







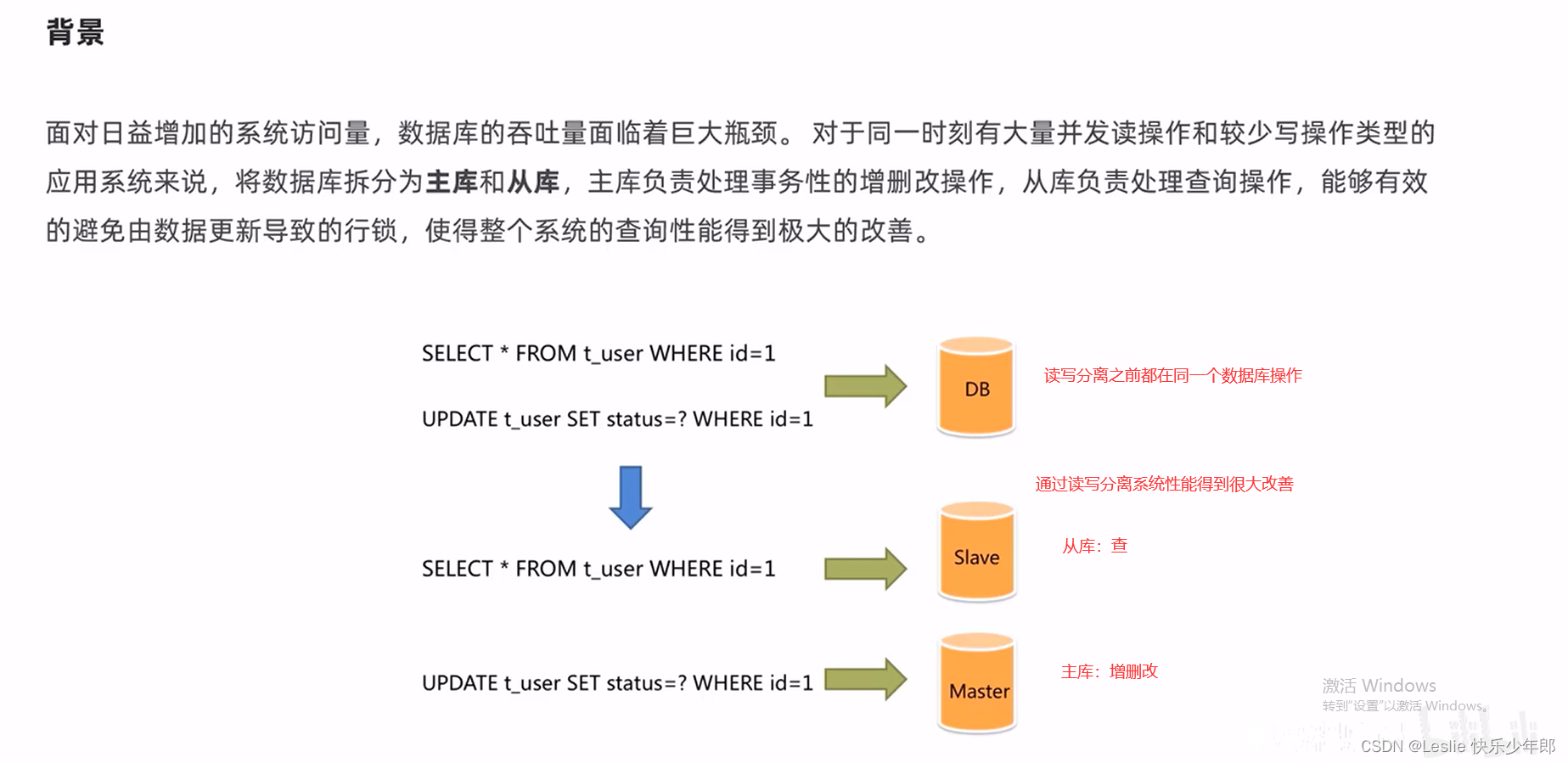
一,背景
二,sharding-JDBC介绍
那如何实现读写分离呢,也就是说程序怎么去判定当前的sql是查询的还是增删改的呢,根据这个sql怎么能找到从库而不是主库呢。
可以通过Sharding-JDBC框架实现
特点:兼容性强,支持任何第三方数据库连接池,支持任意规范的数据库。

三,入门案例
前提:配置好MySQL的主从复制
用一个简单的项目做案例即可。
1,导入坐标
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
2,在yml配置文件中配置读写分离规则
#操作数据库为啥没配置数据源?
