






MQ学习分享
MQ的作用是什么
- 解耦
A->B,变成A->MQ->B,A发送消息到MQ上,B从MQ拿。这样下游对这条消息消费失败是不会影响到上游的。
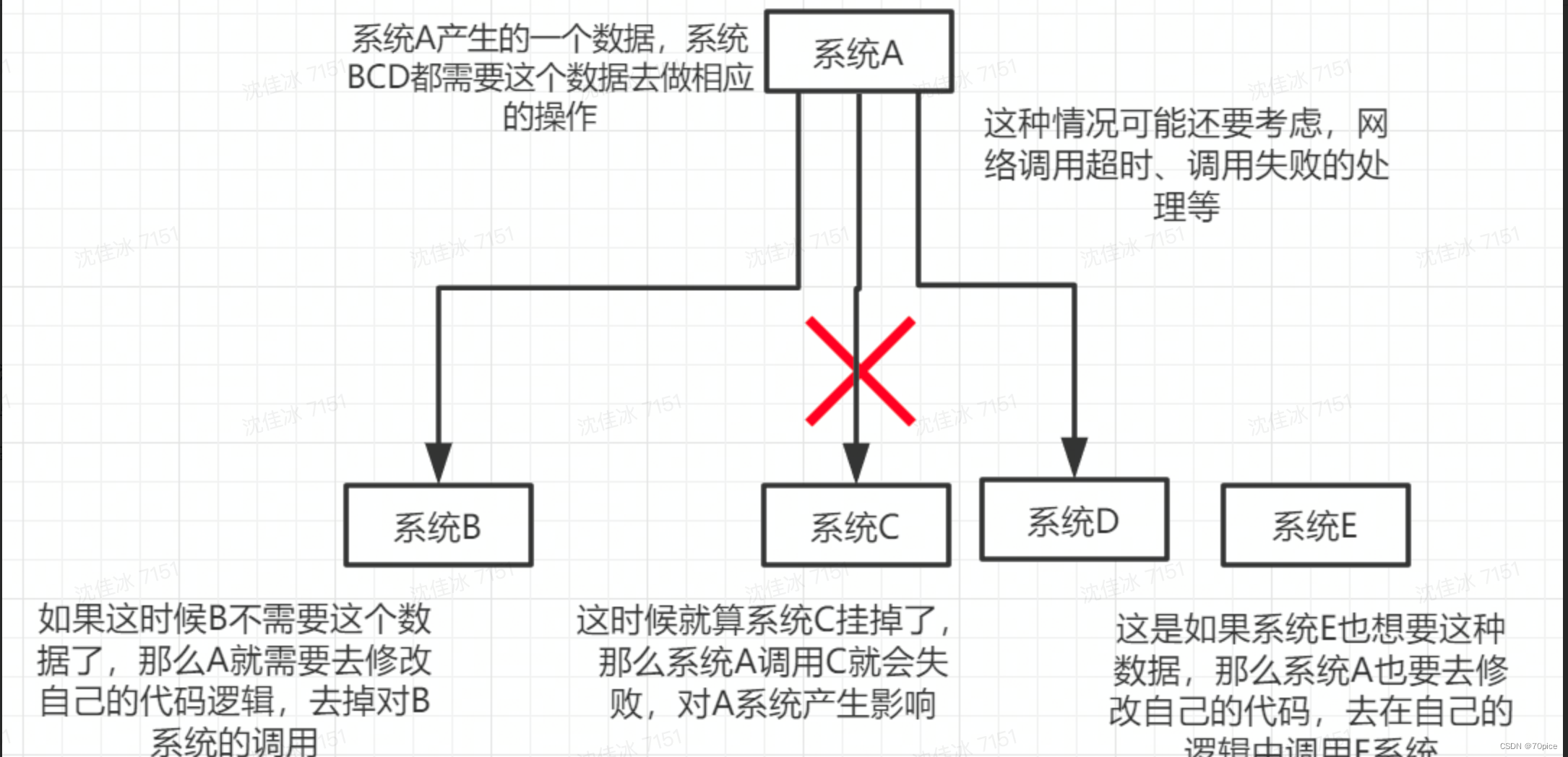
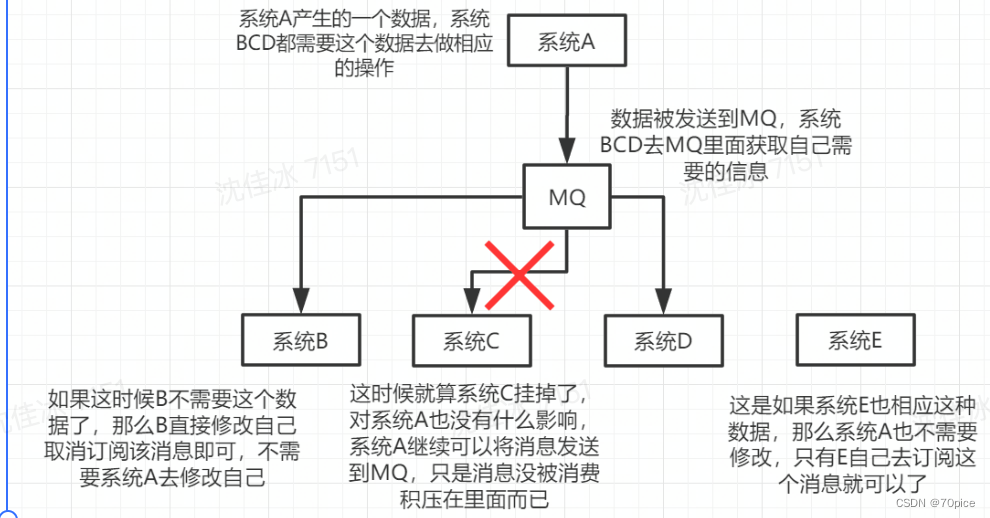
- 异步处理
针对不需要立即处理消息,尤其那种非常耗时的操作,通过消息队列提供了异步处理机制,通过额外的消费线程接管这部分进行异步操作处理。
投放无忧的RMQ的使用就是在字节中很经典的。
举个例子,拿Loan来举例,首先用户申请放款,而银行那边是一个比较慢的操作,不可能让用户一直在等待银行那边的反馈,投放无忧是一个定时任务定时同步银行的放款结果,对于结果是写入db的,再使用一个RMQ去处理这个放款结果。