







ShardingSphere
- 起源当当网内部,开始叫ShardingJDBC
- 2016年被开发张亮带入京东数科
- 2017开始开源,并开始升级成一套以数据分片为基础的生态框架
- 后改名为ShardingSphere
- 2020年4月,以成为Apache顶级项目
- 主要包括三个产品:ShardingJdbc,ShardingProxy、ShardingSidecar(规划中)
- sidecar是针对service mesh的一个分库分表插件
- shardingJdbc主要用作客户端分库分表产品
- shardingProxy用作服务端分库分表产品
shardingJDBC
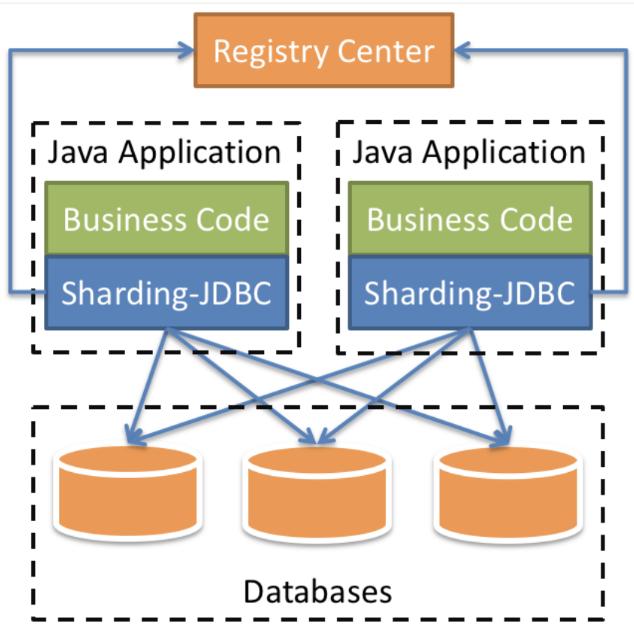
- 轻量级的JAVA框架
- 以jar包方式提供能力,无需额外部署
- 可以理解为增强版JDBC驱动,兼容主流ORM框架
ShardingProxy
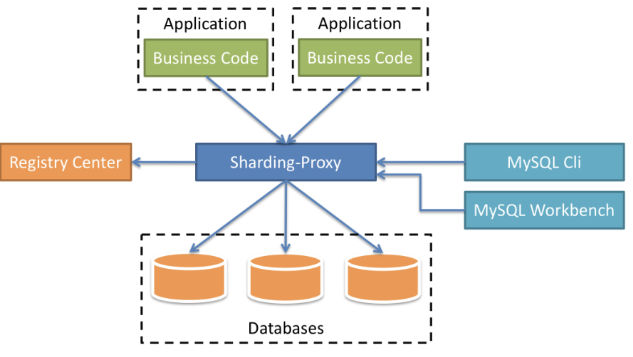
- 定位为透明化数据库代理服务
- 目前支持MySQL与PostgreSQL
- 支持异构应用
ShardingJDBC对比Proxy,一个是客户的一个工具包,一个是独立部署的服务,Proxy更像是Mycat。JDBC对业务侵入大,但相对灵活,支持数据库多。Proxy对业务方无侵入,同时也有较多局限性,支持数据库较少。
ShardingJDBC走起
核心能力
- 数据分片
- 读写分离
相关概念
- 逻辑表、真实表、数据节点、
- 绑定表(分片规则一直的主子表)、广播表(公共表)
- 分片键、分片算法
- 分片策略(键+算法),基于Groovy表达式
如t_user_$->{u_id%8}标识根据u_id模8,分成8张表,表名称为t_user_0到t_user_7
目前5.0版本还在孵化,建议使用4.1.1版本
编码实操
- 配置数据源及逻辑表
- 配置主键生成策略,支持UUID与SNOWFLAKE
- 配置分片策略,指定分片键与分片算法
- 配置日志打印实际SQL
- 其他要点
- 测试分片算法:inline、standard、complex、hint
- 测试广播表、绑定表、读写分离
- 注意:读写分离仅指将读写请求发送到不同数据库上执行,数据同步还是需要MySQL集群来负责
分片算法
- inline分片算法,一个分片键+一个分片表达式,配置简单、灵活,一般场景够用了
- 更复杂场景,如多分片键、按范围分片等,inline不太适合
- Standard策略,复杂场景考虑使用,可指定分片算法类名,自定义实现其分片逻辑
- Complex,支持多分片键,具体算法逻辑指定类自定义
- Hint策略,分片键不和SQL语句关联,而由应用程序另行指定
- 注意Hint有很多局限性,不支持UNION、多层子查询、函数计算等
ShardingJDBC对SQL的限制
- values不支持运算表达式
- select 字句不支持*号简写及内置分布式主键生成器
- distinct场景
- 查询列是函数表达式
- 查询列前不可使用表名点 ……
分库分表带来的问题
- 一般情况,数据容量较大时,优先考虑从缓存技术上着手解决
- 其次,数据库访问压力大,可考虑读写分离策略
- 再其次,再考虑是否可以采用其他分布式数据库产品存储,如es、PG、Hbase、hive等
- 最后,再考虑分库分表
- 分库分表后,对SQL语句有很多限制,很多写法不支持
- 故实际,能不分库分表,尽量不要分
- 如果确定要做,尽可能再系统设计初就开始考虑
- 系统后期再考虑,会带来诸多复杂的数据问题,需谨慎















 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









