







KMP算法:(求最长公共前缀)
最长公共前后缀next数组:
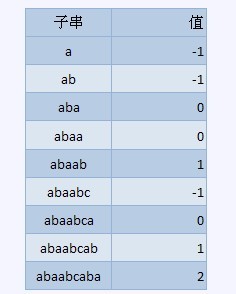
a b a a b c a b a
-1 -1 0 0 1 -1 0 1 2
先写出next算法
(1)next数组的定义:
设模式串T[0,m-1],(长度为m),那么next[i]的值表示是能匹配到的最长前缀长度,也是T[0,i - 1]的后缀
,如上面的例子,T=abcabd,那么next[5]表示既是abcab的前缀又是abcab的后缀的串的最长长度,显然应该是1,即串ab。注意到前面的例子中,当发生失配时T回溯到下表2,和next[5]数组是一致的,这当然不是个巧合,事实上,KMP算法就是通过next数组来计算发生失配时模式串应该回溯到的位置。
(2)next数组的计算:
这里介绍一下next数组的计算方法。
设模式串T[0,m-1],长度为m,由next数组的定义,可知next[0]=next[1]=-1,(因为这里的串的后缀,前缀不包括该串本身)。
接下来,假设我们从左到右依次计算next数组,在某一时刻,已经得到了next[0]~next[i],现在要计算next[i+1],设j=next[i],由于知道了next[i],所以我们知道T[0,j]=T[i-j+1,i],现在比较T[j + 1]和T[i + 1]。
如果相等,由next数组的定义,可以直接得出next[i+1]=j+1。
如果不相等,那么做j = next[j]的操作 , 边迭代边判断s[j+1] == s[i+1](找到了匹配点了),或者 j == -1(开始从头匹配),这是再判断s[j+1] == s[i+1],如果成立,next[i + 1] = j + 1;否则 next[i + 1]=j;
(3)KMP算法的实现
有了next数组,我们就可以通过next数组跳过不必要的检测,加快字符串匹配的速度了。那么为什么通过next数组可以保证匹配不会漏掉可匹配的位置呢?
首先,假设发生失配时T的下标在i,那么表示T[0,i-1]与原始串S[l,r]匹配,设next[i]=j,根据KMP算法,可以知道要将T回溯到下标j再继续进行匹配,根据next[i]的定义,可以得到T[0,j-1]和S[r-j+1,r]匹配,同时可知对于任何j小于y小于i,T[0,y]不和S[r-y,r]匹配,这样就可以保证匹配过程中不会漏掉可匹配的位置。同next数组的计算,在一般情况下,可能回溯到next[i]后再次发生失配,这时只要继续回溯到next[j],如果不行再继续回溯,最后回溯到next[0],如果还不匹配,这时说明原始串的当前位置和T的开始位置不同,只要将原始串的当前位置+1,继续匹配即可。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int MAXN = 10005;
int next[MAXN];
int sum = 0;
void getNext(char s[])
{
memset(next,-1,sizeof(next));
int i,j;
int n = strlen(s);
j = -1;
for(i = 0;i < n - 1;++i)
{
//i,j都表示当前已经匹配过的字符,而j+1与i+1是未匹配过的字符
while(j >= 0 && s[j+1] != s[i+1]){
j = next[j];
}
//跳出循环有两种情况,回溯到s[0]也没匹配到,或者未到达s[0]是匹配到了
if(s[j+1] == s[i+1]) j++;
//再次确认上面跳出循环的情况,并对j进行操作。
next[i+1] = j;
}
}
//s1是主串,s2是匹配串
void Search(char s1[],char s2[],int next[])
{
sum = 0;
int i;
int n = strlen(s1);
int m = strlen(s2);
int j = -1;
//i代表在s1里的下标,j代表s2里的下标
