







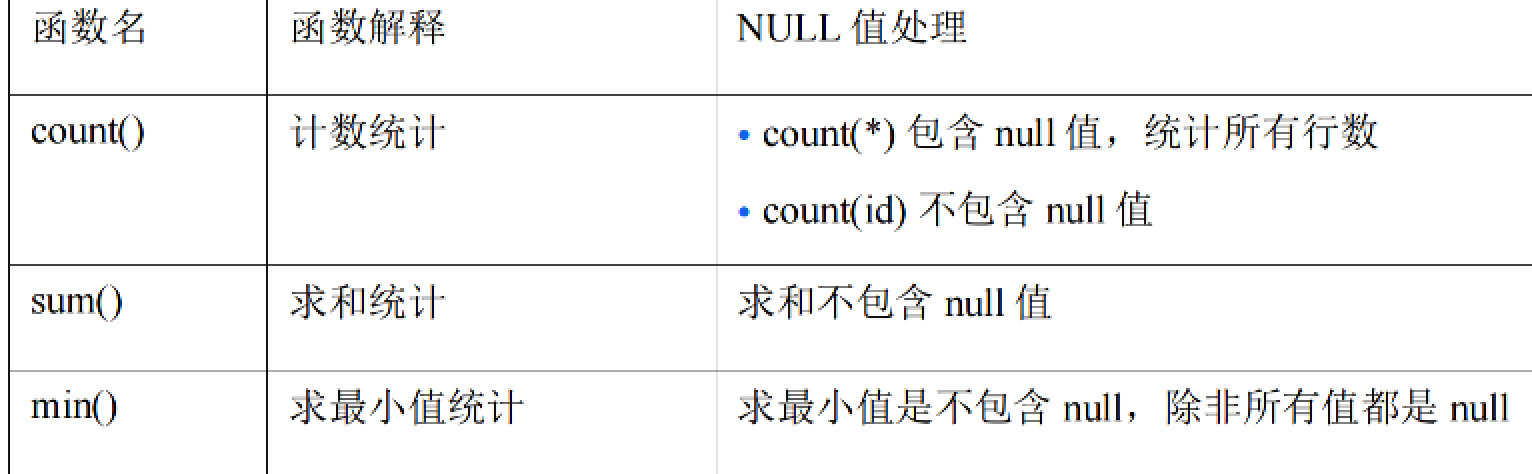
1.Struct类型
Struct结构体,通过相关的不同类型数据来描述一个数据对象
#创建数据库 hive> create database hive_test; OK Time taken: 0.418 seconds hive> use hive_test; OK Time taken: 0.08 seconds #建表语句 create table struct_test( id int, course struct<course:string, score:int>) row format serde 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' with serdeproperties( 'collection.delim'=',', 'field.delim'='\t', 'serialization.format'='\t');
#导入数据
[root@hadoop001 ~]# vim /root/struct_test.data
1 English,80
2 Math,89
3 Chinese,95
hive> load data local inpath 'struct_test.data' overwrite into table struct_test;
OK
#查询单个元素
hive> select id,course.course from struct_test where id = 1;
OK

2.Array类型
Array数组,表示一组相同数据类型的集合,下标从0开始,可以用下标访问
#建表
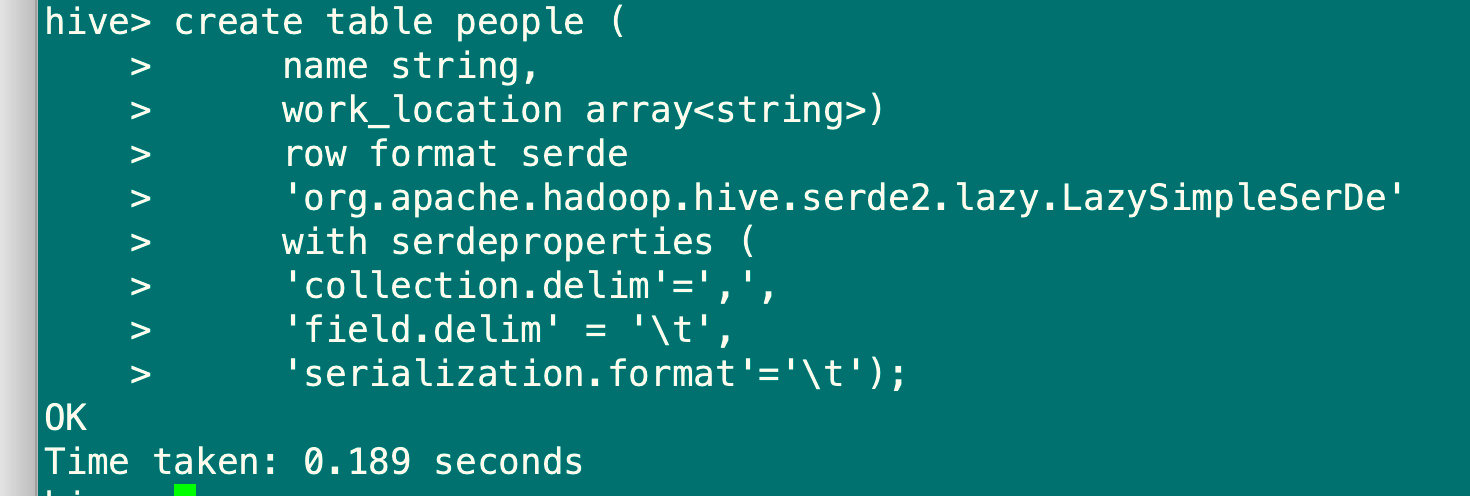
hive> create table people (
name string,
work_location array<string>)
row format serde
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
with serdeproperties (
'collection.delim'=',',
'field.delim' = '\t',
'serialization.format'='\t');
[root@hadoop001 ~]# vim person.data
James beijing,tianjin,shanghai,wuhan
Curry chengdu,new york,london
hive> load data local inpath 'person.data' overwrite into table people;
OK
Time taken: 0.509 seconds
hive> select * from people;
OK

