







内存管理
虚拟内存
我们程序所使⽤的内存地址叫做虚拟内存地址(Virtual Memory Address)
实际存在硬件⾥⾯的空间地址叫物理内存地址(Physical Memory Address)
操作系统引⼊了虚拟内存,进程持有的虚拟地址会通过 CPU 芯⽚中的内存管理单元(MMU)的映射关
系,来转换变成物理地址,然后再通过物理地址访问内存
1.操作系统是如何管理虚拟地址与物理地址之间的关系?
主要有两种⽅式,分别是内存分段和内存分⻚,分段是⽐较早提出的,我们先来看看内存分段。
程序是由若⼲个逻辑分段组成的,如可由代码分段、数据分段、栈段、堆段组成。不同的段是有不同的属
性的,所以就⽤分段segmentation的形式把这些段分离出来。
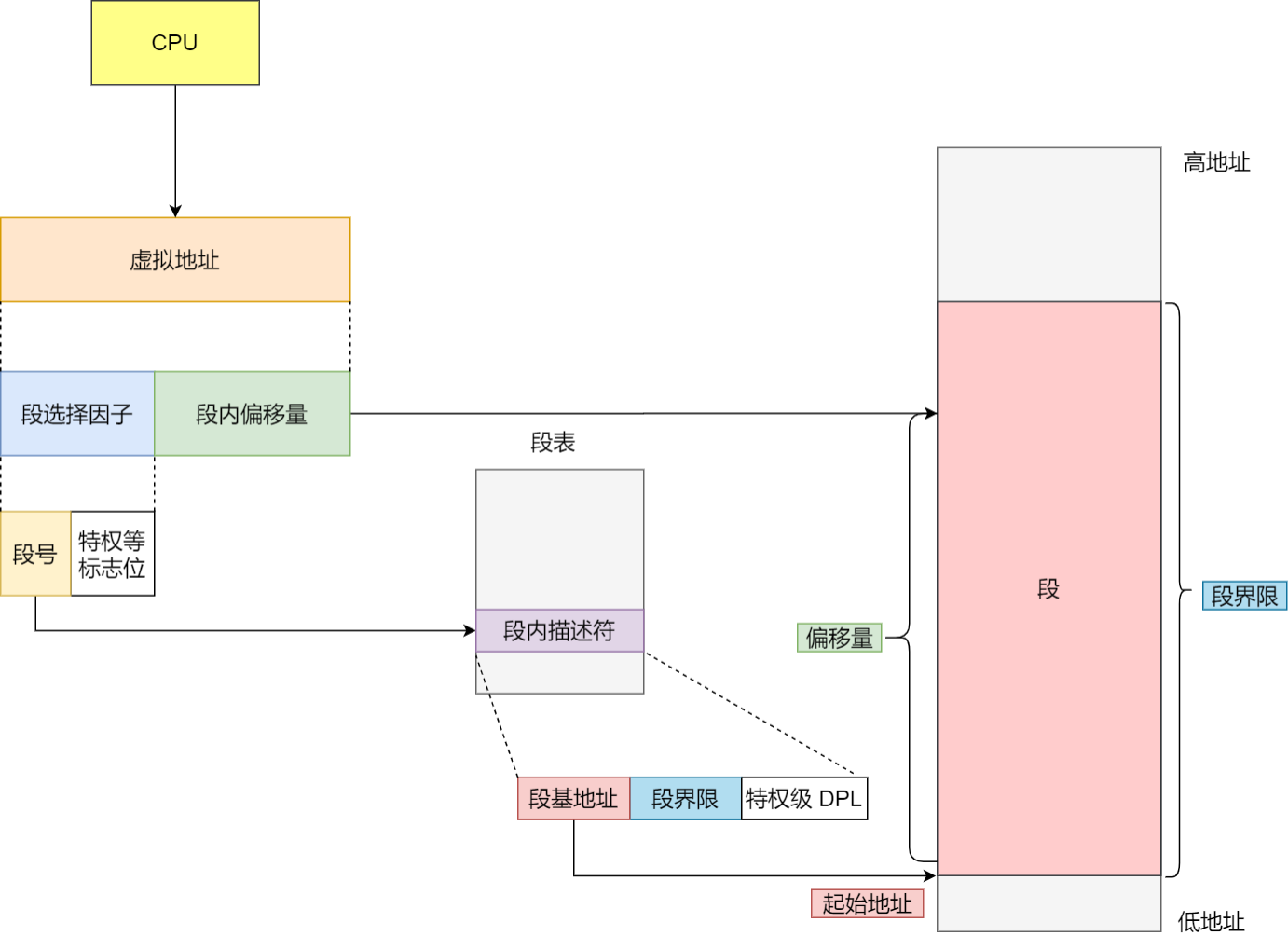
2.分段机制下,虚拟地址和物理地址是如何映射的?