其实在字节中常用的方法,对于这种异步处理一般使用cronjob一般就是RMQ,其实对于cronjob这件事也能做,但是举一个id=4的例子,可能上一个cronjob正在对这个id=4的例子处理,而下一个cronjob也进行了处理这就出问题了,而RMQ就不存在这个情况。 - 削峰
非常形象,高峰进入缓存,然后一个个拿出来消费
MQ模式
- 点对点模式:就跟一个信箱一样,消费拿到了消息就消费,消费完的消息不存在在原本的队列中
- 订阅发布模式:有多个topic,订阅了topic就能消费其中的消息。自身或者在服务端维护offset
RocketMq基本概念
- topic:一类消息的集合,每个主题包含若干信息,每个信息只能属于一个topic。一个topic
- broker:实际上存储topic信息的物理机,一个broker可以存储多个topic的数据,一个topic也可以切片分到多个broker中去
- NameServer:功能类似zookeeper,负责存储broker实际的ip地址,consumer是否可用,类似这种信息。
- pushConsumer:推动式消费,broker收到消息会主动给你发消息
- pullConsumer:拉去式消费,consumer自己去broker上拉消息。RocketMq提供的pushConsumer本质上也是pullConsumer
- 消费者组:消费逻辑一致且订阅了同一个topic的消费者。RocketMq支持,集群式消费和广播消费
- 集群消费:消息被平均分给所有消费者组中的某一个消费者
- 广播消费:一个消费者能接受到所有消息
- 普通顺序消费:一个topic存在在不同的broker上,每一个broker上消费的消息保证有序,broker之间的消息消费不保证有序。
- 严格顺序消费:消息都是有序的。
- Message:发送的消息
- tag:就是一个topic下的消息的分类
- 重点提示broker1 broker2中queue0的消息不同。
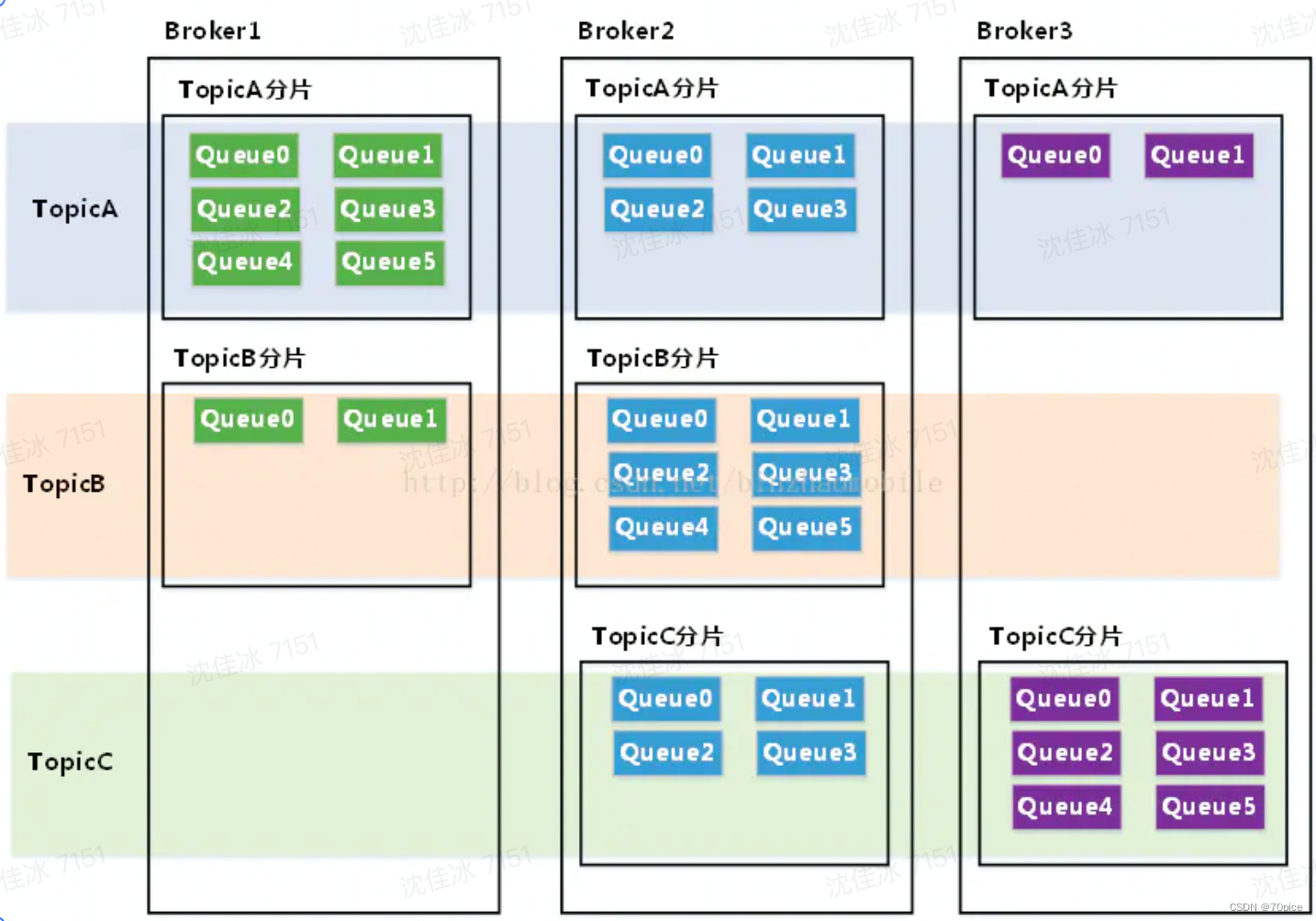
rebalance机制的触发
- 为什么需要rebalance?