#查询数组的某个元素
hive> select name,work_location[1] from people where name='James';

3.Map类型
Map映射,key-value
#建表语句
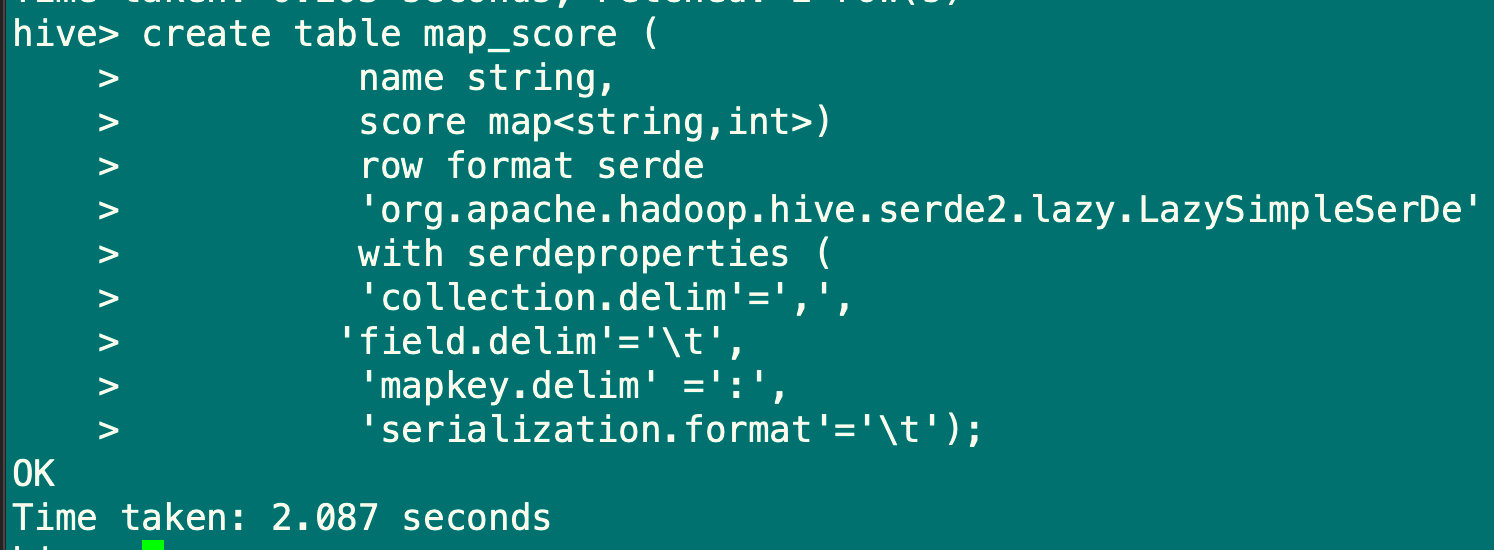
hive> create table score (
name string,
score map<string,int>)
row format serde
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
with serdeproperties (
'collection.delim'=',',
'field.delim'='\t',
'mapkey.delim' =':',
'serialization.format'='\t');
#导入数据
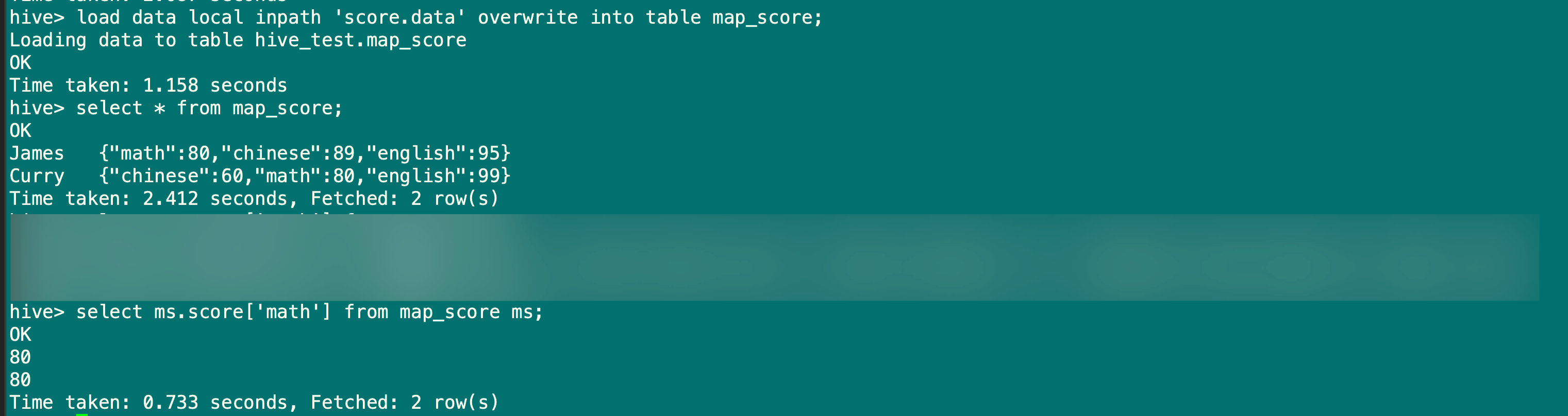
[root@hadoop001 ~]# vim score.data
James math:80,chinese:89,english:95
Curry chinese:60,math:80,english:99
hive> load data local inpath 'score.data' overwrite into table map_score;
hive> select ms.score['math'] from map_score ms;
4.DDL数据定义语言
4.1 对数据库的操作
4.1.1 创建数据库
#默认的创建数据库方式
hive> create database mydwd;
OK
Time taken: 0.255 seconds
#创建数据库,判断数据库是否存在,如果存在则不报错也不创建,如果不存在则创建
hive> create database if not exists mydwd;
OK
Time taken: 0.068 seconds
#创建数据库并指定hdfs的存储位置
hive> create database mydwd2 location '/root/mydwd2';
OK