分段机制下的虚拟地址由两部分组成,段选择⼦和段内偏移量
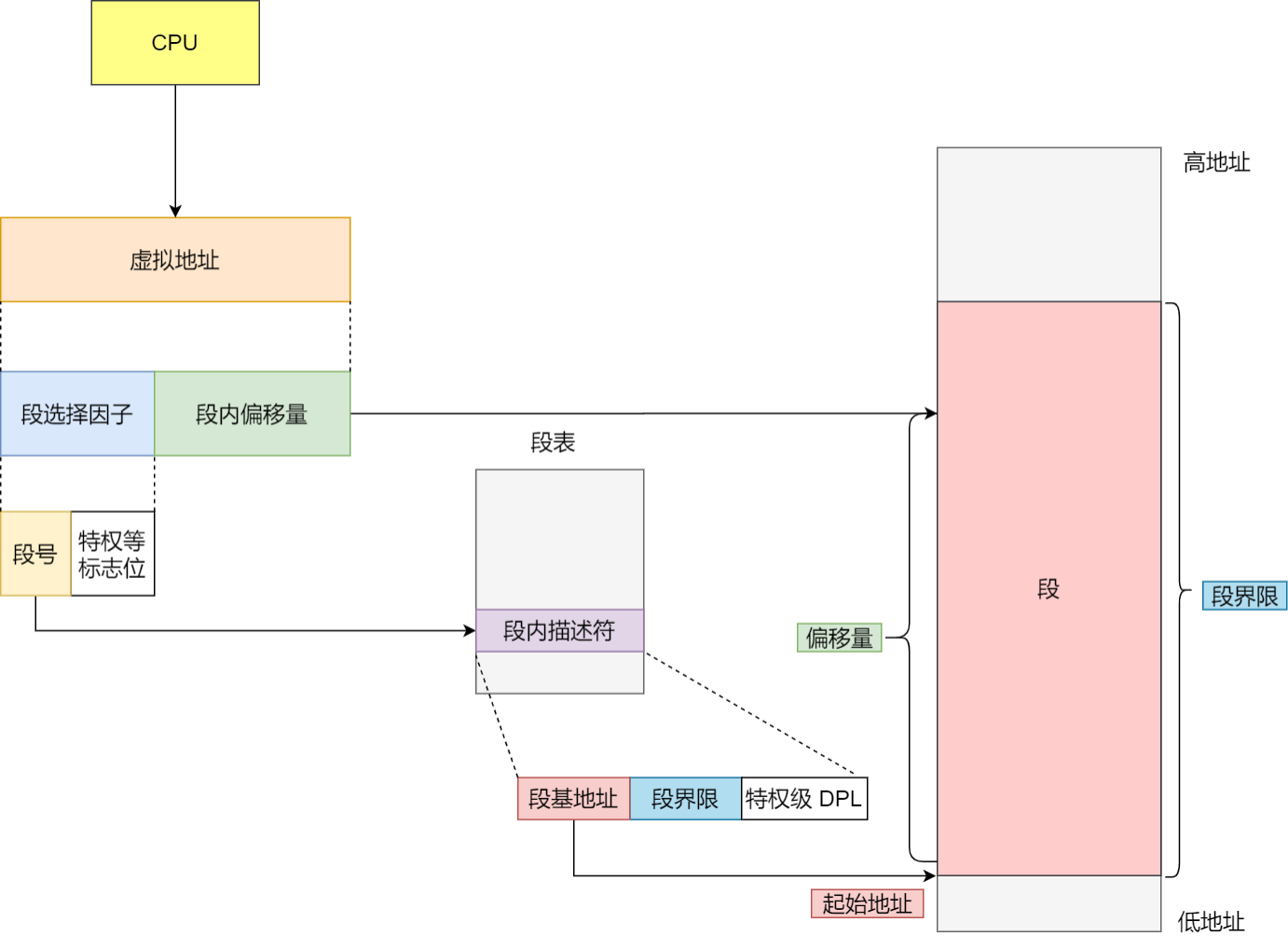
段选择⼦就保存在段寄存器⾥⾯。段选择⼦⾥⾯最重要的是段号,⽤作段表的索引。段表⾥⾯保存的
是这个段的基地址、段的界限和特权等级等。
虚拟地址中的段内偏移量应该位于 0 和段界限之间,如果段内偏移量是合法的,就将段基地址加上段
内偏移量得到物理内存地址。
知道了虚拟地址是通过段表与物理地址进⾏映射的,分段机制会把程序的虚拟地址分成 4 个段,每个段在段表中有⼀个项,在这⼀项找到段的基地址,再加上偏移量,于是就能找到物理内存中的地址,
分段的办法很好,解决了程序本身不需要关⼼具体的物理内存地址的问题,但它也有⼀些不⾜之处:
第⼀个就是内存碎⽚的问题。
第⼆个就是内存交换的效率低的问题。
解决外部内存碎⽚的问题就是内存交换。这个内存交换空间,在 Linux 系统⾥,也就是我们常看到的 Swap 空间,这块空间是从硬盘划分出来的,⽤于内存与硬盘的空间交换。
3.分段为什么会导致内存交换效率低的问题?