以RocketMq举例,queue和consumer是多对一的关系,通常希望queue能被平均的分配给consumer,让整个系统有比较好的并发量,所以当- 有消费者宕机/加入
- queue增加/减少的时候,都会触发rebalance
- rebalance带来的好处,queue按照比较合理的方式分配给各个消费者
- rebalance的坏处
- 在rebalance阶段,消费者是不可用的,所以会造成消息的挤压
- 而在重新启动的时候消息又会比较多的发过来,形成消费突刺。
- 可能会造成offset的丢失,造成重复消费
RocketMq的rebalace
rebalance只会发生在消费者组
- broker端维护的信息,consumer会定期向每一个broker发送自身的一些信息
- TopicConfigManage:管理队列的信息
- ConsumerManage:维护客户端信息
- ConsumerOffsetManager:维护offset信息
- 当管理的队列或者客户端发生了变动,就会发出rebalance信号通知rebalance。重新连接上的生产者,接着上次的offset继续消费。
- 因为是消费者自己去给自己分配队列,因此可能会出现短暂脑裂的问题,但是由于客户端会经常发送rebalance信号,因此这个问题会被解决,这就要通过幂等来解决。
RocketMq是如何保证消息的可靠性的
-
在发送端
- 同步发送:发送完阻塞线程,等待broker端返回ACK。根据返回的结果判断是否需要重复发送。这个模式下可能会出现消费重复投递,需要在消费端做好幂等。
- 异步发送:生产者发送完成之后,并不阻塞自身,而是直接返回,等待回调函数发送结果,判断是否需要重复投递。
- 单向发送:类似于UDP发送之后就不管了,不在乎broker能否收到消息
-
在broker端:
- 刷盘机制
- 同步刷盘:消息写入pageCache的时候,立刻通知刷盘线程刷盘,刷盘线程执行完成后,唤醒等待线程返回消息写成功的ACK。吞吐量比较大
- 异步刷盘:RMQ默认的刷盘机制,消息写入到内存的 PageCache中,就立刻给客户端返回写操作成功,当 PageCache中的消息积累到一定的量时,触发一次写操作,或者定时等策略将 PageCache中的消息写入到磁盘中。这种方式吞吐量大,性能高,但是 PageCache中的数据可能丢失,不能保证数据绝对的安全。
- 且在broker端会经常删除文件,保证磁盘水平的稳定性,防止因为磁盘不足导致写入失败
- 主从复制:
- 同步复制:消息传送到Master上后,全部slave更新完毕才算成功。
- 异步复制:消息传送到Master上就算成功
- 刷盘机制
-
消费端的可靠性
-
消费消息确认机制有两种
1. 先提交后消费,消息可能会丢失,但是不会重复消费
2. 先消费后提交(默认),由各自的consumer业务方保证幂等 -
消费重试:
1. 返回CONSUME_SUCCESS表示消费成功,其余表示CONSUME_LATER会间隔时间再消费。重试16次还没有消费成功会进入死信队列
2. 死信队列:进入死信队列的消息不会直接被销毁,会提供用户一些api
Pull和Push
在RocketMq中,Push是伪装了的Pull
- Push和Pull
- Pull:客户端拉去消息消费,不用太在意客户端的消费速率,缺点是实时性不好。
- Push:由broker端去发送消息给客户端,优点是实时性比较好,缺点是对服务器压力比较大,要考虑消费者的速率,要考虑消息消费失败等问题。
- 在RocketMq中Push是伪装了的Pull
轮询:消费者定期定时间去broker端拉去信息
长轮询:消费者定期去broker上拉取信息,如果没有信息,不返回,这个请求会被装入一个队列,等到有数据来的时候返回。
Push就是简历在长轮询上的Pull
RocketMq的文件存储
Kafka部分
RocketMq的文件存储系统要对比这Kafka一起来看。
首先介绍Kafka的文件存储系统
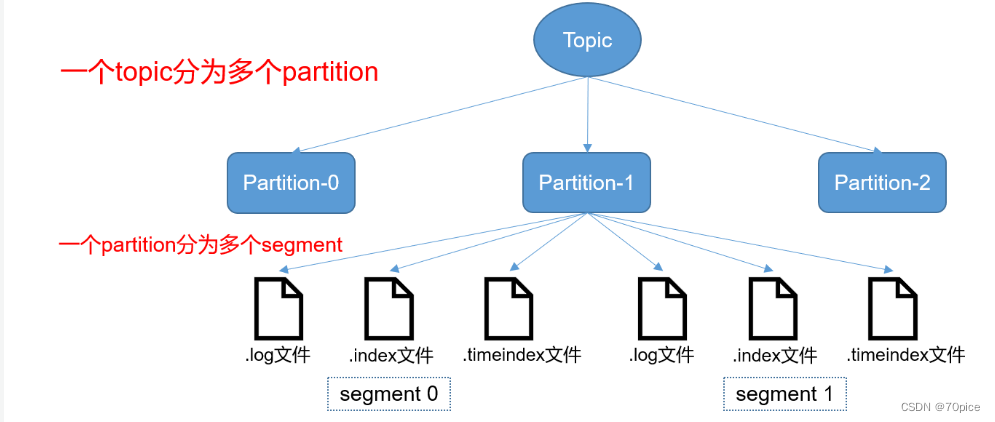
- Kafka是多文件存储,优点有
- 首先Kafka对于单文件都是顺序写的,顺序写文件比随机写入快很多。但是从宏观上来讲,随着Topic增加,Partition增加,Kafka从宏观将是随机写入的。
- 对于历史数据删除比较容易。如果一个Partition部分成多个Segement对于之前的信息删除比较麻烦。
- 在kafka中.index文件相当于索引用于定位.log文件相当于数据文件。
- Kafka生产者消息落入Broker端用了mmap技术,在Broker端到消费者端用了零拷贝技术中的sendfile,提升了性能
- Kafka在发送端会合并信息一起传递
- Kafka运用了PageCache和PageCache预读取的功能
RocketMq部分
- 困扰我很久弄不灵清的一个点Message Queue和Consumer Queue.