4.1.2 修改数据库
hive> alter database mydwd set dbproperties('createtime' = '2022-06-28');
#可以使用alter database命令修改数据库的一些属性,但是数据库的元数据是不可更改的,包括数据库的位置和数据库名

4.1.3 查看数据库
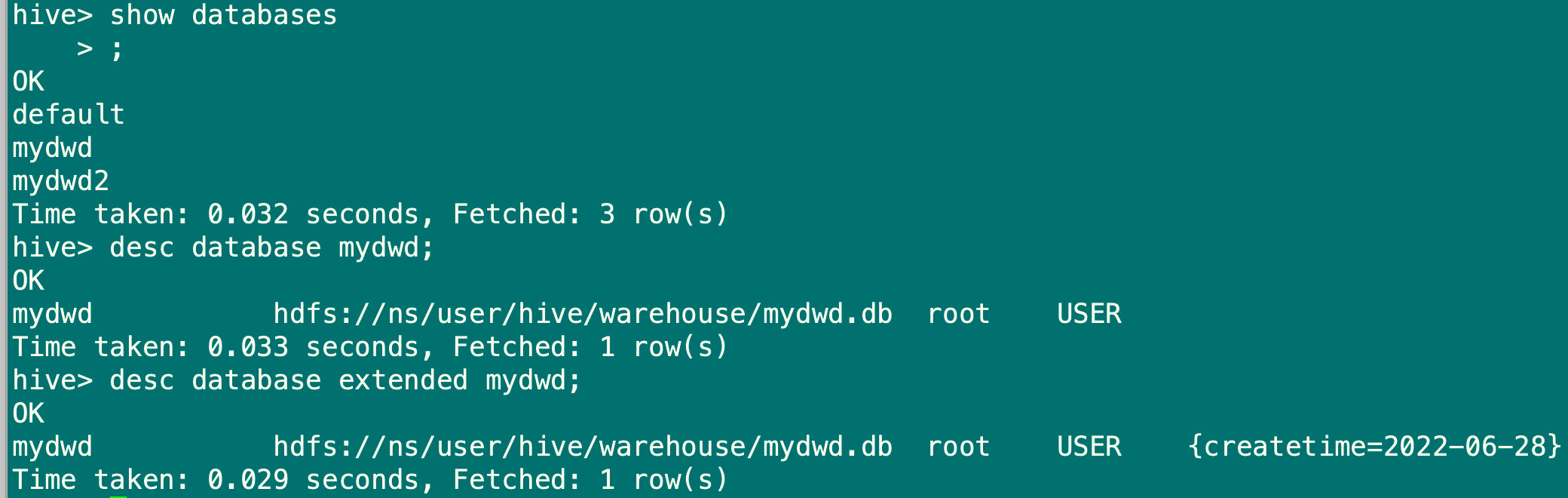
#查看所有数据库
show databases;
#查看数据库基本信息
desc database mydwd;
#查看数据库更多信息
desc database extended mydwd;
4.1.4 删除数据库
#删除一个空数据库,如果数据库有数据则会报错
hive> drop database mydwd;
#删除数据库以及下面的表
hive> drop database mydwd cascade;

