R语言︱词典型情感分析文本操作技巧汇总(打标签、词典与数据匹配等)
笔者寄语:情感分析中对文本处理的数据的小技巧要求比较高,笔者在学习时候会为一些小技巧感到头疼不已。
主要包括以下内容:
1、批量读取txt字符文件(导入、文本内容逐行读取、加入文档名字)、
2、文本清洗(一级清洗,去标点;二级清洗去内容;三级清洗,去停用词)
3、词典之间匹配(有主键join、词库匹配%in%)
4、分词之后档案id+label的加入
5、情感打分(关联情感词join、情感分数aggerate、情感偏向)
————————————————————————————————————————————
1、批量读取txt字符文件
难题:一个文件夹有许多txt文件,如何导入,并且读出来,还要加上文档名字?
1.1 如何导入?
如何用函数批量导入文本,并且能够留在R的环境之中?循环用read.table,怎么解决每个文本文件命名问题?
list函数能够有效的读入,并且存放非结构化数据。
- reviewpath <- "F:/R语言/train2"
- completepath <- list.files(reviewpath, pattern = "*.txt$", full.names = TRUE)
代码解读:reviewpath为文件夹的目录名字,completepath为读取文件夹中所有的文件,生成字符串(character)格式。
详细的文本文件读取方法,可见博客。
1.2 如何读取单文本内容?
前面文档导入,相当于是给每个文档定了位,现在需要读入单个文档内的文本信息。
文本文档读取的时候会出现很多问题,比如分隔符、制表符等,而出现乱码,需要逐行读取。
- ######批量读入文本
- read.txt <- function(x) {
- des <- readLines(x) #每行读取
- return(paste(des, collapse = "")) #没有return则返回最后一个函数对象
- }
- review <- lapply(completepath, read.txt)
- #如果程序警告,这里可能是部分文件最后一行没有换行导致,不用担心。
代码解读:read.txt是一个简单的逐行读取的函数,readLines函数,是将一段文字分成以下的形式,需要粘贴起来;
- [1] ""
- [2] "刚买的这款电脑,在自提点打开的,就发现键盘已经坏了,有个按键都快掉了,自提点不管,让去联系退换货部门,退换货部门说键盘坏了不管退换,让去惠普自己更换新键盘。"
- [3] ""
- [4] "在京东刚买的东西出现问题就要四处跑去修理,他们把责任推的一干二净,现在除非你出具惠普的质检报告,他们才给受理。"
- [5] ""
return(paste)函数将每一行粘贴在一起,最后返回完整的文本内容;
lapply表示逐文本读取。
1.3 加入文档名字
读取了每个文档到list之中,怎么跟每个文档名字匹配在一起?
- docname <- list.files(reviewpath, pattern = "*.txt$")
- reviewdf <- as.data.frame(cbind(docname, unlist(review)),
- stringsAsFactors = F)
- colnames(reviewdf) <- c("id", "msg") #列名
代码解读:list.files中,full.names=F代表返回文档名字(默认),full.names=T则定位文档;
利用as.data.frame成为一个数据框,并且不变成因子型,stringsAsFactors是因为文档名字列,很容易变成字符因子型,需要关闭这功能;
colnames修改列名,还有names也可以达到同样的效果。

图 1
————————————————————————————————————————————
2、文本清洗工作
文本挖掘中,对文本的清洗工作尤为重要,会出现比如:英文逗号、波浪线、英文单引号、英文双引号、分隔符等
2.1 一级清洗——去标点
如图1,所示的msg,对其进行一些标点清洗,比如双引号,波浪号等。
- reviewdf$msg <- gsub(pattern = " ", replacement ="", reviewdf$msg) #gsub是字符替换函数,去空格
- reviewdf$msg <- gsub("\t", "", reviewdf$msg) #有时需要使用\\\t
- reviewdf$msg <- gsub(",", ",", reviewdf$msg)#文中有英文逗号会报错,所以用大写的“,”
- reviewdf$msg <- gsub("~|'", "", reviewdf$msg)#替换了波浪号(~)和英文单引号('),它们之间用“|”符号隔开,表示或的关系
- reviewdf$msg <- gsub("\\\"", "", reviewdf$msg)#替换所有的英文双引号("),因为双引号在R中有特殊含义,所以要使用三个斜杠(\\\)转义
代码解读:英文单引号(')、英文双引号(")、波浪号(~),都会引起读取时发生警告,带来csv文件或txt文件读取不完整的后果。还有一些字符型会出现乱码的标点等,详见博客:R语言︱文本(字符串)处理与正则表达式
2.2 二级清洗——去内容
如图1 ,msg,对文档进行二级清洗,比如清楚全英文字符、清除数字等。
- sentence <- as.vector(test$msg) #文本内容转化为向量sentence
-
- sentence <- gsub("[[:digit:]]*", "", sentence) #清除数字[a-zA-Z]
- sentence <- gsub("[a-zA-Z]", "", sentence) #清除英文字符
- sentence <- gsub("\\.", "", sentence) #清除全英文的dot符号
- sentence <- sentence[!is.na(sentence)] #清除对应sentence里面的空值(文本内容),要先执行文本名
- sentence <- sentence[!nchar(sentence) < 2] #`nchar`函数对字符计数,英文叹号为R语言里的“非”函数
代码解读:在进行二级清洗的过程中,需要先转化为向量形式,as.vector;
字符数过小的文本也需要清洗,nchar就是字符计数函数。
2.3 三级清理——停用词清理(哎呦,哎,啊...)