对于多进程的系统来说,⽤分段的⽅式,内存碎⽚是很容易产⽣的,产⽣了内存碎⽚,那不得不重新
Swap 内存区域,这个过程会产⽣性能瓶颈。因为硬盘的访问速度要⽐内存慢太多了,每⼀次内存交换,我们都需要把⼀⼤段连续的内存数据写到硬盘
上。所以,如果内存交换的时候,交换的是⼀个占内存空间很⼤的程序,这样整个机器都会显得卡顿。
要解决这些问题,那么就要想出能少出现⼀些内存碎⽚的办法。另外,当需要进⾏内存交换的时候,让需
要交换写⼊或者从磁盘装载的数据更少⼀点,这样就可以解决问题了。这个办法,也就是内存分⻚
(Paging)。
分⻚是把整个虚拟和物理内存空间切成⼀段段固定尺⼨的⼤⼩。这样⼀个连续并且尺⼨固定的内存空间,
我们叫⻚(Page)。在 Linux 下,每⼀⻚的⼤⼩为 4KB 。
虚拟地址与物理地址之间通过⻚表来映射,如下图:
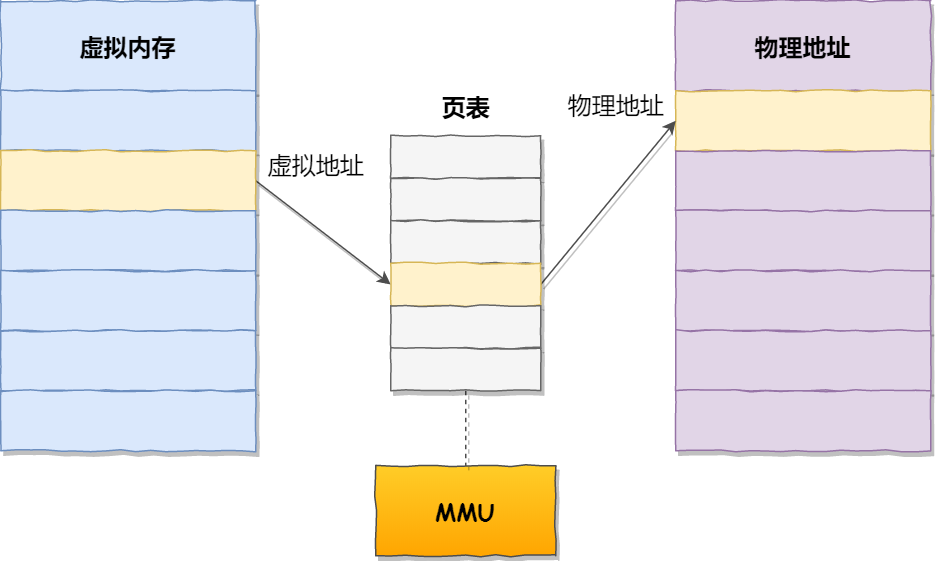
⻚表是存储在内存⾥的,内存管理单元 (MMU)就做将虚拟内存地址转换成物理地址的⼯作
⽽当进程访问的虚拟地址在⻚表中查不到时,系统会产⽣⼀个缺⻚异常,进⼊系统内核空间分配物理内
存、更新进程⻚表,最后再返回⽤户空间,恢复进程的运⾏。更进⼀步地,分⻚的⽅式使得我们在加载程序的时候,不再需要⼀次性都把程序加载到物理内存中。我们
完全可以在进⾏虚拟内存和物理内存的⻚之间的映射之后,并不真的把⻚加载到物理内存⾥,⽽是只有在
程序运⾏中,需要⽤到对应虚拟内存⻚⾥⾯的指令和数据时,再加载到物理内存⾥⾯去。
4.分⻚是怎么解决分段的内存碎⽚、内存交换效率低的问题?