4.2 对表的操作
4.2.1 创建表
1、使用create创建表
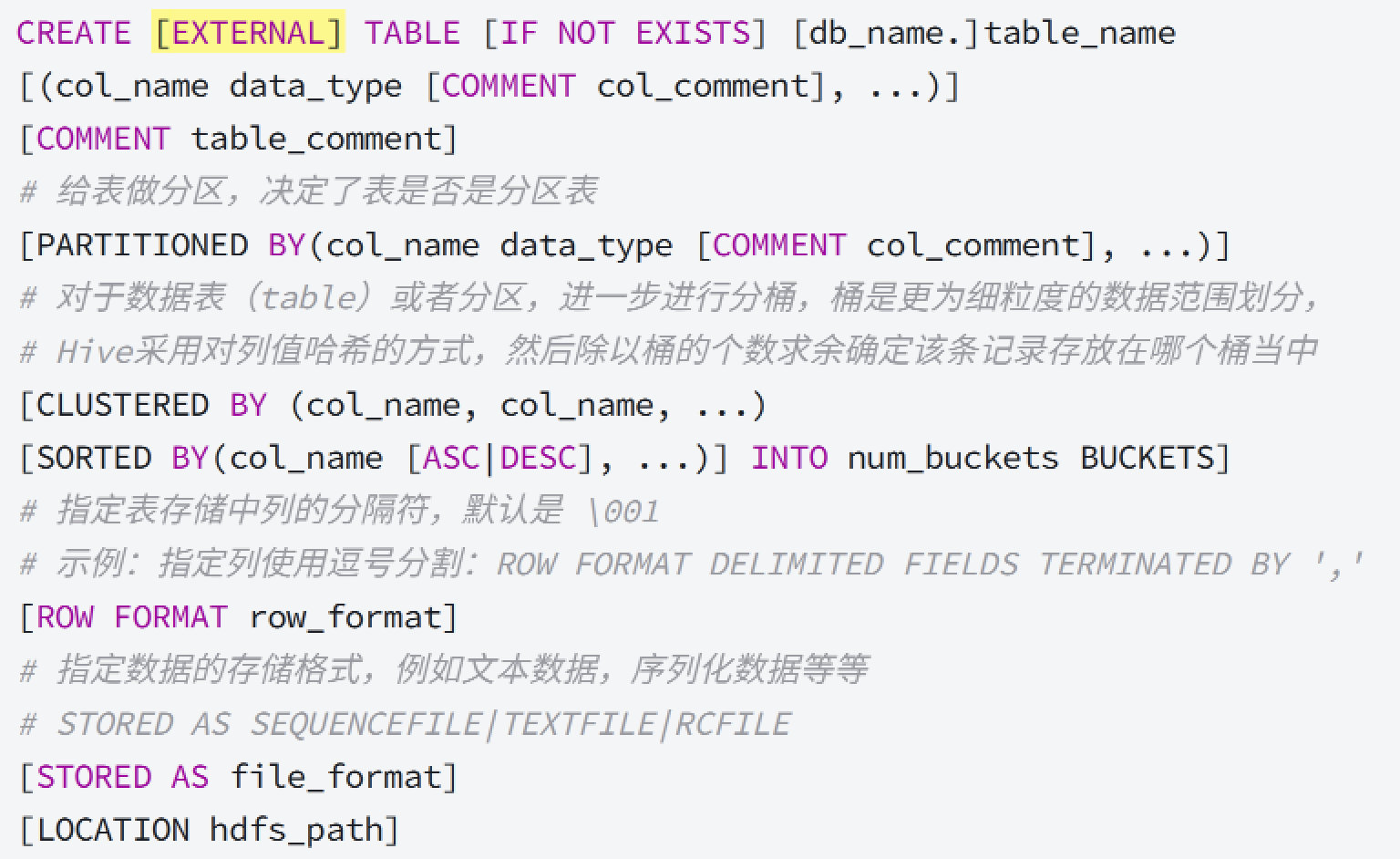
1.1 创建一张内部表
hive> create table stu(
stu_id bigint comment '学生ID',
stu_name string comment '学生名称'
) comment '学生表';
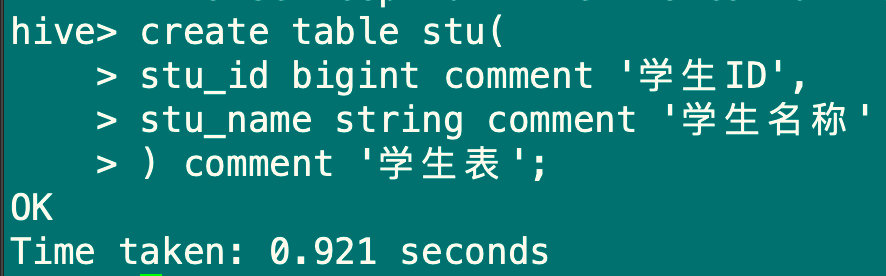
#注意:hive解决中文乱码问题
①在Hive元数据存储的Mysql数据库中,执行以下SQL:
#修改字段注释字符集
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
#修改表注释字符集
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(20000) character set utf8;
#修改分区参数,支持分区建用中文表示
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(20000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(20000) character set utf8;
#修改索引名注释,支持中文表示
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
#修改视图,支持视图中文
ALTER TABLE TBLS modify COLUMN VIEW_EXPANDED_TEXT mediumtext CHARACTER SET utf8;
ALTER TABLE TBLS modify COLUMN VIEW_ORIGINAL_TEXT mediumtext CHARACTER SET utf8;
②修改hive-site.xml中Hive读取元数据的编码
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.5.102:3306/hivemeta?createDatabaseIfNotExist=true&useSSL=false&characterEncoding=UTF-8</value>
</property>
#在修改之前创建的表不起作用