for(i = 0;i < n;++i)
{
while(j >= 0 && s1[i] != s2[j + 1])
{
j = next[j];
}
//跳出循环有两种情况:要从头匹配或者是匹配到了
if(s1[i] == s2[j + 1])
j++;
//匹配到了,j后移
if(j == m - 1)
{
printf("%d %d\n",i - j,i);
sum++;
j = next[j];
}
}
}
int main()
{
char s[MAXN];
char ptr[MAXN];
scanf("%s",ptr);
scanf("%s",s);
getNext(s);
int i,j;
for(i = 0;i < strlen(s);++i)
{
printf("%d ",next[i]);
}
printf("\n");
Search(ptr,s,next);
printf("%d\n",sum);
return 0;
}扩展KMP算法:(求最长公共前缀)
定义母串S,和字串T,设S的长度为n,T的长度为m,求T与S的每一个后缀的最长公共前缀,也就是说,设extend数组,extend[i]表示T与S[i,n-1]的最长公共前缀,要求出所有extendi。
注意到,如果有一个位置extend[i]=m,则表示T在S中出现,而且是在位置i出现,这就是标准的KMP问题,所以说拓展kmp是对KMP算法的扩展,所以一般将它称为扩展KMP算法。
- 拓展kmp算法一般步骤
下面来描述拓展kmp算法的一般步骤。
首先我们从左到右依次计算extend数组,在某一时刻,设extend[0…k]已经计算完毕,并且之前匹配过程中所达到的最远位置为P,所谓最远位置,严格来说就是i+extend[i]-1的最大值(0<=i<=k)(在求next数组时,这里的p是i+next[i]-1),并且设取这个最大值的位置为po(p0不一定是k,p0是1到k中的某个值,他能匹配到的长度是最远的),如在上一个例子中,计算extend[1]时,P=3,po=0。
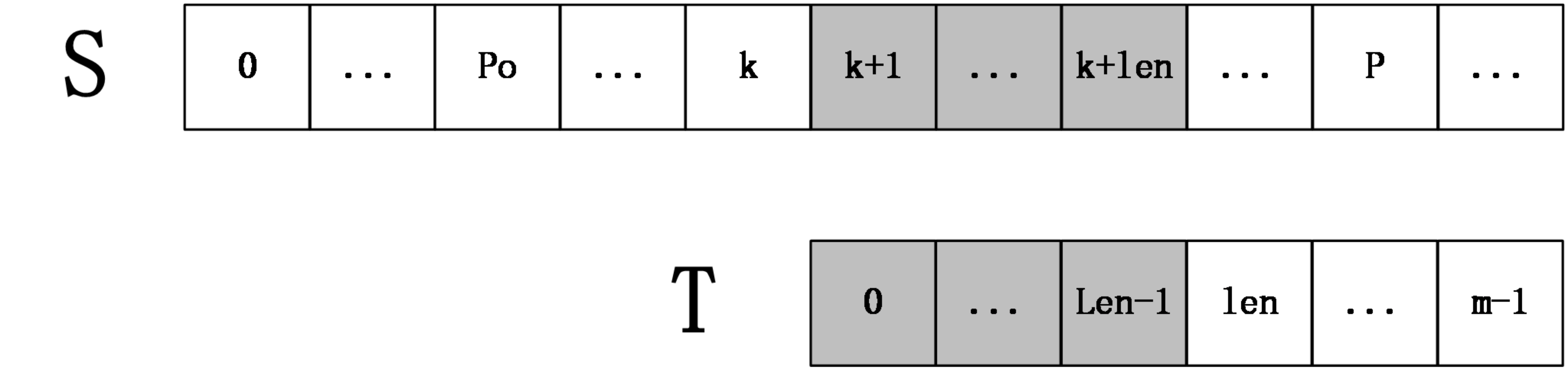
现在要计算extend[k+1],根据extend数组的定义,可以推断出S[po,P]=T[0,P-po],从而得到 S[k+1,P]=T[k-po+1,P-po],令len=next[k-po+1],(回忆下next数组的定义),分两种情况讨论:
第一种情况:k+len小于P
如下图所示:
上图中,S[k+1,k+len]=T[0,len-1],然后S[k+len+1]一定不等于T[len],因为如果它们相等,则有S[k+1,k+len+1]=T[k+po+1,k+po+len+1]=T[0,len],那么next[k+po+1]=len+1,这和next数组的定义不符(next[i]表示T[i,m-1]和T的最长公共前缀长度),所以在这种情况下,不用进行任何匹配,就知道extend[k+1]=len。
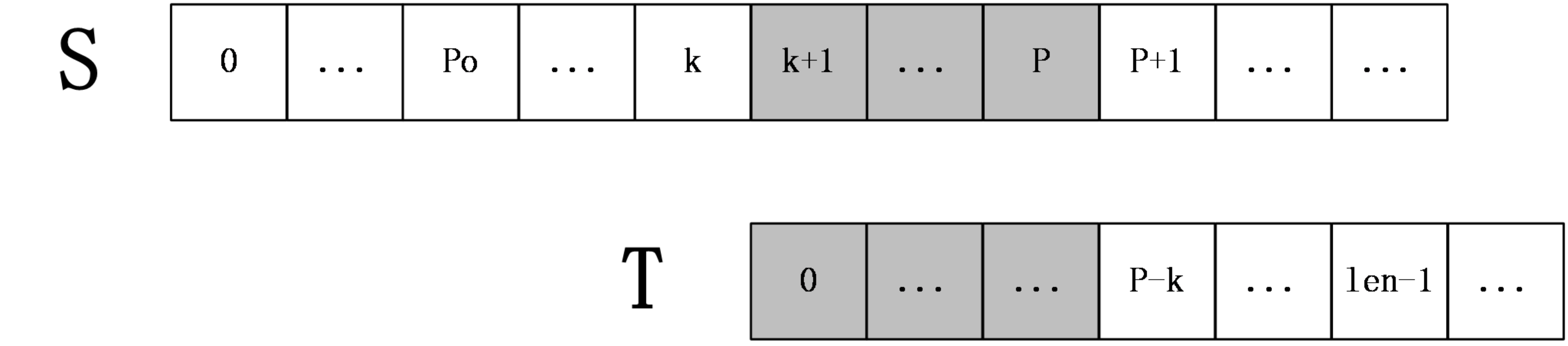
第二种情况: k+len>=P
如下图:
上图中,S[p+1]之后的字符都是未知的,也就是还未进行过匹配的字符串,所以在这种情况下,就要从S[P+1]和T[P-k+1](j = p - k 与T是匹配到的长度,从k+1到p的长度)开始一一匹配,直到发生失配为止,当匹配完成后,如果得到的extend[k+1]+(k+1)大于P则要更新未知P和po。
至此,拓展kmp算法的过程已经描述完成,细心地读者可能会发现,next数组是如何计算还没有进行说明,事实上,计算next数组的过程和计算extend[i]的过程完全一样,将它看成是以T为母串,T为字串的特殊的拓展kmp算法匹配就可以了,计算过程中的next数组全是已经计算过的,所以按照上述介绍的算法计算next数组即可,这里不再赘述。

