







Seata分布式事务
文章目录
一、为什么要用Seata
1.问题背景
在微服务的架构下,数据不一致
2.数据不一致的原因
在微服务的环境下,由于调用链路跨越多个应用,甚至跨越多个数据源,数据的一致性在普通情况下难以保证,导致数据不一致的原因非常多,这里列举了三个最常见的原因
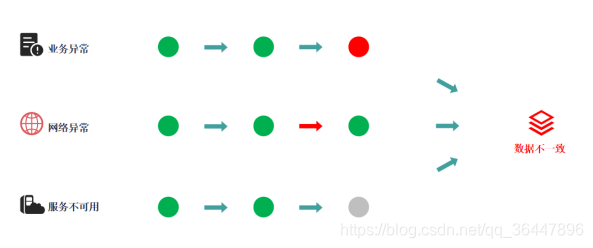
1.业务异常一个服务链路调用中,如果调用的过程出现业务异常,产生异常的应用独立回滚,非异常的应用数据已经持久化到数据库。
2.网络异常调用的过程中,由于网络不稳定,导致链路中断,部分应用业务执行完成,部分应用业务未被执行。
3.服务不可用若服务不可用,无法被正常调用,也会导致问题的产生
在以往如果出现数据不一致的问题,相信大多数的解决方案是这样的
1.人工补偿数据
2.定时任务检查和补偿数据
但是这两种方式的缺点也是显然意见的,一种是浪费大量的人力成本和时间,另外一种是浪费大量的系统资源去检查数据是否一致和额外的人力成本。
二、Seata简介
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
Seata原理和设计
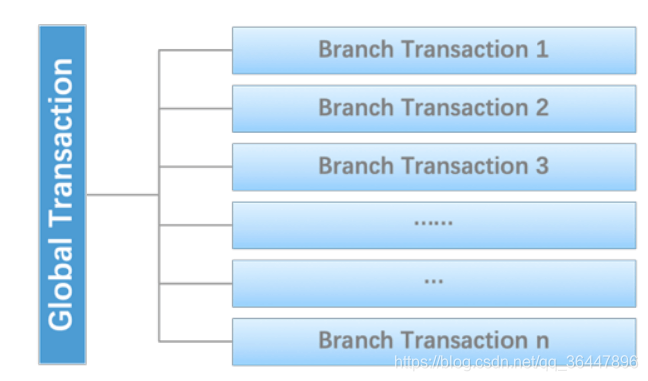
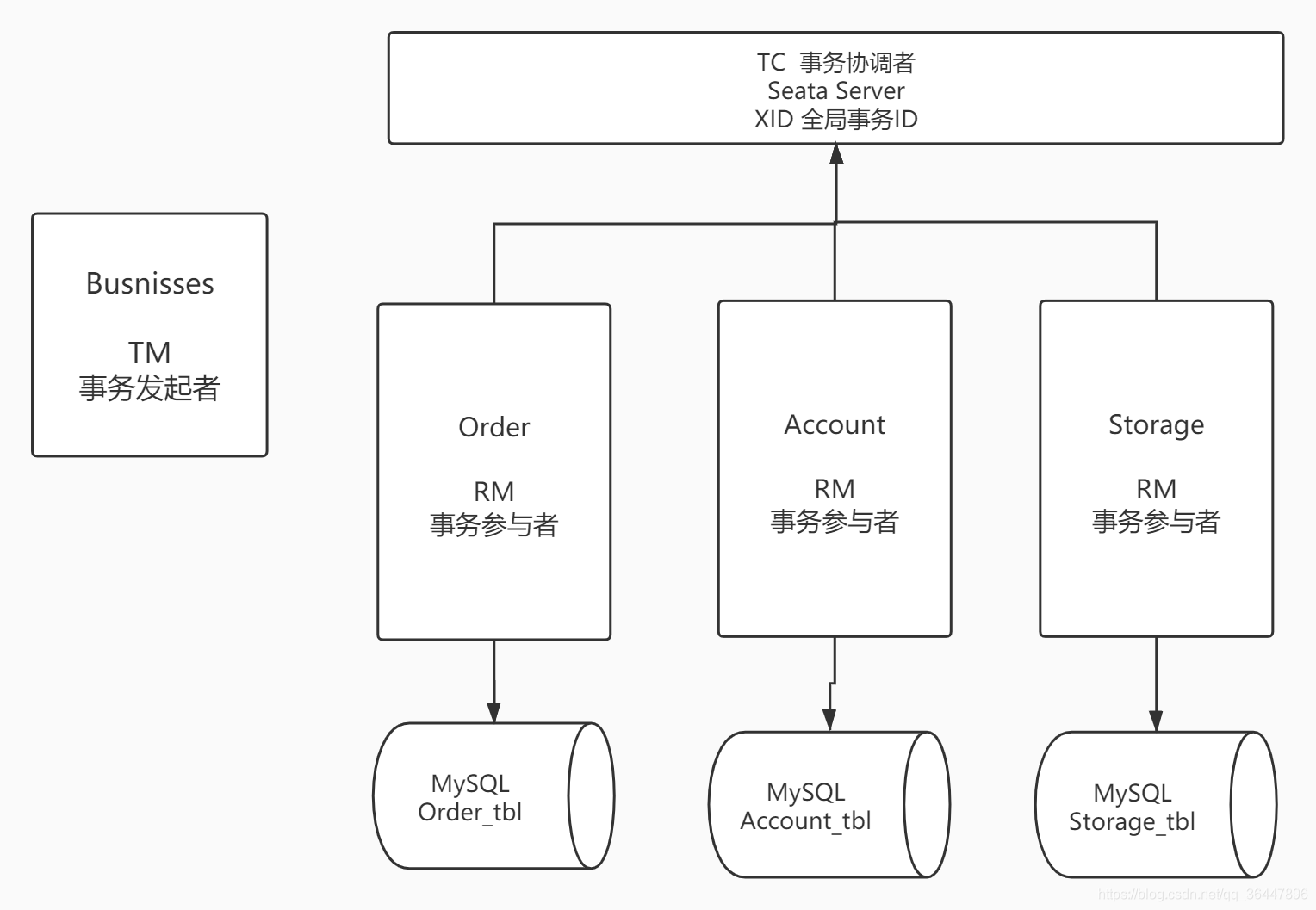