1.2 创建外部表
create external table stu_ext(
stu_id bigint comment '学生ID',
stu_name string comment '学生姓名')
comment '学生表'
location '/user/bigdata/hive_test/stu_ext';
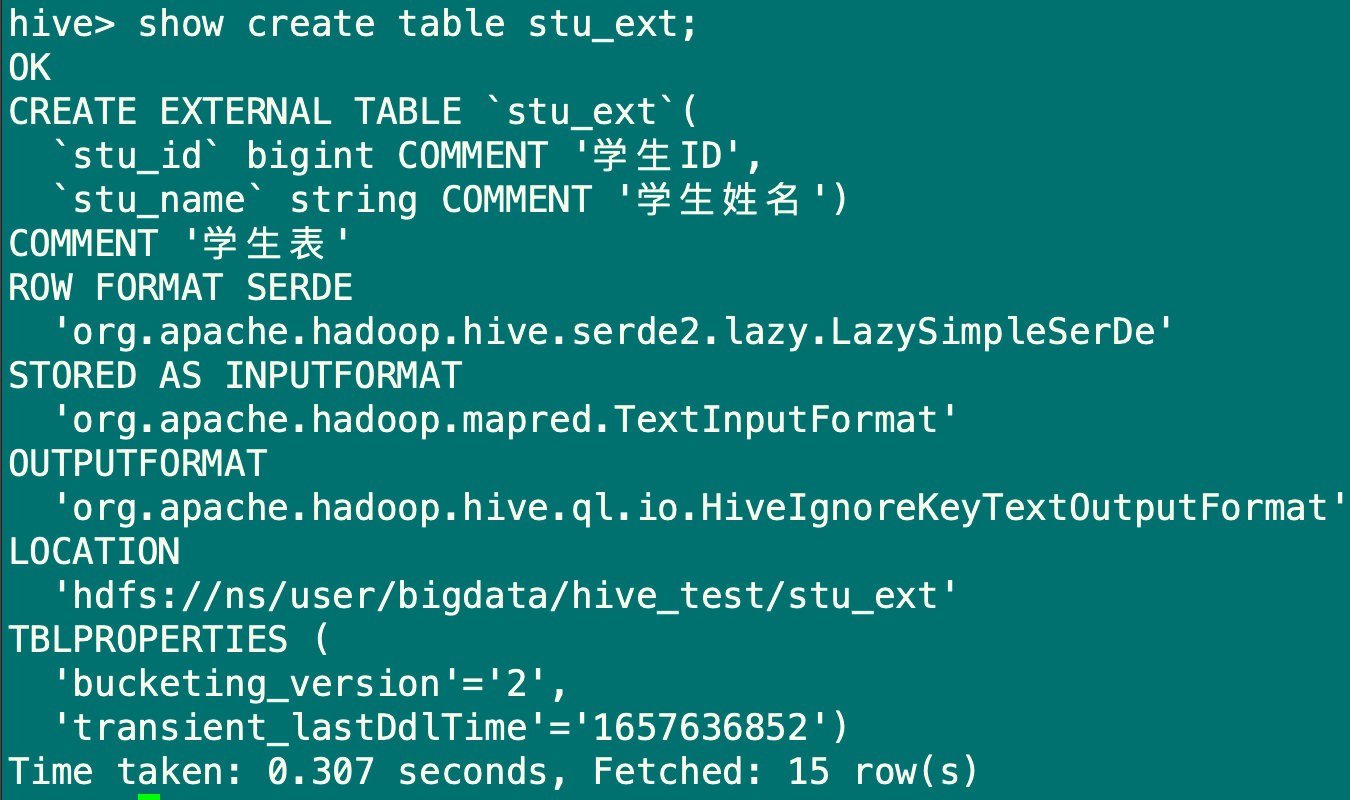
1.3 创建表并指定字段之间用\t分隔符
create external table if not exists stu_ext1(
stu_id Bigint comment '学生ID',
stu_name string comment '学生名称')
comment '学生表'
row format delimited fields terminated by '\t'
stored as textfile
location '/user/bigdata/hive_test/stu_ext1';
#指定表存储中列的分隔符,默认是\001
#示例:指定列使用逗号分隔: row format delimited fields terminated by ','
1.4 创建分区表
create table sub_report(
stu_id Bigint comment '学生ID',
sub_name string comment '学科名称',
sub_score float comment '学科成绩')
comment '学生成绩表'
partitioned by (pt string comment '季度分区日期')
row format delimited fields terminated by ',';
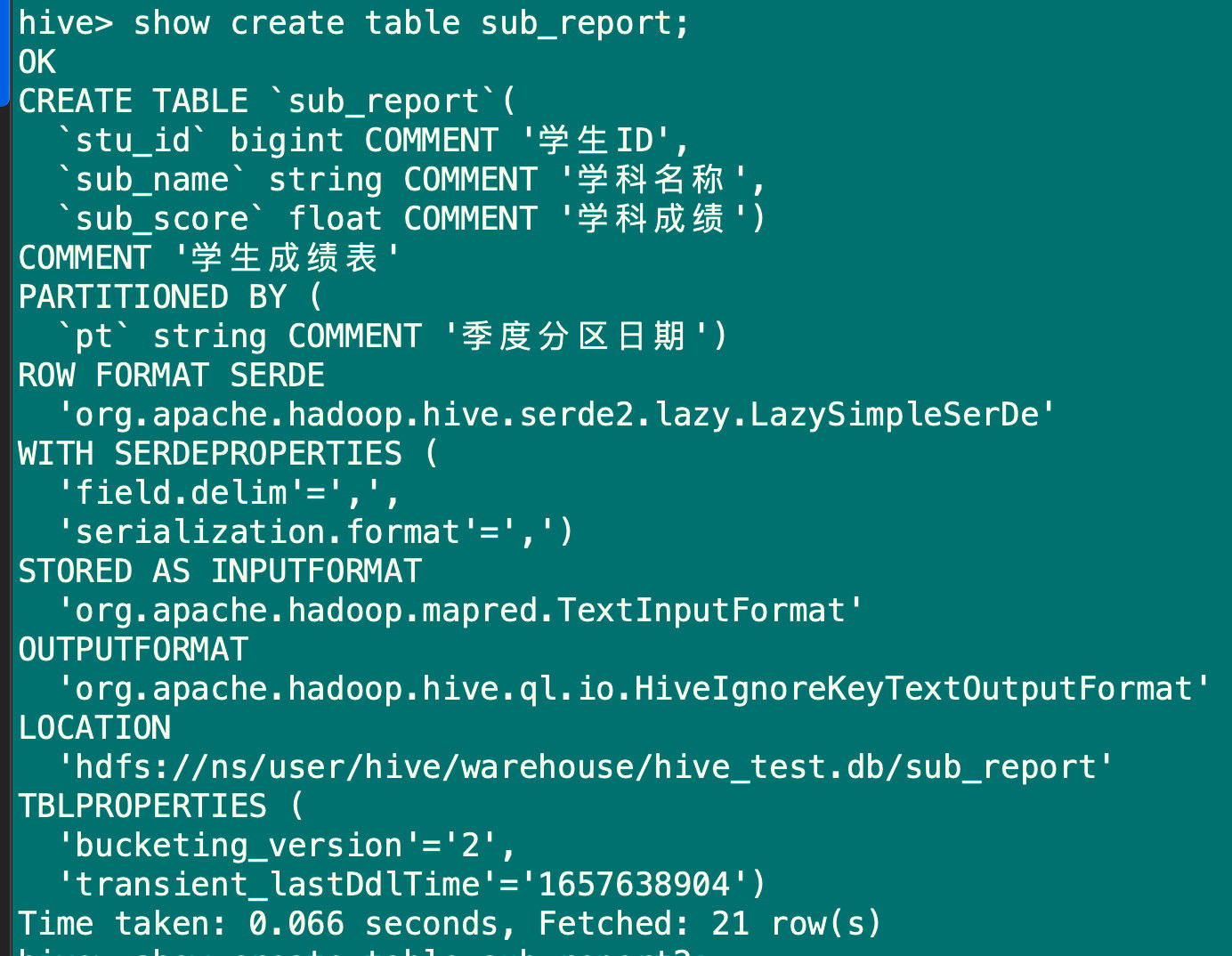
1.5 创建含有多个分区的数据表
create table sub_report2 (
stu_ID Bigint comment '学生ID',
sub_name string comment '学科名称',
sub_score float comment '学科成绩')
comment '学生成绩表'
partitioned by (
`year` string comment '年度分区日期',
`month` string comment '月度分区日期');