上述转自:http://blog.csdn.net/dyx404514/article/details/41831947,自认为写的非常清楚和明白。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
const int MAXN = 100010;
int next[MAXN],ex[MAXN];
void GetNext(char str[])
{
int len = strlen(str);
next[0] = len;
int i = 0,j;
int p0;
while(str[i] == str[i + 1] && i + 1 < len)
i++;
next[1] = i;
p0 = 1;
//初始化p0的位置
for(i = 2;i < len;++i)
{
if(next[i - p0] + i - 1 < p0 + next[p0] - 1)
next[i] = next[i - p0];
else{
j = p0 + next[p0] - 1 - i + 1;
//j指向未比较过的字符
if(j < 0) j = 0;如果i>po+next[po],则要从头开始匹配
while(i + j < len && str[j] == str[i + j])
j++;
next[i] = j;
p0 = i;
}
}
}
//s1是主串,s2是子串
void Extend(char s1[],char s2[])
{
GetNext(s2);
int i = 0,j;
int n = strlen(s1);
int m = strlen(s2);
int p0;
while(i < m && s1[i] == s2[i])
{
++i;
}
ex[0] = i;
p0 = 0;
//初始化p0的位置
for(i = 1;i < n;++i)
{
//p0+ex[p0]-1就是p0能匹配到的最远长度
if(i - 1 + next[i - p0] < p0 + ex[p0] - 1)
ex[i] = next[i - p0];
else{
j = p0 + ex[p0] - 1 - i + 1;
if(j < 0) j = 0;//可能为-1,因为可能extend[p0] = 0,i又等于k + 1;
//j对于s2来说是有s2[0],对s1来说是i = k + 1;所以就s2[j]与s1[i+j]均指向未匹配过的字符串
while(i + j < n && j < m && s2[j] == s1[i + j])
j++;
ex[i] = j;
p0 = i;
}
}
}
int main()
{
char str1[1000];
char str2[1000];
scanf("%s",str1);
scanf("%s",str2);
Extend(str1,str2);
for(int i = 0;i < strlen(str1);++i)
{
printf("%d ",ex[i]);
}
printf("\n");
return 0;
}AC自动机:
先介绍一下字典树(Tire树):
Trie树,即字典树,又称单词查找树或键树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计和排序大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:最大限度地减少无谓的字符串比较,查询效率比哈希表高。
Trie的核心思想是空间换时间。利用字符串的公共前缀来降低查询时间的开销以达到提高效率的目的。
(缺点就是用空间来换时间,在不同的题目要求下,可以自己辨别来运用);
它有3个基本性质:
1、根节点不包含字符,除根节点外每一个节点都只包含一个字符。
2、从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
3、每个节点的所有子节点包含的字符都不相同。

红色标志代表一个单词的结束标志,代表这里已经成功搜到了一个单词。
每个节点下面都有26个儿子(只有小写字母),如果有大小写字母,那应该有34个儿子………….