去除原理就是导入停用词列表,是一列chr[1:n]的格式;
先与情感词典匹配,在停用词库去掉情感词典中的单词,以免删除了很多情感词,构造新的停用词;
再与源序列匹配,在原序列中去掉停用词。
第一种方法:
- stopword <- read.csv("F:/R语言/R语言与文本挖掘/情感分析/数据/dict/stopword.csv", header = T, sep = ",", stringsAsFactors = F)
- stopword <- stopword[!stopword$term %in% posneg$term,]#函数`%in%`在posneg$term中查找stopword的元素,如果查到了就返回真值,没查到就返回假
- #结果是一个和stopword等长的波尔值向量,“非”函数将布尔值反向
- testterm <- testterm[!testterm$term %in% stopword,]#去除停用词
代码解读:
管道函数A %in% B,代表在A中搜索B,存在则生成(TRUE,FALSE,TRUE)布尔向量,其中TURE代表A/B共有的。形成一个与原序列的等长的波尔值向量,“非”函数将布尔值反向就可以去除停用词。
stopword[!stopword$term %in% posneg$term,],去掉stopword中与posneg共有的词;
testterm[!testterm$term %in% stopword$term,],去掉testtrerm(原序列)与stopword共有的词。
第二种方法:
- stopword <- read.csv("F:/R语言/R语言与文本挖掘/情感分析/数据/dict/stopword.csv", header = T, sep = ",", stringsAsFactors = F)
- stopword <- setdiff(stopword$term,posneg$term)
- testterm<- setdiff(testterm$term,stopword)
setdiff(x,y),代表在x中去掉xy共有的元素。
setdiff与%in%都是集合运算符号,可见其他的一些符号:R语言︱集合运算
————————————————————————————————————————————
3、文档之间匹配
3.1 有主键的情况
如图1 中的id,就是一个主键,建立主键之间的关联可以用plyr中的Join函数,`join`默认设置下执行左连接。
- #plyr包里的`join`函数会根据名称相同的列进行匹配关联,`join`默认设置下执行左连接
- reviewdf <- join(表1,表2)
- reviewdf <- 表1[!is.na(表1$label),] #非NA值的行赋值
代码解读:表1为图1中的数据表,表2是id+label;
join之后,在表1中加入匹配到的表2的label;
并且通过[!x,]去掉了,没有label的文本。
其他关于主键合并的方法有,dplyr包等,可见博客:R语言数据集合并、数据增减
3.2 词库之间相互匹配
1、集合运算(%in%/setdiff())——做去除数据
在2.3的三级停用词清理的过程中,就会用到这个。两个词库,但是没有主键,两个词库都有共有的一些词语,那么怎么建立两个词库的连接呢?