1.6 创建分桶数据表
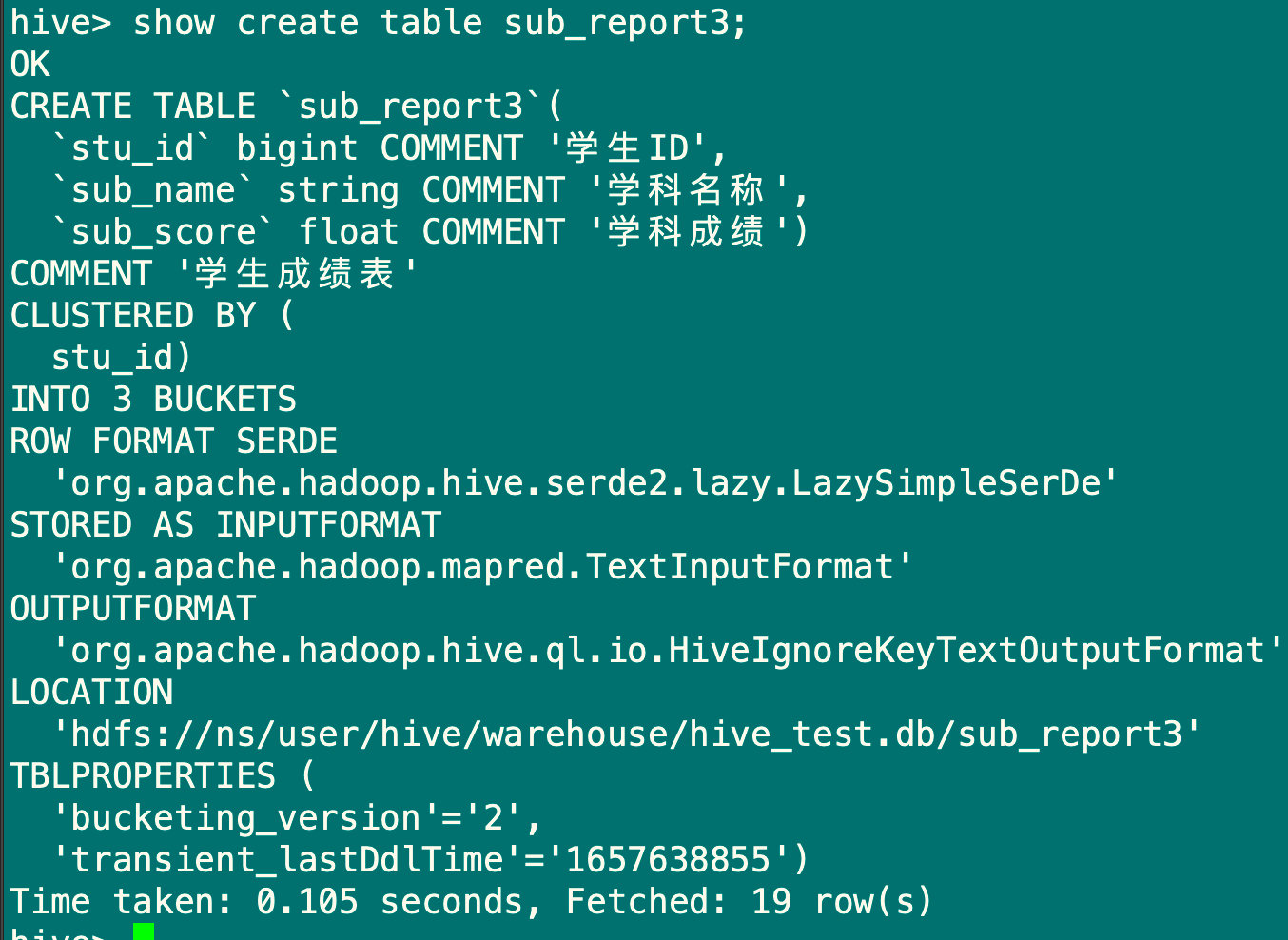
create table sub_report3(
stu_id Bigint comment '学生ID',
sub_name string comment '学科名称',
sub_score float comment '学科成绩')
comment '学生成绩表'
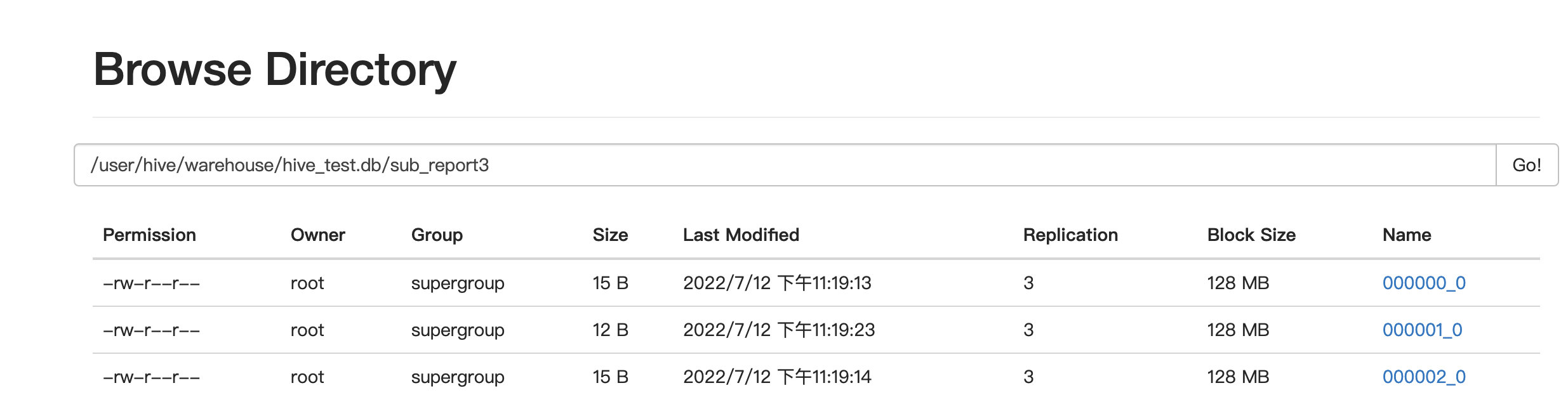
clustered by(stu_id) into 3 buckets;
#对于数据表或者分区,进一步进行分桶,桶是更为细粒度的数据范围划分
#hive 采用对列值 hash 的方式,然后除以桶的个数求余确定该条记录存放在哪个桶当中
#数据插入到分桶表时需要设置自动分桶开关
set hive.enforce.bucketing=true;
[root@hadoop001 ~]# vim sub_report3data
1,math,89
2,chinese,90
3,english,88
hive> load data local inpath 'sub_report3data' overwrite into table sub_report partition(pt='20220712');
hive> select * from sub_report;
#sub_report中数据导入到sub_report3中
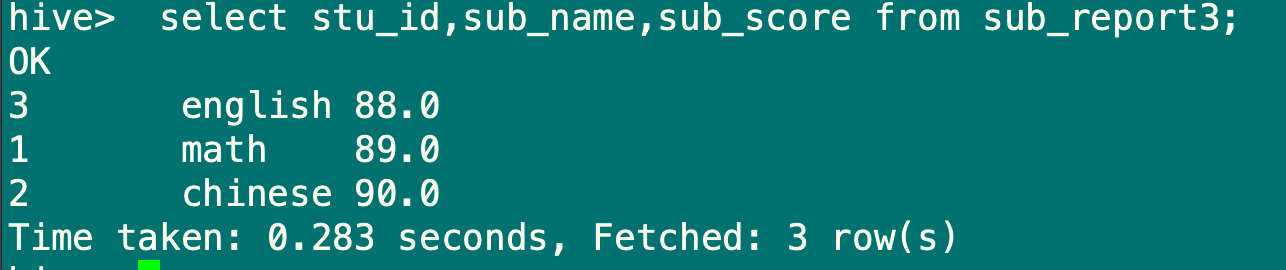
hive> insert overwrite table sub_report3 select stu_id,sub_name,sub_score from sub_report;
hive> select stu_id,sub_name,sub_score from sub_report3;