#因为要使用sharding-jdbc来充当jdbc层框架,数据源就不用配置了,它有自己的配置
spring:
shardingsphere:
datasource:
names:
master,slave #两个数据源,名字分别是master,slave,名字可以不固定,但是下面的master和slave的字眼要与此处的一致
#主数据源
master:
type: com.alibaba.druid.pool.DruidDataSource
driveer-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.129.128:3306/rw?user=root&password=root&characterEncoding=utf-8
#name: root
#password: root
#从数据源
slave:
type: com.alibaba.druid.pool.DruidDataSource
driveer-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.129.130:3306/rw?user=root&password=root&characterEncoding=utf-8
name: root
password: root
masterslave:
#读写配置分离 从库负载均衡策略,round_robin轮询,当多个从库则按顺序查询
load-balance-algorithm-type: round_robin
#最终的数据源名称 bin的名字
name: dataSource
#主库数据源名称 指定主库的数据源(很明显配置了master为主库)
master-data-source-name: master
#从库数据源名称列表,当多个从库以逗号分隔
slave-data-source-names: slave
props:
sql:
show: true #开启sql显示,默认为false
直接启动项目则会报错
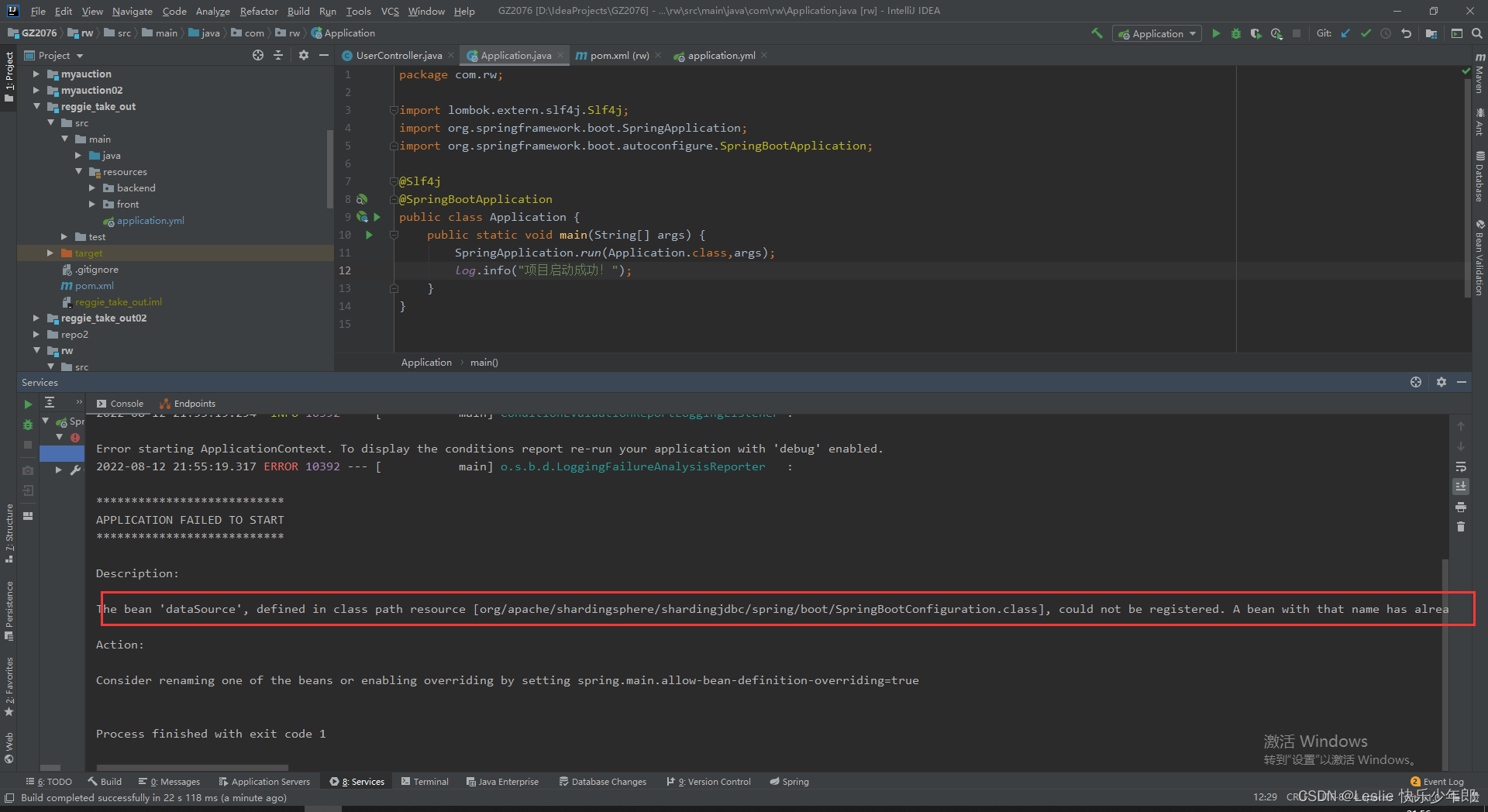
报错信息:The bean 'dataSource', defined in class path resource [org/apache/shardingsphere/shardingjdbc/spring/boot/SpringBootConfiguration.class], could not be registered. A bean with that name has already been defined in class path resource [com/alibaba/druid/spring/boot/autoconfigure/DruidDataSourceAutoConfigure.class] and overriding is disabled.