- Message Queue和Topic对应的,是Topic下的一个队列
- ConsumerQueue和Commit Log对应,相当于一个索引文件(index文件)
- RocketMq是单文件存储,所有信息都存放在Conmmit Log文件中。这个文件超过1G就重新开一个新文件写。
- RocketMq用到的零拷贝技术是mmap
RocketMq Vs Kafka
- RocketMq用了长轮询,所以RocketMq的实时性要高于Kafka
- Kafka发送消息前会合并,因此吞吐量会大于RocketMq
- 随着Topic增加Partition增加,Kafka会从宏观上退化成随机读写,而RocketMq不会。但是Kafka因为分了多文件,所以比RocketMq更加灵活一些。
RocketMq的顺序消费
在RokcetMq中做一个顺序消费
- 生产者按顺序投递:可以通过一致性哈希,根据消息的特点,比如根据订单号,把一个订单的数据发送到一个Message Queue中
- 消费者按顺序消费,消费者消费的时候不能并发消费,用单线程消费,可以保证这个消息被安全的按顺序消费了。或者使用分布式锁,在消费者消费同一组消息的时候把这个queue锁住。
分布式锁
- 基于数据库的分布式锁:获取资源的时候加一条有唯一键的数据,使用完放弃时,就删除。
- 基于缓存redis的分布式锁
- 基于zookeeper
RocketMq的offset和重复消费
消息的重复消费
对于一个MQ系统做到只投递一次,和只消费一次是很困难的,我们难免会遇到重复消费的问题。
重复消费分为
- 生产者重复投递
- 消费者重复消费,当消费者因为宕机或者rebalanced导致offset丢失,导致重复消费
如何解决 - 业务幂等:对于这条消息消费一次和消费多次都是相同的。
- 消息去重:对于消费过的消息就不再消费了,比如可以针对这个消费过的消息,在数据库中落库,如果insert不成功的消息就不能消费。
offset
- 广播消费:offset是由消费本地维护,定期写入broker中去
- 集群消费:由broker维护offset
重研RocketMq和Kafka的文件存储机制
Kafka的文件存储机制
- Topic
- Partition1、Partition2…
- segment1、segment2…
- .index、.log、.timeindex
- segment1、segment2…
- Partition1、Partition2…
RocketMq的文件存储机制
2. Topic
1. commitLog、consumerQueue、indexFile
2. consumeQueue是基于topic查询,配合offset查询
3. indexFile基于时间、key查询,维度不同
-
两者都是顺序写入,顺序写入只要追加即可速度很快,但是Kafka随着topic的增加partition的增加,因为kafka是多文件顺序写入,全局来看还是随机写入。
-
kafka的吞吐量要大于rocketMq
- Kafka是多文件存储,吞吐量大一点
- Kafka在发送端会合并消息,所以吞吐量大一点
-
RocketMq的实时性要好一些。因为他采用了长轮询的方式
-
offset的存储
- 广播消费,每一个消费者能消费到topic所有的信息,offset是每一个消费者自己维护的
- 集群消费,消息平均分配个每一个消费者。每一个queue都对应一个消费者,所以offset是维护在broker端的。
- offset分为同步提交:消费者消费完毕之后等待broker更新offset期间阻塞自身。
- offset异步提交:消费者提交offset更新请求后不阻塞自身,等待回调函数。















 616
616











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