由于内存空间都是预先划分好的,也就不会像分段会产⽣间隙⾮常⼩的内存,这正是分段会产⽣内存碎⽚
的原因。⽽采⽤了分⻚,那么释放的内存都是以⻚为单位释放的,也就不会产⽣⽆法给进程使⽤的⼩内
存。
如果内存空间不够,操作系统会把其他正在运⾏的进程中的「最近没被使⽤」的内存⻚⾯给释放掉,也就
是暂时写在硬盘上,称为换出(Swap Out)。⼀旦需要的时候,再加载进来,称为换⼊(Swap In)。所
以,⼀次性写⼊磁盘的也只有少数的⼀个⻚或者⼏个⻚,不会花太多时间,内存交换的效率就相对⽐较
⾼。
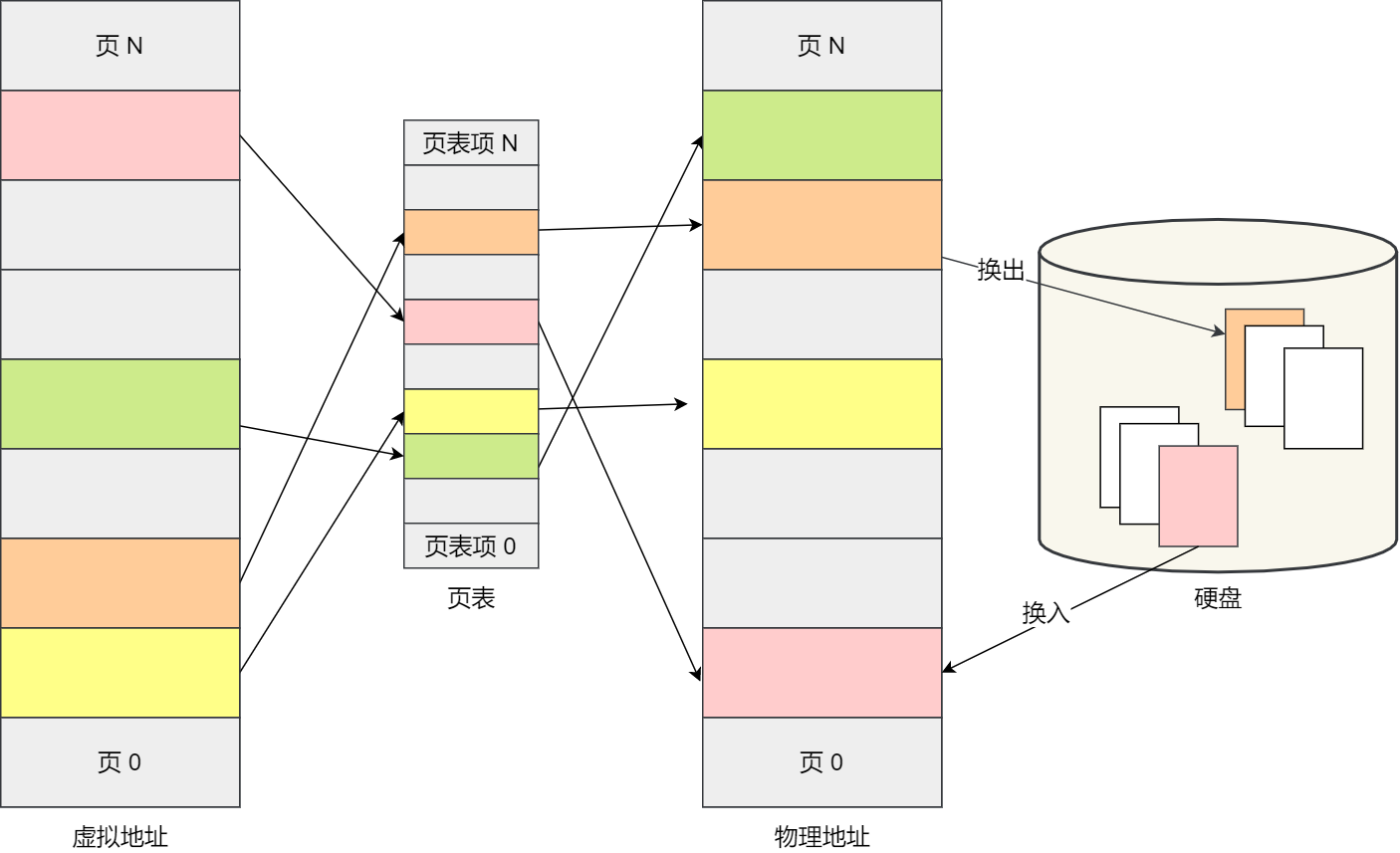
更进⼀步地,分⻚的⽅式使得我们在加载程序的时候,不再需要⼀次性都把程序加载到物理内存中。我们
