







众所周知,目前使用elasticsearch进行模糊搜索时,主要有2种方式
第一种:使用wildcard 关键字 + 未分词的字段进行搜索
第二种:使用match_phrase + 分词的方式进行搜索
对于这两种搜索,效率和性能上有什么区别呢?我们通过jmeter来压测下性能。
测试的服务器指标: 1C 2G
1、创建es的index
自定义一个分词器(分词器将一个文本分割成单个字符),并且一个字段(address)使用自定义分词器分词,一个字段(addressNoAnalysis)不分词,分词的字段用来校验match_phrase,不分词的字段用来校验wildcard。
如下
PUT /ngram_esapi
{
"settings":{
"analysis": {
"analyzer": {
"charSplit": {
"type": "custom",
"tokenizer": "my_ngram_tokenizer",
"filter": [
"lowercase"
],
"char_filter": [
"html_strip"
]
}
},
"tokenizer": {
"my_ngram_tokenizer": {
"type": "nGram",
"min_gram": "1",
"max_gram": "1",
"token_chars": [
"letter",
"digit",
"punctuation"
]
}
}
}
},
"mappings":{
"ngram_person":{
"properties":{
"id": {
"type": "long"
},
"age": {
"type": "integer"
},
"name": {
"type":"text",
"analyzer":"charSplit"
},
"address": {
"type":"text",
"analyzer":"charSplit"
},
"addressNoAnalysis": {
"type":"keyword"
}
}
}
}
}
2:随机生成500万个人员信息数据,插入到es中
for (int i = 0; i < 50000; i++) {
threadPoolExecutor.execute(() -> {
List<Person> persons = new ArrayList<>();
for (int j = 0; j < 100; j++) {
Person person = new Person();
person.setName(ChineseNameGenerator.getInstance().generate());
person.setAge(ThreadLocalRandom.current().nextInt(100));
person.setAddress(ChineseAddressGenerator.getInstance().generate());
persons.add(person);