1.7 创建分区分桶表
create table sub_report4(
stu_id Bigint comment '学生ID',
sub_name string comment '学科名称',
sub_score float comment '学科成绩')
comment '学生成绩表'
partitioned by (pt string comment '季度分区日期')
clustered by(stu_id) into 3 buckets
row format delimited fields terminated by ',';
#数据插入分桶表时需要设置自动分桶开关
set hive.enforce.bucketing=true;
#将sub_report中数据导入到sub_report4中
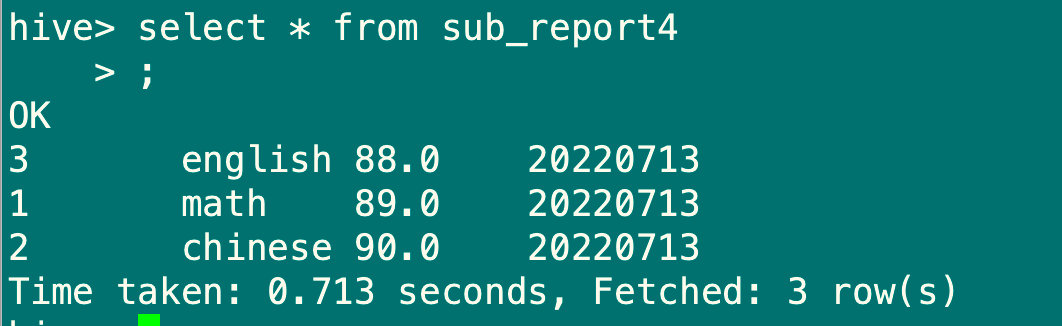
insert overwrite table sub_report4 partition(pt='20220713')
select stu_id,sub_name,sub_score from sub_report;