完全可以在进⾏虚拟内存和物理内存的⻚之间的映射之后,并不真的把⻚加载到物理内存⾥,⽽是只有在
程序运⾏中,需要⽤到对应虚拟内存⻚⾥⾯的指令和数据时,再加载到物理内存⾥⾯去。
5.分⻚机制下,虚拟地址和物理地址是如何映射的?
在分⻚机制下,虚拟地址分为两部分,⻚号和⻚内偏移。⻚号作为⻚表的索引,⻚表包含物理⻚每⻚所在
物理内存的基地址,这个基地址与⻚内偏移的组合就形成了物理内存地址,⻅下图。
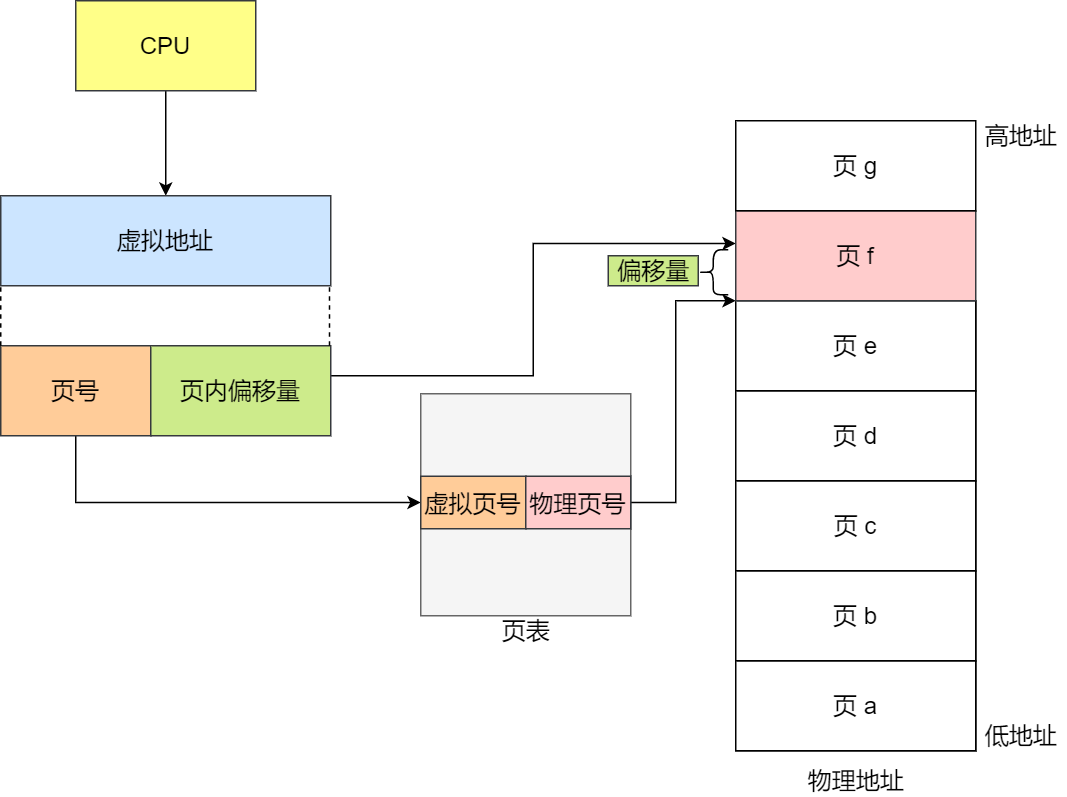
总结⼀下,对于⼀个内存地址转换,其实就是这样三个步骤:
把虚拟内存地址,切分成⻚号和偏移量;
根据⻚号,从⻚表⾥⾯,查询对应的物理⻚号;
直接拿物理⻚号,加上前⾯的偏移量,就得到了物理内存地址
6.简单的分⻚有什么缺陷吗?