}
personService.createDatas(persons);
try {
esService.createDatas(persons);
} catch (Exception e) {
log.error(e.getMessage(), e);
}
});
}
return "success";
3:编写接口,通过wildcard的 方式查询数据
public List<Person> searchByWildcard(String keyword, String index, String type) throws Exception {
SearchQuery searchQuery = new NativeSearchQuery(QueryBuilders.wildcardQuery("addressNoAnalysis", String.format("*%s*", keyword)));
return elasticsearchTemplate.queryForList(searchQuery, Person.class);
}
4:编写接口,通过match_phrase的方式查询数据
public List<Person> searchByNgramSearch(String keyword, String index, String type) throws Exception {
SearchQuery searchQuery = new NativeSearchQuery(new MatchPhraseQueryBuilder("address", keyword));
List<Person> personList = elasticsearchTemplate.queryForList(searchQuery, Person.class);
return personList;
}
5:使用jmeter压测 wildcard的接口,并发数10个
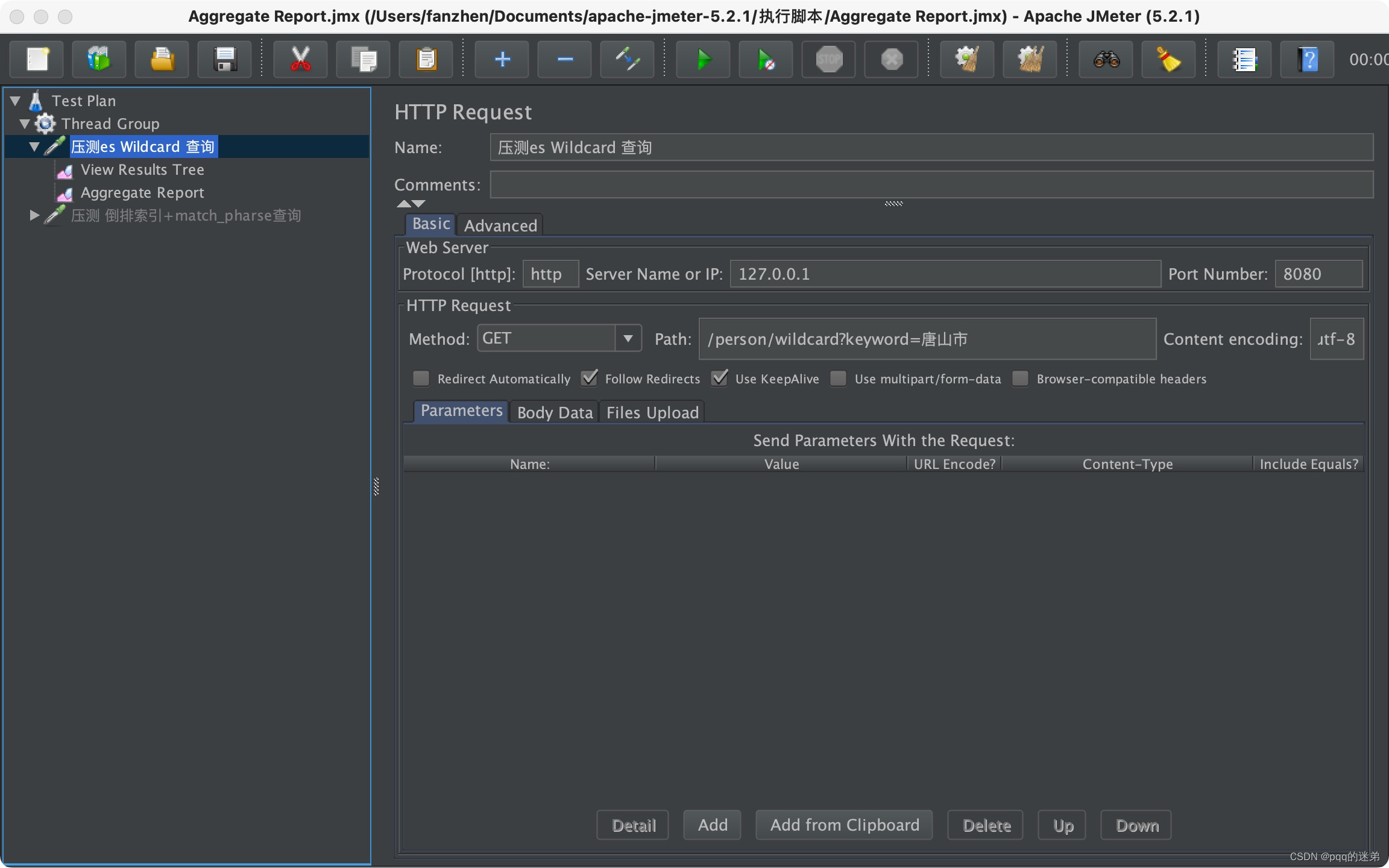
服务器指标:

接口响应:
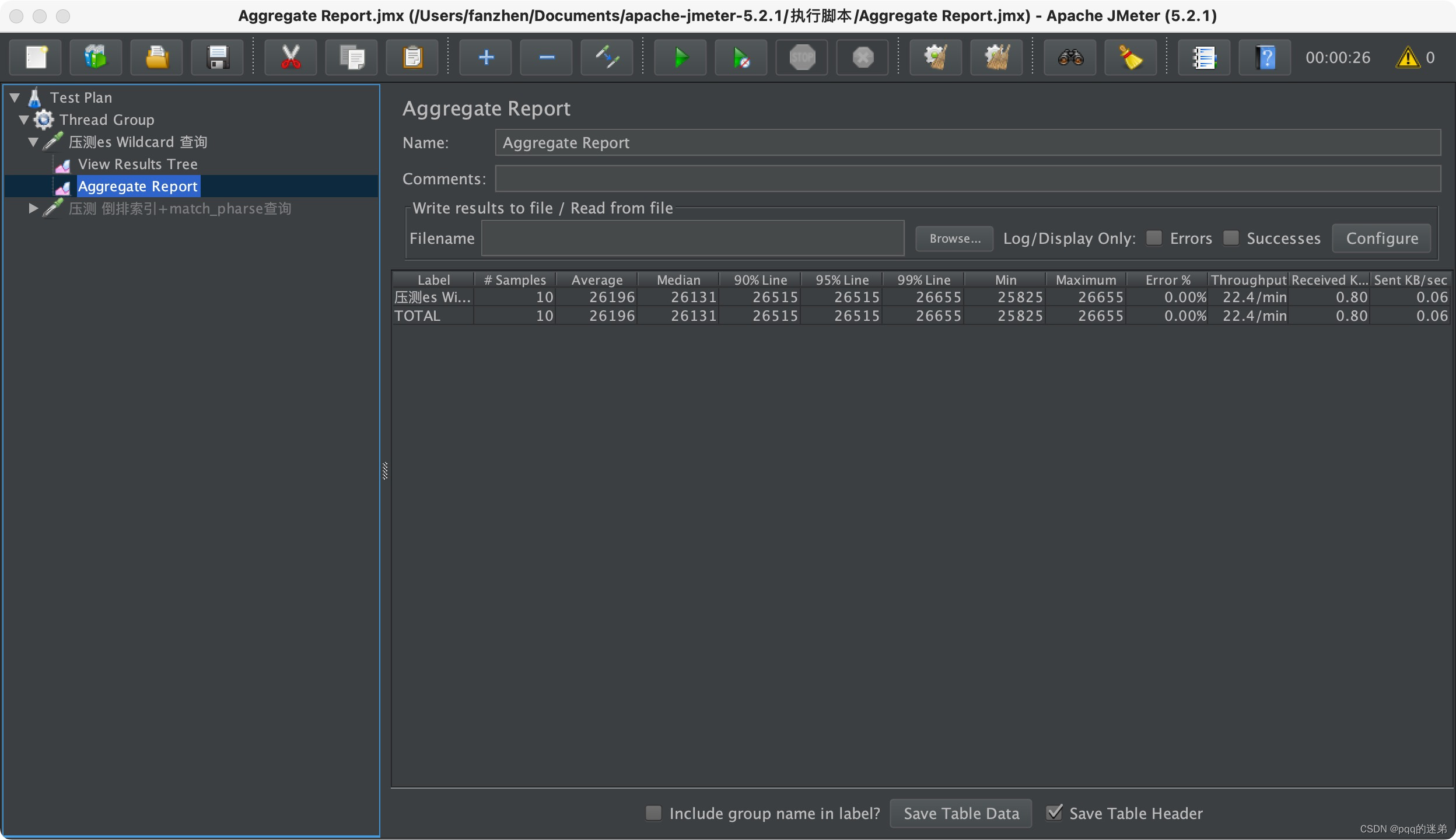
6:使用jmeter压测match_phrase的接口,并发个数10
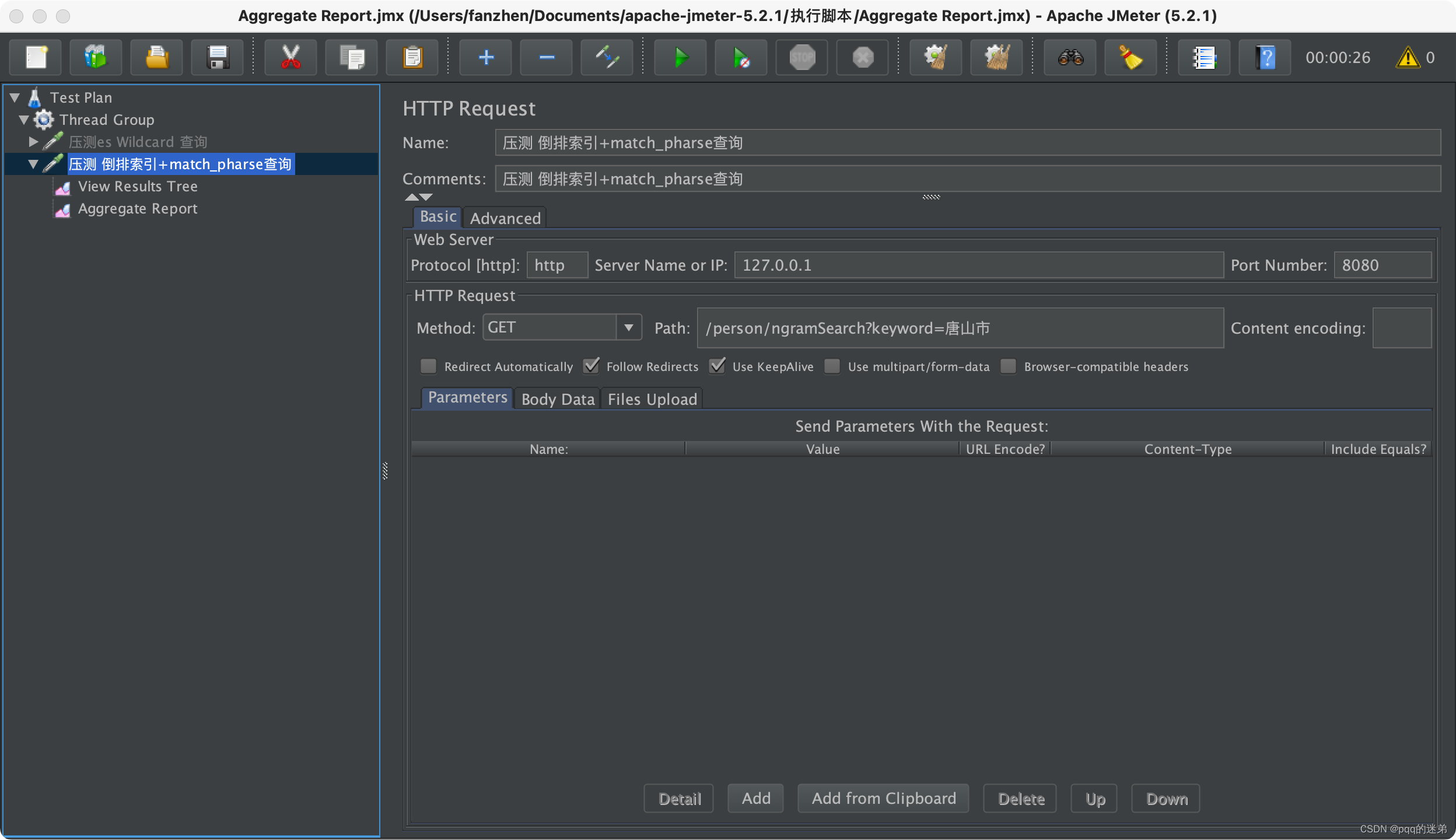
服务器的指标:

接口响应:
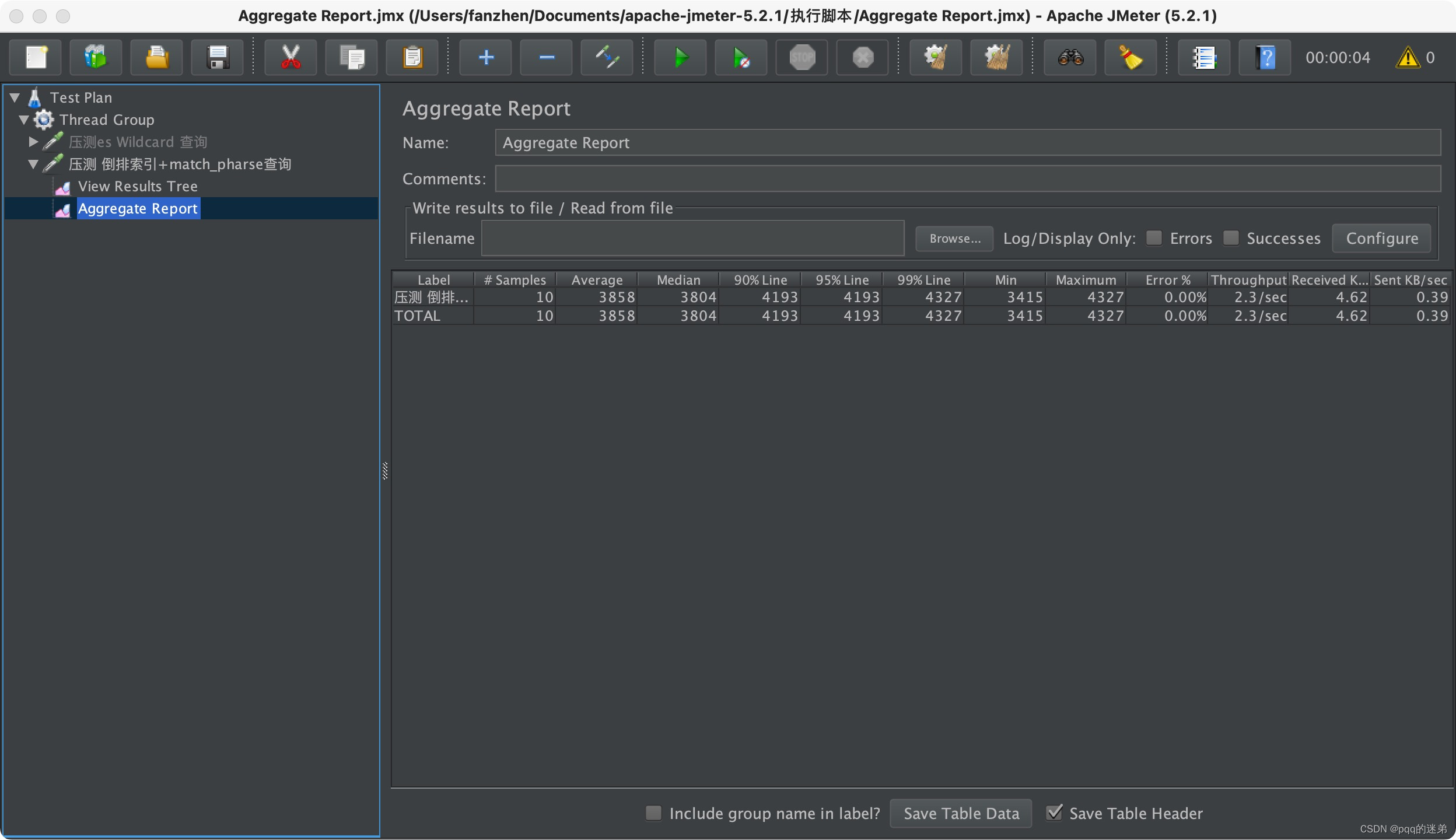
结论:
可以看得出来使用第二种方式,无论是在性能上还是在服务器的压力上都明显优于第一种。
测试的代码已经上传到github上,感兴趣的同学可以自己去下载尝试
https://github.com/fanz1/esapi/tree/master















 2877
2877











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









