







一、写一个简单爬虫(以爬虫“7d”为例)
1、在项目存放目录下进入终端输入scrapy startproject spider(项目名,随便取)
2、打开pycharm->file->open打开项目,在spiders文件夹下新建python文件,开始编写爬虫(spiders文件夹里专门存放爬虫)以下代码只是参考,后面写入数据库的不是这个爬虫获取的信息。

3、在terminal输入scrapy list查看爬虫个数,输入scrapy crawl 爬虫名(即上图的name值)运行爬虫。
二、连接sqlite数据库,并将数据写入(以爬虫“zufang”为例)
1)创建数据库
1、在终端输入ipython,回车
2、继续输入import sqlite3,回车
3、继续输入zufang = sqlite3.connect(‘zufang.sqlite’),回车,等号左边的是项目名(好像,我也不是很清楚。。。
4、继续输入create_table = ‘create table (title varchar(512), money varchar(128))’,回车
5、继续输入zufang.ececute(create_table),回车
6、终端返回cursor
7、继续输入exit,回车
至此数据库创建完毕,并且建立一张zufang表
可以看到和scrapy.cfg同级目录的一个sqlite文件,打开右侧数据库,将此文件拖入,刷新,可以看到该表格,里面没有内容。
下图是给一中的天气爬虫连接数据库,可以作为参考。

2)编写代码
1、编写爬虫“zufang”,放在spiders文件夹下

跟上面的爬虫比①增加了一个item class的导入和item.py文件内类的实例zf②改变了for循环的写法,把爬到的内容写到item中,通过item传到pipeline中写入数据库
2、在settings里找到ITEM_PIPLINES,解除注释

3、items.py相应class下增加两个参数,这两个参数就是传给pipelines然后写入sqlite的两个字段
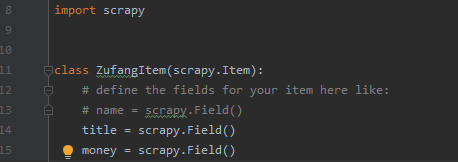
4、编写pipelines文件

数据库写入之后要关闭
5、在终端输入scrapy crawl zufang,运行爬虫,看到数据打印到终端(因为pipelines里写了print)

6、完结撒花!!!租房代码是跟着网易云课堂的小布老师的scrapy基础课程写的,很棒的课程!
这篇文章记录一下简单爬虫的基本步骤,欢迎大佬指正!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