原因是shardingjdbc的jar包的配置类SpringBootConfiguration 与 druid连接池这个jar包的配置类DruidDataSourceAutoConfigure发生冲突
在shardingjdbc的配置类里要创建一个数据源对象,但是在druid连接池也要创建一个数据源对象,就发生了冲突
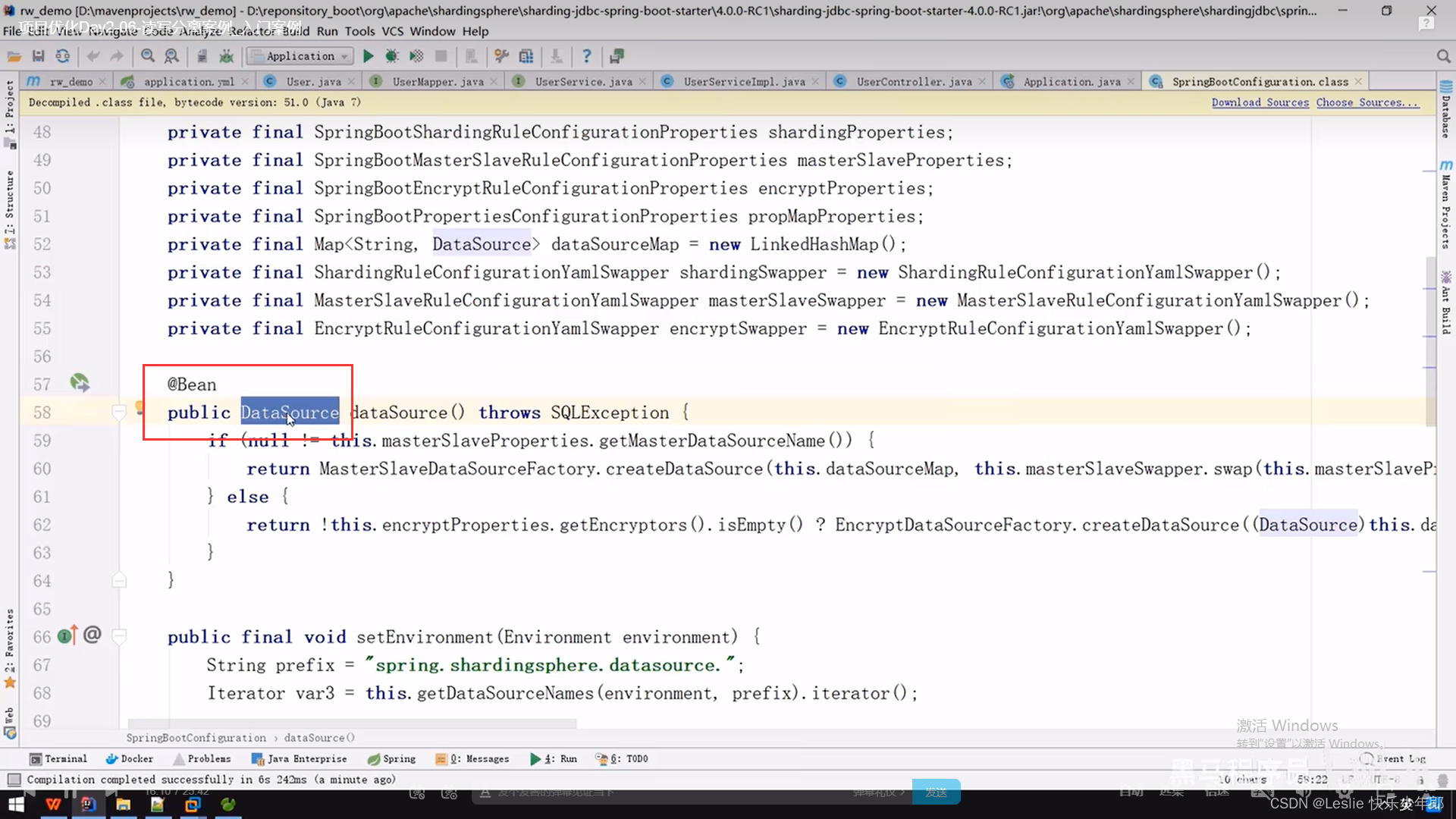
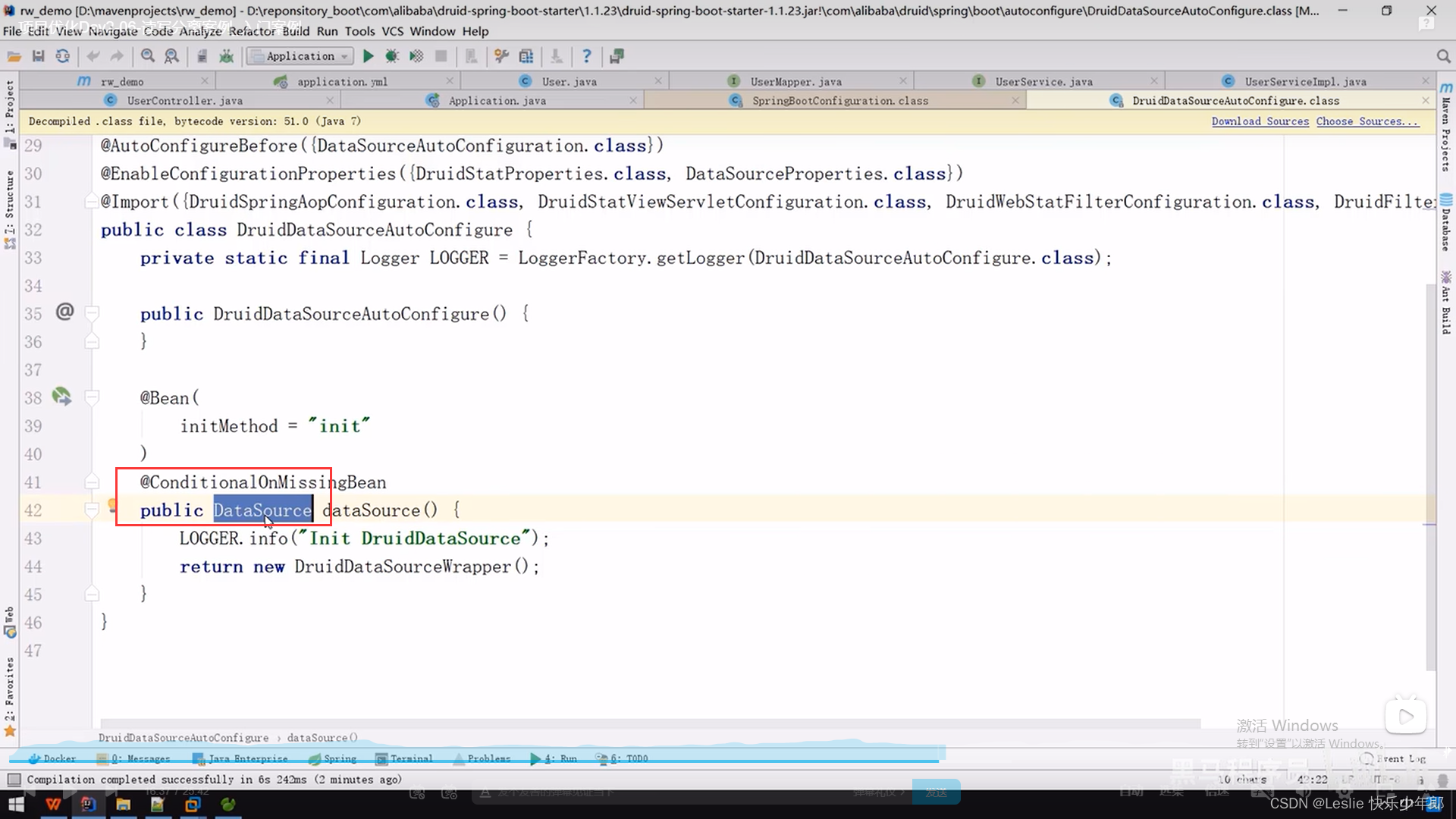