我们可以把一个分布式事务理解成一个包含了若干分支事务的全局事务,全局事务的职责是协调其下管辖的分支事务达成一致,要么一起成功提交,要么一起失败回滚。此外,通常分支事务本身就是一个满足ACID的本地事务。这是我们对分布式事务结构的基本认识,与 XA 是一致的。
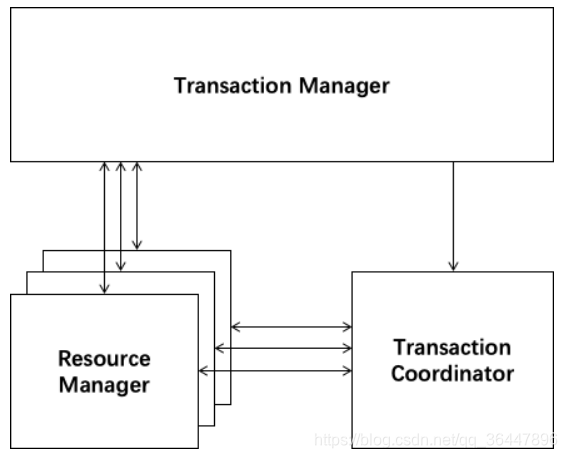
协议分布式事务处理过程的三个组件
- Transaction Coordinator (TC): 事务协调器,维护全局事务的运行状态,负责协调并驱动全局事务的提交或回滚;
- Transaction Manager ™: 控制全局事务的边界,负责开启一个全局事务,并最终发起全局提交或全局回滚的决议;
- Resource Manager (RM):控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指令,驱动分支(本地)事务的提交和回滚。
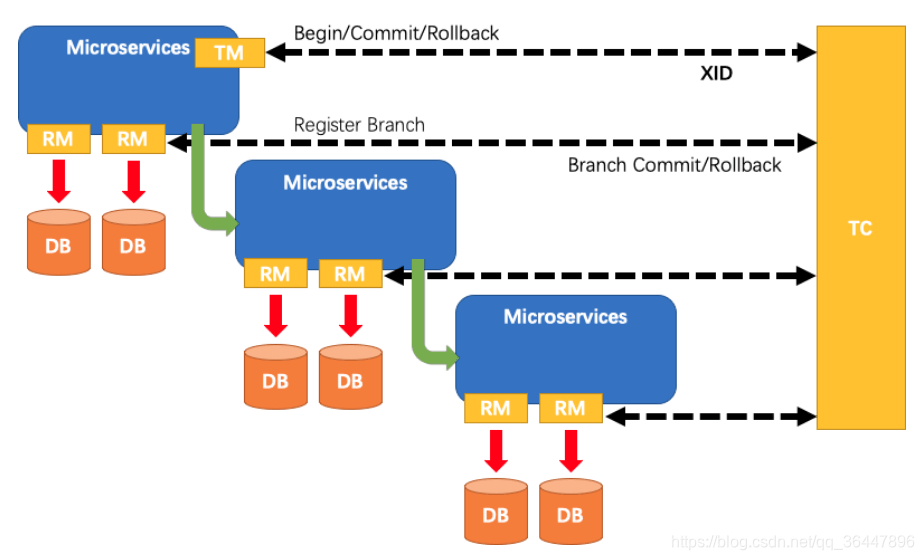
一个典型的分布式事务过程
-
TM 向 TC 申请开启一个全局事务,全局事务创建成功并生成一个全局唯一的 XID;
-
XID 在微服务调用链路的上下文中传播; RM 向 TC 注册分支事务,将其纳入 XID 对应全局事务的管辖; TM 向 TC 发起针对
-
XID 的全局提交或回滚决议; TC 调度 XID 下管辖的全部分支事务完成提交或回滚请求。
Seata可靠吗
一项新的技术出来不是可以直接运用,需要市场的检验,观察他是否被别的企业运用到生产环境,是否真的可靠
 图片不是很全,可以去seata官网查看更多合作企业
