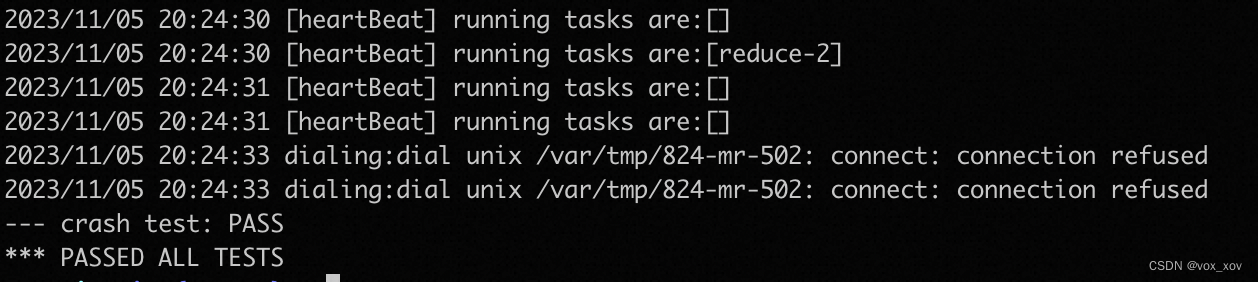
4. 结果
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