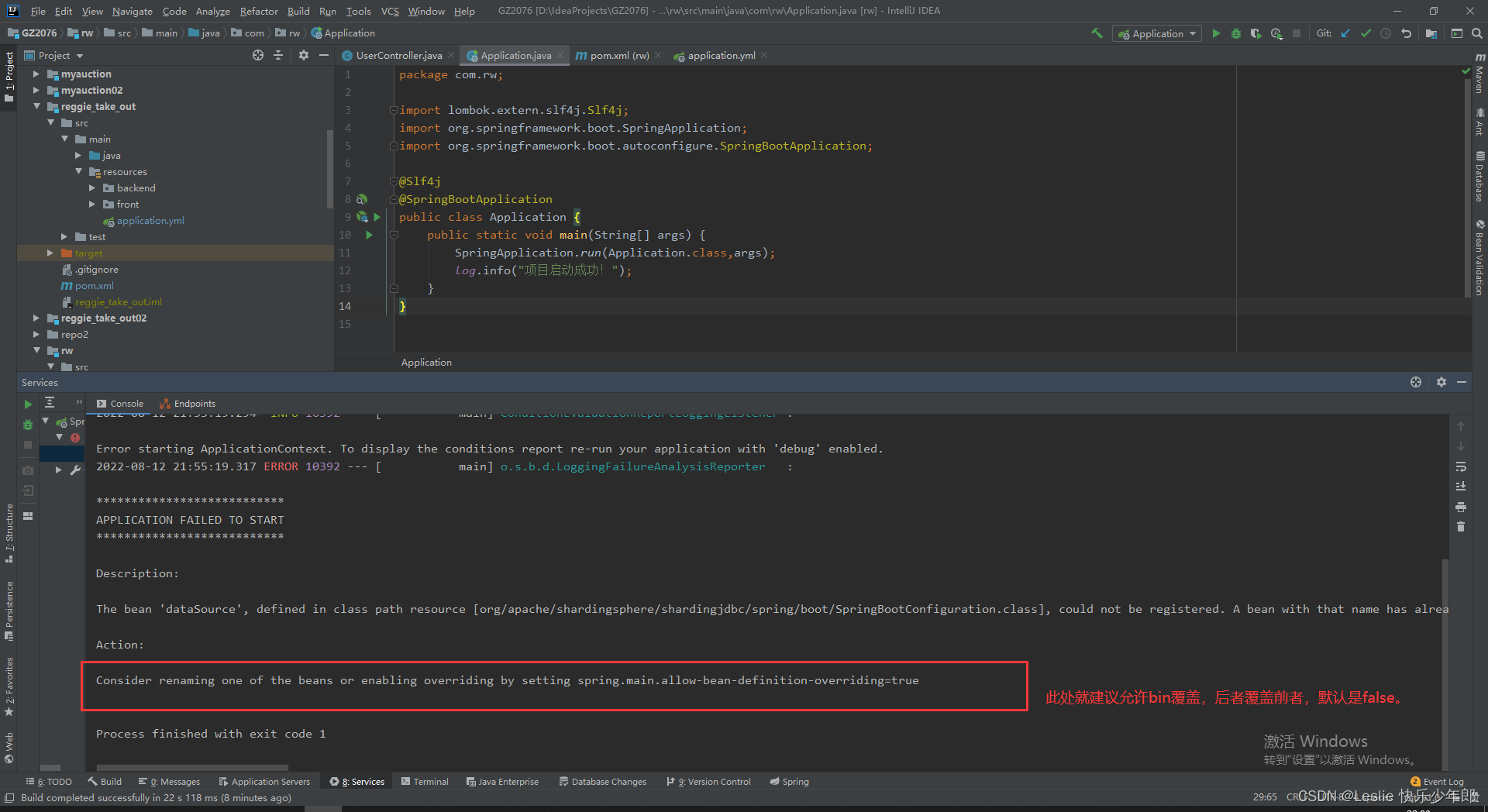
3,在yml配置文件中配置,允许bin定义覆盖
spring下的
main:
allow-bean-definition-overriding: true
配置好之后,就交由框架处理,查询自从库,增删改自主库
