







在把scrapy爬虫整合成插件形式的时候,遇到了No module named ‘baidujs.settings’; ‘baidujs’ is not a package这个问题,百度之后发现是文件名的问题,文件名和文件夹的名字相同了,所以就错了,改过来就好啦!
本来是酱的:

现在是酱的:
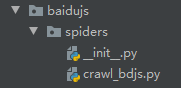
嘻嘻!














04-02
 1015
1015
1015
05-25
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









