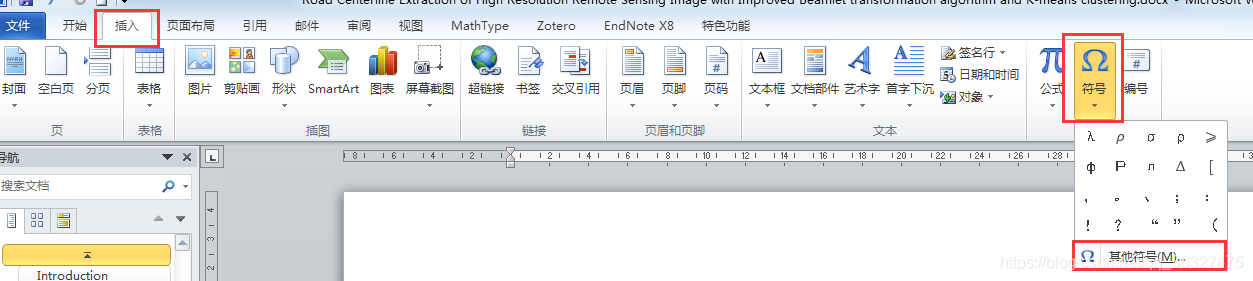
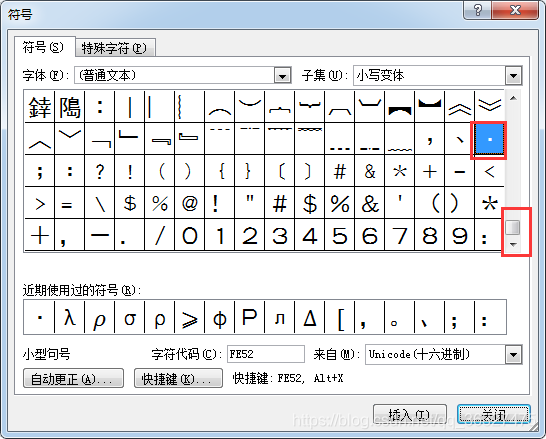
写论文时在作者栏有时需要在两个名字中间加入点,自己琢磨了一下,可以通过以下流程实现: 1)在Word中点击“插入”——“符号”——“其他符号” 2)在符号列表中下拉,找到所需要的点状符号(大致位置在后面,注意是正中间点)。 3)结果








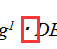

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言