四,功能测试
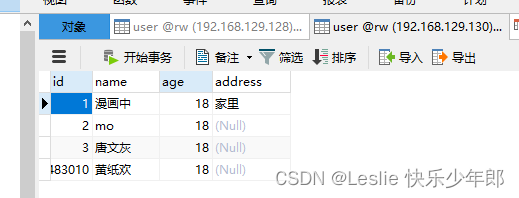
1,增加
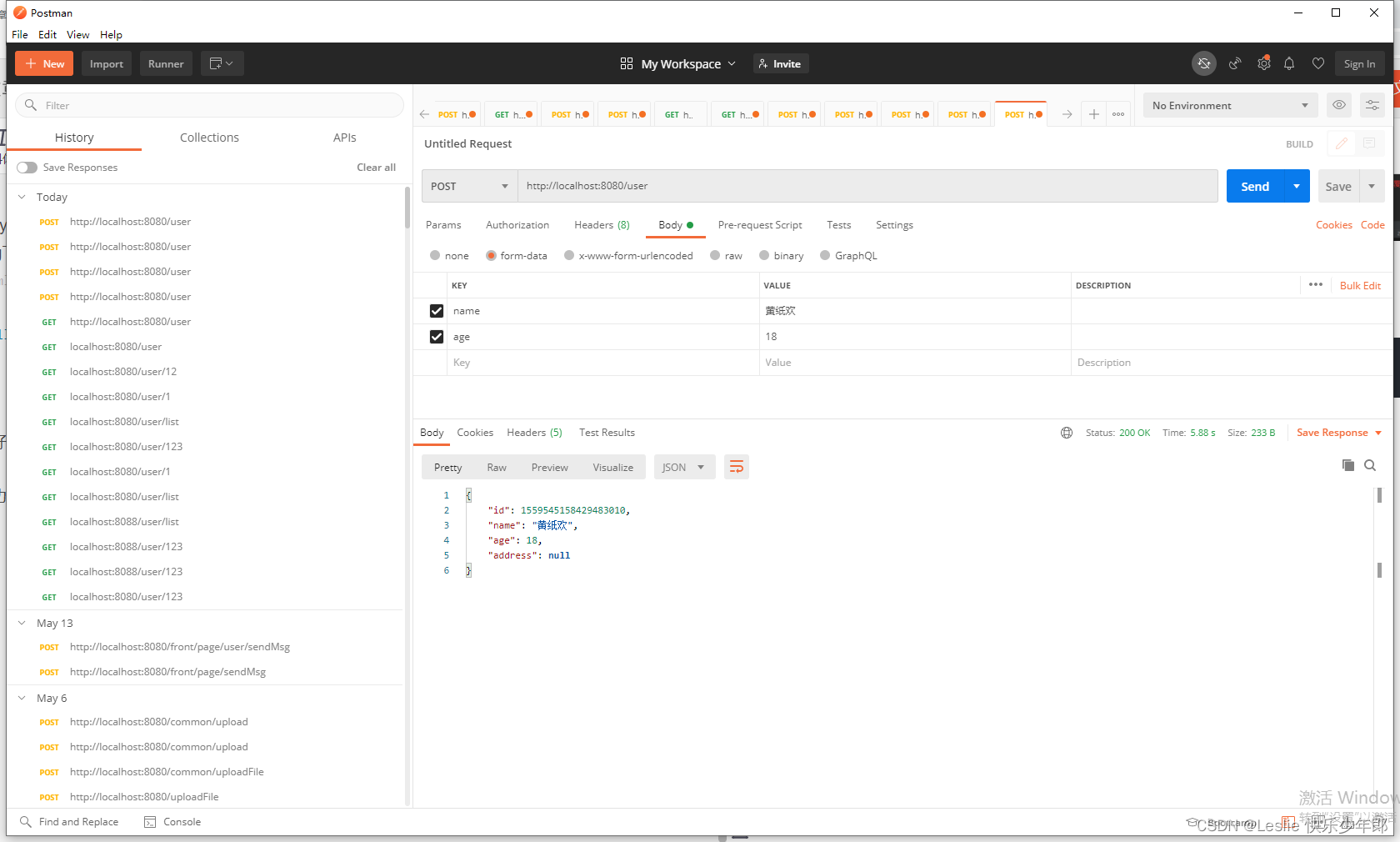
在主库进行操作