图片不是很全,可以去seata官网查看更多合作企业
Seata官网
可以看出很多知名企业都使用Seata,让我们一起来看看seata在springcloud项目中是如何使用的。
三、springcloud+eureka+seata实现分布式事务处理
演示项目组成结构
搭建步骤
配置Seata-server
搭建Eureka
Spring Cloud教程 | 第一篇:服务的注册与发现 | Eureka
可以参照上述文章进行配置Eureka,然后对application.yml进行端口号修改
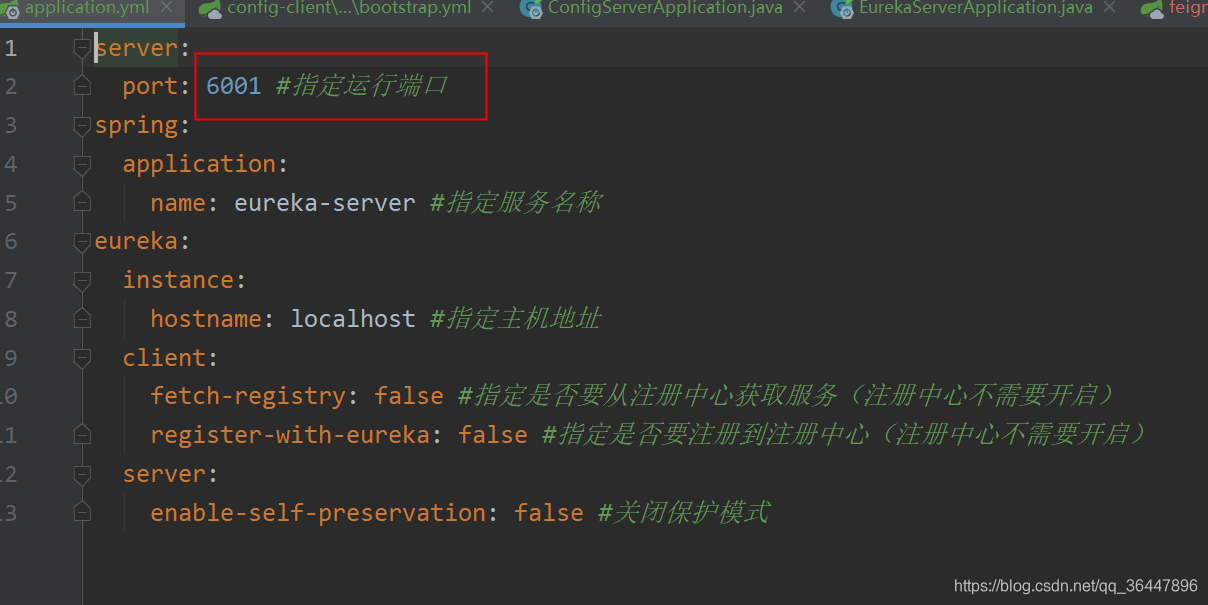
我们更改下端口号为6001
创建seata-server数据库
-- -------------------------------- The script used when storeMode is 'db' --------------------------------
-- the table to store GlobalSession data
CREATE TABLE IF NOT EXISTS `global_table`
(
`xid` VARCHAR(128) NOT NULL,
`transaction_id`  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1528
1528

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