管道函数%in%,可以很好的解决。A%in%B,代表在A中搜索B,存在B则生成(TRUE,FALSE,TRUE)布尔向量,其中TURE代表A/B共有的。
向量长度依存于A,会生成一个与A相同长度的布尔向量,通过A[布尔向量,]就可以直接使用。
回忆一下,缺失值查找函数,A[na.is(x)],也是生成布尔向量。
详细见2.3的停用词删除的用法。
2、left_join——词库匹配打标签
以上%in%较为适合做去除数据来做,因为可以生成布尔向量,作为过渡。但是如何连接词库,并且匹配过去标签呢。
现在有两个数据:
- > head(temp)
- term df
- 1 阿波罗 0.0000573263
- 2 阿尔卑斯山 0.0000573263
- 3 阿富汗 0.0001719789
- 4 阿哥 0.0001146526
- 5 阿根廷 0.0000573263
- 6 阿拉伯 0.0001146526
- > head(traintfidf[,1:3])
- id label term
- 1 4995.txt 1 阿波罗
- 2 16443.txt 1 阿尔卑斯山
- 3 12897.txt 1 阿富汗
- 4 7001.txt 1 阿富汗
- 5 9427.txt 1 阿富汗
- 6 12368.txt 1 阿哥
通过left_join之后,就可以根据每个词语匹配DF值,并且在源数据重复的情况下,还是能够顺利匹配上。
用在监督式算法情感分析之中,可见R语言︱监督算法式的情感分析笔记。
- > head(traintfidf[,1:5])
- id label term tf df
- 1 4995.txt 1 阿波罗 1 0.0000573263
- 2 16443.txt 1 阿尔卑斯山 1 0.0000573263
- 3 12897.txt 1 阿富汗 2 0.0001719789
- 4 7001.txt 1 阿富汗 1 0.0001719789
- 5 9427.txt 1 阿富汗 1 0.0001719789
- 6 12368.txt 1 阿哥 1 0.0001146526
————————————————————————————————————————————
4、分词之后文档如何整理?——构造一个单词一个文档名一个label
分词之后,一个文档可能就有很多单词,应该每个单词都单独列出来,并且一个单词一个文档名一个label。
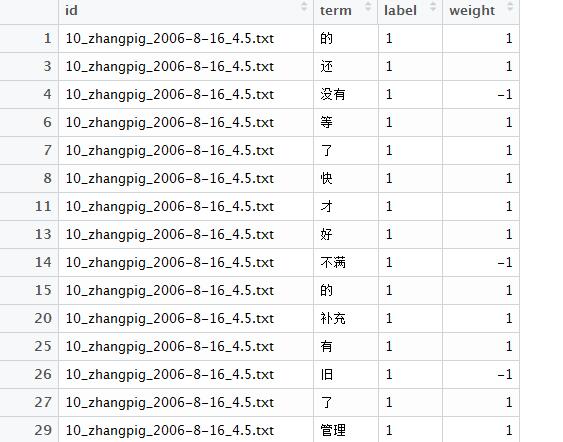
图 2
- system.time(x <- segmentCN(strwords = sentence))
- #每次可能耗费时间较长的过程,都要使用少量数据预估一下时间,这是一个优秀的习惯
- temp <- lapply(x, length) #每一个元素的长度,即文本分出多少个词
- temp <- unlist(temp) #lapply返回的是一个list,所以3行unlist
- id <- rep(test[, "id"], temp) #将每一个对应的id复制相应的次数,就可以和词汇对应了
- label <- rep(test[, "label"], temp)#id对应的情感倾向标签复制相同的次数
- term <- unlist(x) #6行将list解散为向量
- testterm <- as.data.frame(cbind(id, term, label), stringsAsFactors = F)
- #将一一对应的三个向量按列捆绑为数据框,分词整理就基本结束了
代码解读:segmentCN是分词函数;lapply求得每个文本单词个数;
unlist,可以让单词变成向量化,单词操作的时候都需要这步骤,比如前面对单词进行清洗,需要展平数据;
rep,重复id以及label,按照单词个数,rep(c("id","su"),c(2,1)),执行之后为“id”“id”“su”。
————————————————————————————————————————————
5、情感打分
5.1 关联情感词
现在有了图2的数据以及情感词典数据图3,以term为主键,进行join合并。情感词典中没有的词,则删除。
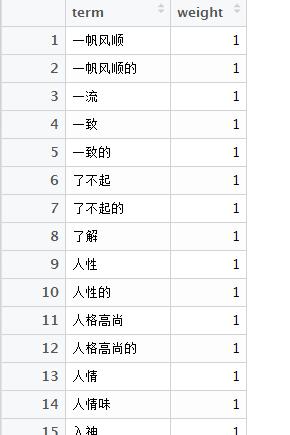
图 3
- library(plyr)
- testterm <- join(testterm, posneg)
- testterm <- testterm[!is.na(testterm$weight), ]
- head(testterm)
代码解读:join,以term进行左关联合并,在A表中,会多出来weigh的一列,但是会出现(1,NA,2,3,NA),一些没有匹配到的NA,
用[is.na(testterm$weight),]来进行删除。
5.2 情感分数
有了图2的id+weight列,就可以直接分组汇总,比如aggregate,其他汇总函数可见比博客:R语言数据集合并、数据增减
- dictresult <- aggregate(weight ~ id, data = testterm, sum)
对weight列以文本id分组求和,即为情感打分。
5.3 情感偏向
有了情感分数,我想单单知道这些ID正负,就像图2中的label。
可以利用布尔向量建立连接。
- dictlabel <- rep(-1, length(dictresult[, 1]))
- dictlabel[dictresult$weight > 0] <- 1
- dictresult <- as.data.frame(cbind(dictresult, dictlabel), stringsAsFactors = F)
先生成一个原数列长度的-1数列;
在原数列$weight>0会生成一个布尔向量,然后进行赋值,就可以构造label了。
——代码很多来自《数据挖掘之道》的情感分析章节。























 3521
3521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