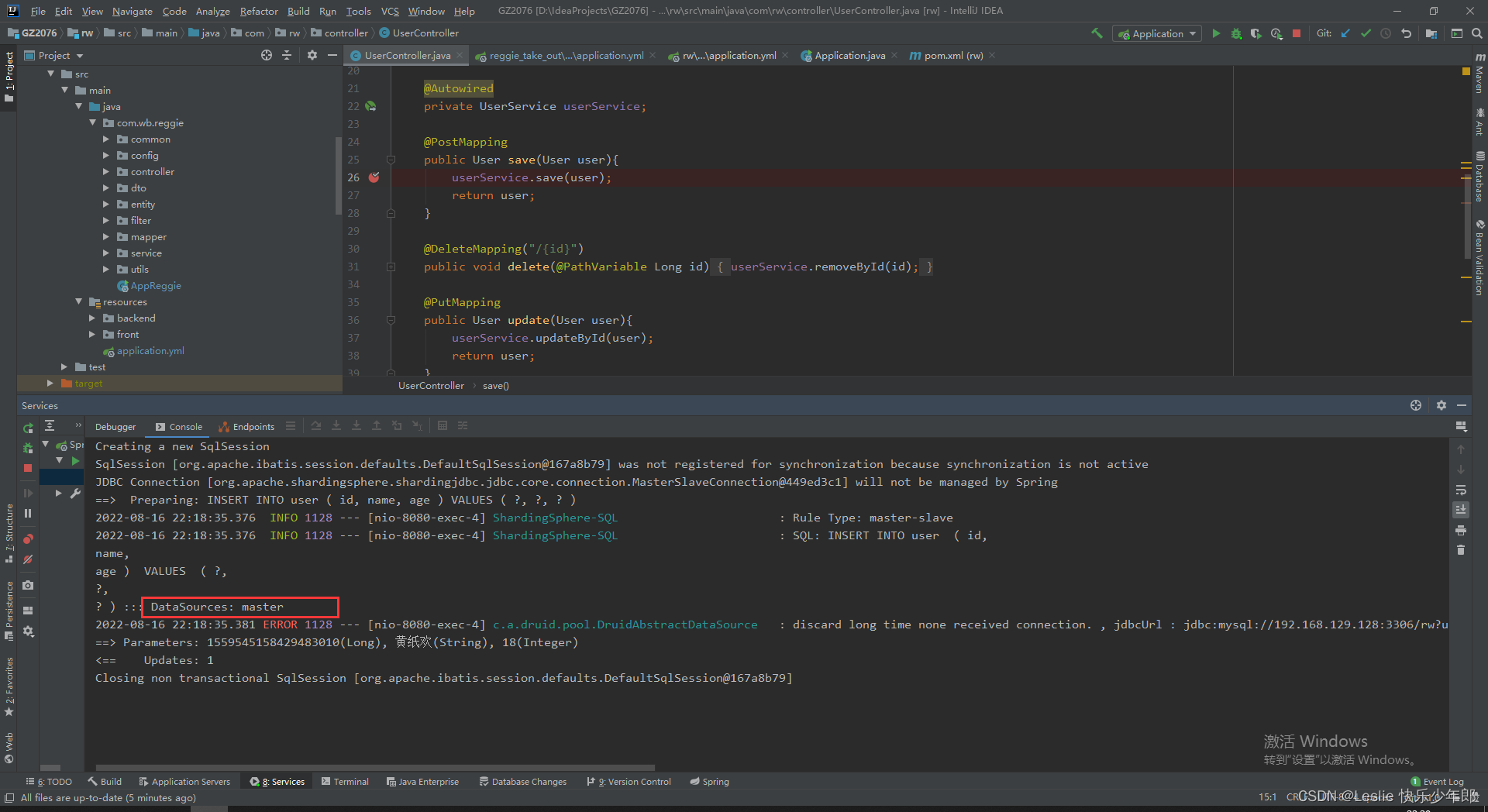
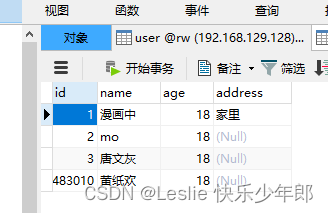
2,查询
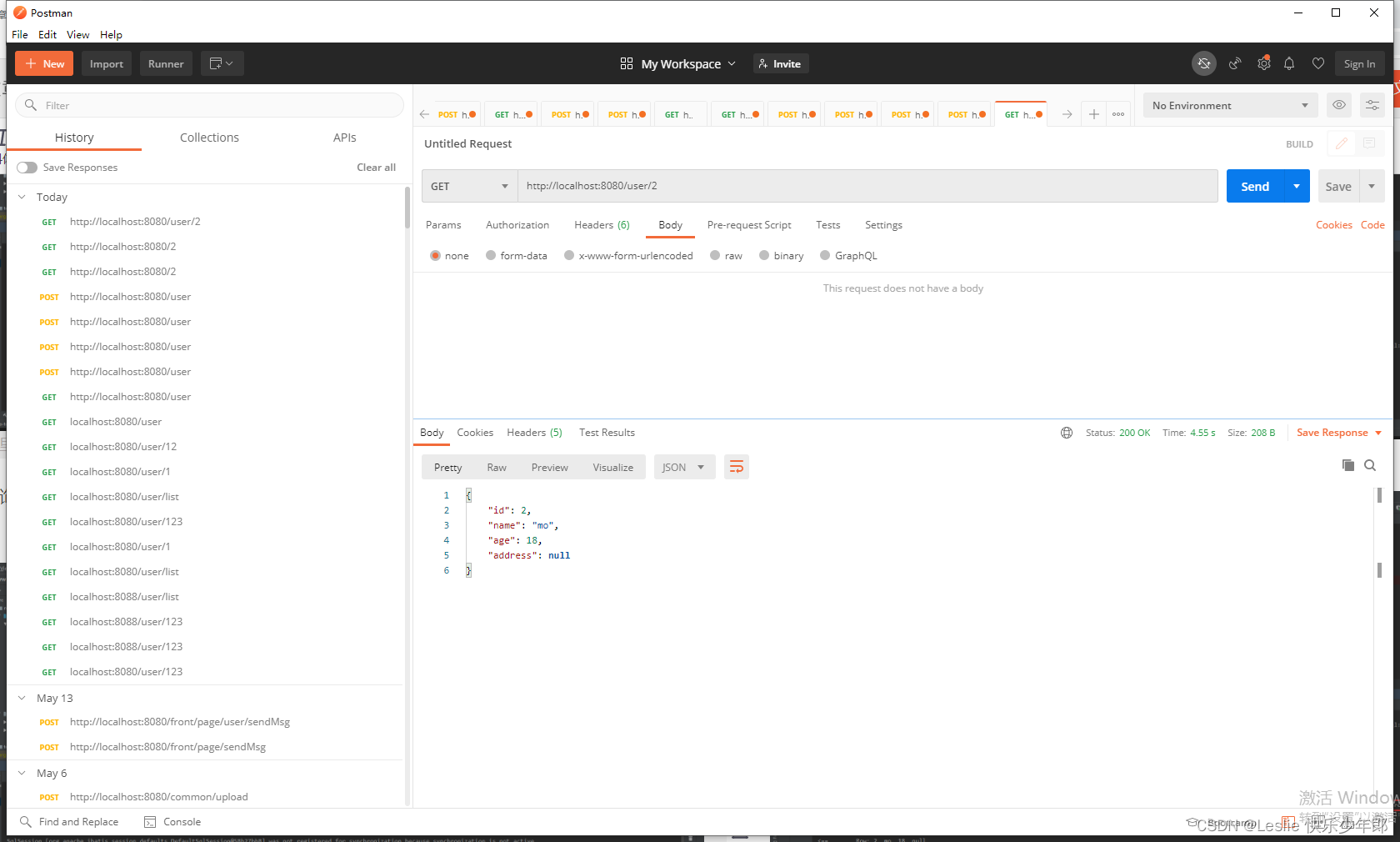
在从库进行操作