每个节点下面有单词存入的就为其开辟空间,否则就将之写为NULL。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<malloc.h>
#include<cstdlib>
using namespace std;
#define MAX 26
typedef struct Tire
{
int v;//v的数代表接受态
Tire *next[MAX];
};
Tire *root;
void Init()
{
int i,j;
root = (Tire *)malloc(sizeof(Tire));
for(i = 0;i < MAX;++i)
{
root -> next[i] = NULL;
}
}
void createTire(char str[])
{
int len = strlen(str);
int i,j;
Tire *p = root,*q;
for(i = 0;i < len;++i)
{
int id = str[i] - 'a';
if(p -> next[id] == NULL)
{
q = (Tire *)malloc(sizeof(Tire));
q -> v = 0;
for(j = 0;j < MAX;++j)
{
q -> next[j] = NULL;
}
p -> next[id] = q;
p = p -> next[id];
}
else{
p = p -> next[id];
}
}
//代表接受态,虽然下面还有字母,但是从这里截止
//当p -> v大于等于1的时候说明这里是接受点,就是这里是一个单词截止的地方
p -> v ++;
}
//查询字符串
int findTire(char str[])
{
int len = strlen(str);
int i,j;
Tire *p = root;
for(i = 0;i < len;++i)
{
int id = str[i] - 'a';
p = p -> next[id];
if(p == NULL)
//代表未找到该字符串
return 0;
}
return -1;
}
//用bfs的思想来释放空间
void dealTire(Tire *T)
{
if(T == NULL)
return ;
int i;
for(i = 0;i < MAX;++i)
{
if(T -> next[i] != NULL)
dealTire(T -> next[i]);
}
free(T);
return ;
}
int main()
{
char str[100];
Init();
for(int i = 0;i < 6;++i)
{
scanf("%s",str);
createTire(str);
}
scanf("%s",str);
int m = findTire(str);
cout << m << endl;
dealTire(root);
return 0;
}AC自动机的构造:
1.构造一棵Trie,作为AC自动机的搜索数据结构。
2.构造fail指针,使当前字符失配时跳转到具有最长公共前后缀的字符继续匹配。如同 KMP算法一样, AC自动机在匹配时如果当前字符匹配失败,那么利用fail指针进行跳转。由此可知如果跳转,跳转后的串的前缀,必为跳转前的模式串的后缀并且跳转的新位置的深度(匹配字符个数)一定小于跳之前的节点。所以我们可以利用 bfs在 Trie上面进行 fail指针的求解。
3.扫描主串进行匹配。
转自:http://blog.csdn.net/baidu_30541191/article/details/47447175
这里最重要的是构造失败指针:

root的失败指针为NULL。
求某个节点的失败指针的方法:
1.判断他的父亲节点是不是root。
2.若是,他的失败指针指向的是root。
3.若不是,找到父亲节点失败指针所指的节点的子节点是否含有和所求节点相同的字母。例如,上图中求she中e的失败指针:e的父亲节点h的失败指针是her中的h,而h的儿子节点有和e相同的节点。
4.如果含有,失败指针就是找到的那个和本节点相同的节点,如she中e的失败指针就是he中的e节点。
5.如果没有,找到他父亲的失败指针的失败指针继续3.。直到到root节点都没找到的话,就令本解点的失败指针为root。如shr的r节点,他的父亲节点h的失败指针是her中的h。其子节点中只有e,没有r所以再求her中h的失败指针,他是root,所以shr中r的失败指针是root。
失败指针指的是以当前节点表示的字符为最后一个字符的最长当前字符串的后缀字符串的最后一个节点。
(失败指针指向的是另一个字符,该字符前面直到root的字符串是原先那个字符串的后缀);
#include<iostream>
#include<cstdio>
#include<cstring>
#include<algorithm>
#include<queue>
using namespace std;