有空间上的缺陷。
因为操作系统是可以同时运⾏⾮常多的进程的,那这不就意味着⻚表会⾮常的庞⼤。
在 32 位的环境下,虚拟地址空间共有 4GB,假设⼀个⻚的⼤⼩是 4KB(2^12),那么就需要⼤约 100 万
(2^20) 个⻚,每个「⻚表项」需要 4 个字节⼤⼩来存储,那么整个 4GB 空间的映射就需要有 4MB
的内存来存储⻚表。
这 4MB ⼤⼩的⻚表,看起来也不是很⼤。但是要知道每个进程都是有⾃⼰的虚拟地址空间的,也就说都有
⾃⼰的⻚表。那么, 100 个进程的话,就需要 400MB 的内存来存储⻚表,这是⾮常⼤的内存了,更别说 64 位的环
境了。
要解决上⾯的问题,就需要采⽤⼀种叫作多级⻚表(Multi-Level Page Table)的解决⽅案。
多级⻚表虽然解决了空间上的问题,但是虚拟地址到物理地址的转换就多了⼏道转换的⼯序,这显然就降
低了这俩地址转换的速度,也就是带来了时间上的开销。
程序是有局部性的,即在⼀段时间内,整个程序的执⾏仅限于程序中的某⼀部分。相应地,执⾏所访问的
存储空间也局限于某个内存区域。
我们就可以利⽤这⼀特性,把最常访问的⼏个⻚表项存储到访问速度更快的硬件,于是计算机科学家们,
就**在 CPU 芯⽚中,**加⼊了⼀个专⻔存放程序最常访问的⻚表项的 Cache,这个 Cache 就是 TLB
==(Translation Lookaside Buffer) ,==通常称为⻚表缓存、转址旁路缓存、快表等。
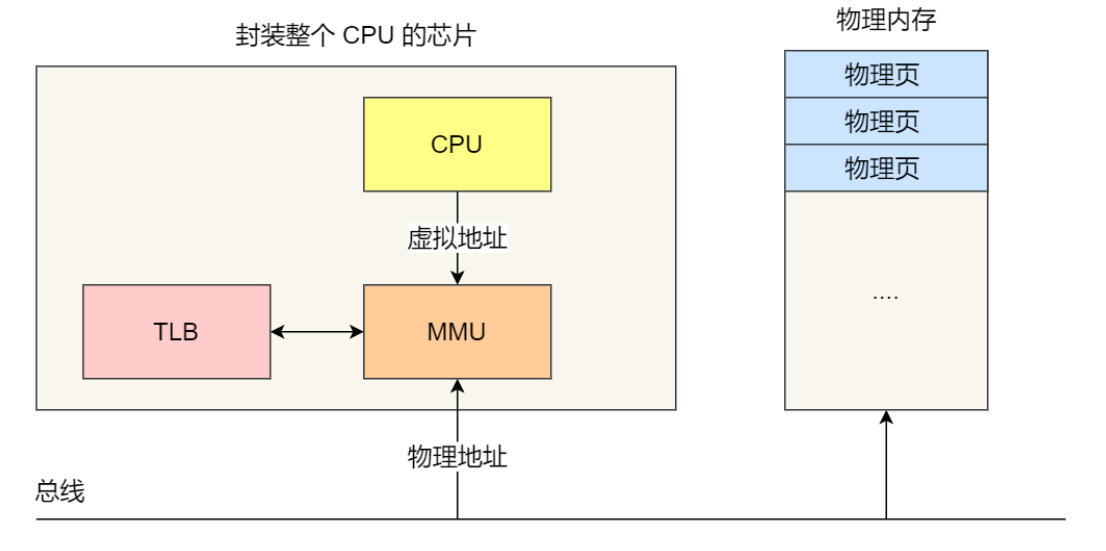
在 CPU 芯⽚⾥⾯,封装了内存管理单元(Memory Management Unit)芯⽚,它⽤来完成地址转换和 TLB
的访问与交互。
有了 TLB 后,那么 CPU 在寻址时,会先查 TLB,如果没找到,才会继续查常规的⻚表。
TLB 的命中率其实是很⾼的,因为程序最常访问的⻚就那么⼏个。
7.Intel 处理器的内存管理发展历史。
早期 Intel 的处理器从 80286 开始使⽤的是段式内存管理。但是很快发现,光有段式内存管理⽽没有⻚式