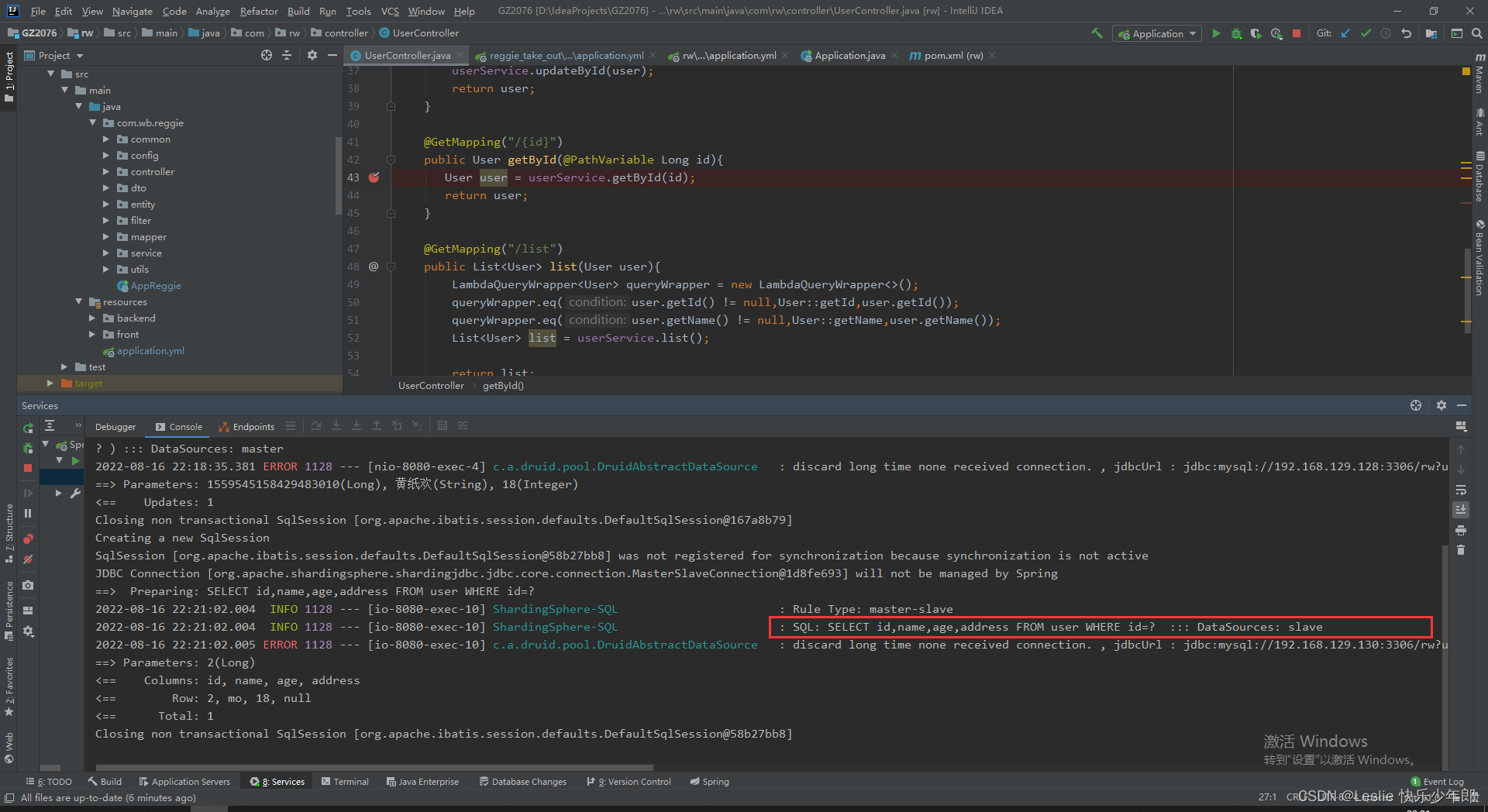
















 1153
1153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