#define MAX 26
typedef struct node{
node *next[MAX];
node *fail;//失败指针
int sum;//代表这节点之前的字符串是不是输入的一个字符串
};
node *root;
node *NewNode()
{
int i;
node *s = (node *)malloc(sizeof(node));
for(i = 0;i < 26;++i)
{
s -> next[i] = NULL;
}
s -> fail = NULL;
s -> sum = 0;
return s;
}
void BuildTree(char str[])
{
node *p = root;
int i,j;
node *q;
for(i = 0;i < strlen(str);++i)
{
int id = str[i] - 'a';
if(p -> next[id] == NULL)
{
q = NewNode();
p -> next[id] = q;
}
p = p -> next[id];
}
p -> sum++;
}
//***比较重要的建失败指针
void BuidFail()
{
queue<node *>myqueue;
root -> fail = NULL;
int i,j;
myqueue.push(root);
node *p;
while(!myqueue.empty())
{
p = myqueue.front();
myqueue.pop();
node *tmp;
//一定要得到对应儿子的失败指针为止
for(i = 0;i < 26;++i)
{
if(p -> next[i] != NULL)
//说明需要求出他对应的失败指针
{
myqueue.push(p -> next[i]);
if(p == root)
//解决第二层特殊的情况
{
p -> next[i] -> fail = root;
}
else{
tmp = p -> fail;
//tmp表示父亲节点的失败指针,最后下面看的是父亲节点的失败指针的儿子们
while(tmp != NULL)
{
if(tmp -> next[i] != NULL)
//找到了对应相等的字符
{
p -> next[i] -> fail = tmp -> next[i];
break;
}
tmp = tmp -> fail;
}
if(tmp == NULL)
//表示失败节点一直指到了根节点
{
p -> next[i] -> fail = root;
}
}
}
}
}
}
//删除树
void deal(node *root)
{
node *p = root;
for(int i = 0;i < 26;++i)
{
if(p -> next[i] != NULL)
deal(p -> next[i]);
}
free(root);
root = NULL;
}
int query(char str[])
{
int id,cnt = 0;
node *p = root;
int i,j;
for(i = 0;i < strlen(str);++i)
{
id = str[i] - 'a';
while(p -> next[id] == NULL && p -> fail != NULL)
p = p -> fail;
//跳出循环有两个情况:在字典树里面找不到对应的字母了 或者 迭代失败指针到了根节点root
if(p -> next[id] != NULL)
{
p = p -> next[id];
//找到了对应的字母,指针往下走
node *tmp = p;
while(tmp -> sum >= 1)
//这里存在一个输入的字母
{
cnt++;
//cnt+1代表在这个字符串找到一个输入的字符串了
tmp -> sum = -1;
//这里表示匹配到多次只算一次
tmp = tmp -> fail;
}
}
}
return cnt;
}
int main()
{
root = NewNode();
char str[100];
for(int i = 0;i < 4;++i)
{
scanf("%s",str);
BuildTree(str);
}
BuidFail();
scanf("%s",str);
int m = query(str);
cout<<m<<endl;
deal(root);
return 0;
}
哈希树只进行了了解,为进行代码实现:
推荐:http://blog.csdn.net/yang_yulei/article/details/46337405
代码实现:http://blog.csdn.net/qq_26141345/article/details/52947672















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