内存管理是不够的,这会使它的 X86 系列会失去市场的竞争⼒。因此,在不久以后的 80386 中就实现了对
⻚式内存管理。也就是说,80386 除了完成并完善从 80286 开始的段式内存管理的同时还实现了⻚式内存
管理。
但是这个 80386 的⻚式内存管理设计时,没有绕开段式内存管理,⽽是建⽴在段式内存管理的基础上,这
就意味着,⻚式内存管理的作⽤是在由段式内存管理所映射⽽成的地址上再加上⼀层地址映射。
由于此时由段式内存管理映射⽽成的地址不再是“物理地址”了,Intel 就称之为“线性地址”(也称虚拟地
址)。于是,段式内存管理先将逻辑地址映射成线性地址,然后再由⻚式内存管理将线性地址映射成物理
地址。

这⾥说明下逻辑地址和线性地址:
程序所使⽤的地址,通常是没被段式内存管理映射的地址,称为逻辑地址;
通过段式内存管理映射的地址,称为线性地址,也叫虚拟地址;
逻辑地址是「段式内存管理」转换前的地址,线性地址则是「⻚式内存管理」转换前的地址。
8.Linux 采⽤了什么⽅式管理内存?
Linux 内存主要采⽤的是⻚式内存管理,但同时也不可避免地涉及了段机制。
这主要是上⾯ Intel 处理器发展历史导致的,因为 Intel X86 CPU ⼀律对程序中使⽤的地址先进⾏段式映
射,然后才能进⾏⻚式映射。既然 CPU 的硬件结构是这样,Linux 内核也只好服从 Intel 的选择。
但是事实上,Linux 内核所采取的办法是使段式映射的过程实际上不起什么作⽤。也就是说,“上有政策,
下有对策”,若惹不起就躲着⾛。
Linux 系统中的每个段都是从 0 地址开始的整个 4GB **虚拟空间(**32 位环境下),也就是所有的段的起始
**地址都是⼀样的。这意味着,**Linux 系统中的代码,包括操作系统本身的代码和应⽤程序代码,所⾯对的
地址空间都是线性地址空间(虚拟地址),这种做法相当于屏蔽了处理器中的逻辑地址概念,段只被⽤于
访问控制和内存保护。
9.Linux 的虚拟地址空间是如何分布的?
