







https://zhuanlan.zhihu.com/p/39490840
EM 最大熵模型。先说适用范围吧,在之前的讨论中,给出样本观测值之后我们直接通过线性回归、logistic回归计算对数似然函数,求导得到参数的值,但是如果其中含有隐变量,那么我们之前的求导方式就存在问题了。EM模型主要就是解决含有隐变量的参数模型的最大似然估计或极大后验概率估计的!
在这里需要先有一个先验知识,Jenson不等式哦。直接贴图:

那么Jenson不等式的定义如下:
如果f(x)是凸函数,那么有
![]()
当且仅当X是常数的时候等号成立,如果f(X)是凹函数,不等号反向。
下面我们考虑一个问题,样本中有我们不确定的类别,样本间独立,我们想找到每个样例隐含的类别z,能使得p(x,z)最大。p(x,z)的最大似然估计如下:

然后对这个公式做一点变化,就可以用上jensen不等式了,神奇的一笔来了:

(1)到(2)比较直接,就是分子分母同乘以一个相等的函数。(2)到(3)利用了Jensen不等式。对于每一个样例i,让Qi代表样本中隐变量的分布,![clip_image032[1]](http://images.cnblogs.com/cnblogs_com/jerrylead/201104/201104061616025060.png) 满足的条件是
满足的条件是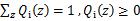 ,那么
,那么 可以看作是E(x),即我们可以定义x=
可以看作是E(x),即我们可以定义x= ,那么又因为log函数是个凹函数,log(E(x))》=E(log(x)),于是我们就可以得到(3)。通过上面的不等式,我们就可以确定式子的下界,然后我们就可以不断的提高此下界达到逼近最后真实值的目的值,那么什么时候达到想到的时候呢,没错,就是这个不等式变成等式的时候,然后再依据之前描述的jensen不等式的说明,当不等式变为等式的时候,当且仅当
,那么又因为log函数是个凹函数,log(E(x))》=E(log(x)),于是我们就可以得到(3)。通过上面的不等式,我们就可以确定式子的下界,然后我们就可以不断的提高此下界达到逼近最后真实值的目的值,那么什么时候达到想到的时候呢,没错,就是这个不等式变成等式的时候,然后再依据之前描述的jensen不等式的说明,当不等式变为等式的时候,当且仅当 ,也就是说X是常量,推出就是下面的公式:
,也就是说X是常量,推出就是下面的公式:

再推导下,由于 (因为Q是随机变量z(i)的概率密度函数),则可以得到:分子的和等于c(分子分母都对所有z(i)求和:多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c)
(因为Q是随机变量z(i)的概率密度函数),则可以得到:分子的和等于c(分子分母都对所有z(i)求和:多个等式分子分母相加不变,这个认为每个样例的两个概率比值都是c) ,再次继续推导;
,再次继续推导;

最后就得出了EM算法的一般过程了:
循环重复直到收敛
E步:对于每一个i,计算

M步:计算

文字总结就是:
1、初始化分布参数。
2、(E-Step)计算期望E,利用对隐藏变量的现有估计值,计算其最大似然估计值,以此实现期望化的过程。
3、(M-Step)最大化在E-步骤上的最大似然估计值来计算参数的值
4、重复2,3步骤直到收敛。















 1324
1324

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