在 Linux 操作系统中,虚拟地址空间的内部⼜被分为内核空间和⽤户空间两部分,不同位数的系统,地址
空间的范围也不同。⽐如最常⻅的 32 位和 64 位系统,如下所示:
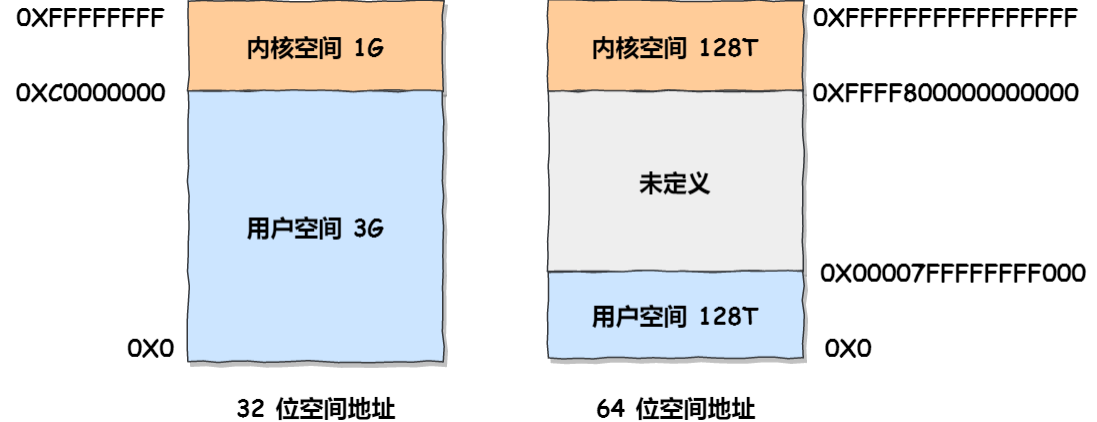
通过这⾥可以看出:
32 位系统的内核空间占⽤ 1G ,位于最⾼处,剩下的 3G 是⽤户空间;
64 位系统的内核空间和⽤户空间都是 128T ,分别占据整个内存空间的最⾼和最低处,剩下的中
间部分是未定义的
,内核空间与⽤户空间的区别:
进程在⽤户态时,只能访问⽤户空间内存;
只有进⼊内核态后,才可以访问内核空间的内存;虽然每个进程都各⾃有独⽴的虚拟内存,但是每个虚拟内存中的内核地址,其实关联的都是相同的物理内
存。这样,进程切换到内核态后,就可以很⽅便地访问内核空间内存。
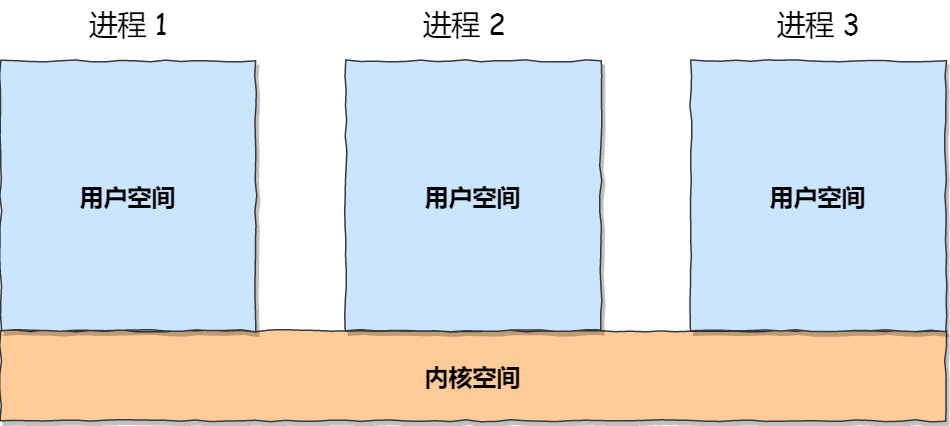
进⼀步了解虚拟空间的划分情况,⽤户空间和内核空间划分的⽅式是不同的,内核空间的分布情
况就不多说了。
我们看看⽤户空间分布的情况,以 32 位系统为例,我画了⼀张图来表示它们的关系:
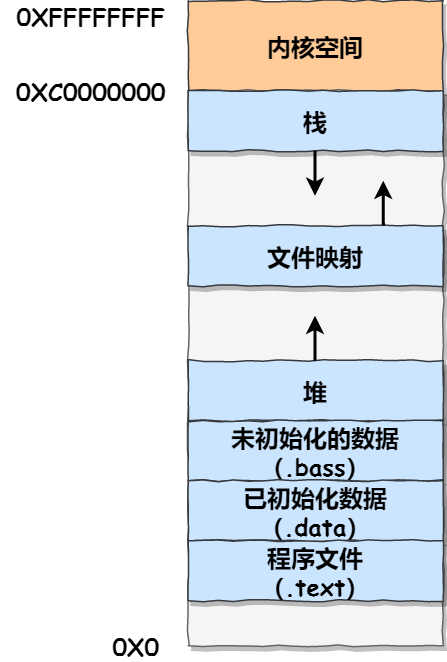
⽤户空间内存,从低到⾼分别是 7 种不同的内存段:
程序⽂件段,包括⼆进制可执⾏代码;
已初始化数据段,包括静态常量;
未初始化数据段,包括未初始化的静态变量;
堆段,包括动态分配的内存,从低地址开始向上增⻓;
⽂件映射段,包括动态库、共享内存等,从低地址开始向上增⻓(跟硬件和内核版本有关);
栈段,包括局部变量和函数调⽤的上下⽂等。栈的⼤⼩是固定的,⼀般是 8 MB 。当然系统也提供
了参数,以便我们⾃定义⼤⼩;在这 7 个内存段中,堆和⽂件映射段的内存是动态分配的。⽐如说,使⽤ C 标准库的 malloc() 或者
mmap() ,就可以分别在堆和⽂件映射段动态分配内存。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