2、根据查询结果创建表
使用create table … as select… CTAS方式通过查询来创建一张新表,这样可以根据已有的表来创建子表,对数据分析和优化都是有很大好处的
insert into table stu values(1,'James'),(2,'Curry'),(4,'Mike'),(5,'Jack'),(6,'Mark');
create table stu2 as select stu_id,stu_name from stu;


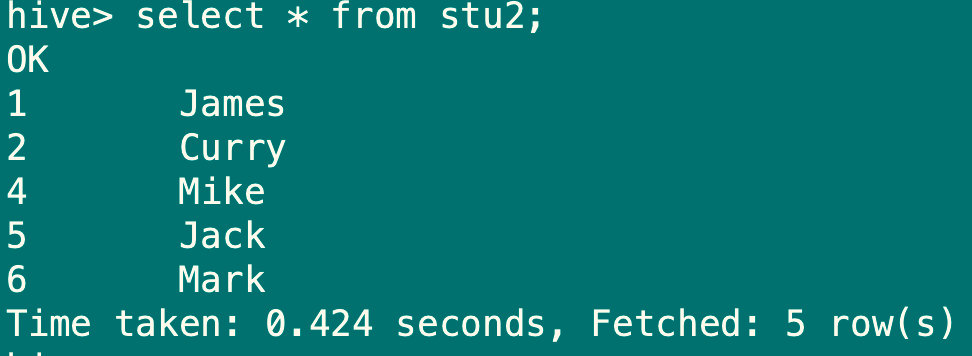
#使用查询创建表,select中选取的列名会作为新表的列名(所以通常都要取别名)
#使用查询创建表的方式只能创建内部表
3、使用like创建相同结构的表
create table stu3 like stu;
#用来复制表结构,不会复制数据
#需要外部表的话,通过create external table like 指定


4.2.2 创建表和删除表
1、修改表名称
alter table stu2 rename to stu21;

2、增加、修改列
alter table stu21 add columns(stu_sex string comment '学生性别');

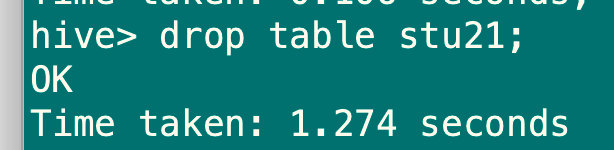
3、删除表
drop table stu21;
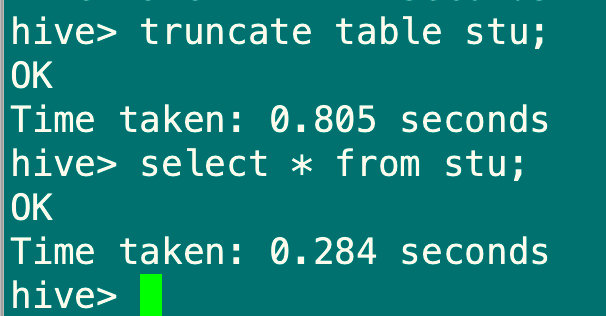
4、清空表
truncate table stu;
#truncate操作只能清空内部表
#truncate和drop区别:如果hdfs开启了回收站,drop删除的数据可以从回收站恢复,需要重新创建数据表。truncate清空的表是不进入回收站的,所以无法恢复
5.DML数据操纵语言
5.1 向Hive表中加载数据
5.1.1 直接向数据表中插入数据
insert into table stu values(1,'James'),(2,'Curry'),(4,'Mike'),(5,'Jack'),(6,'Mark');

5.1.2 通过load方式加载本地数据
#准备数据
root@hadoop001 ~]# vim score.data
1,语文,89
1,数学,90
1,英语,48
2,美术,89
2,体育,88
2,语文,39
3,数学,55
3,历史,79
4,英语,80
4,语文,88
8,政治,100
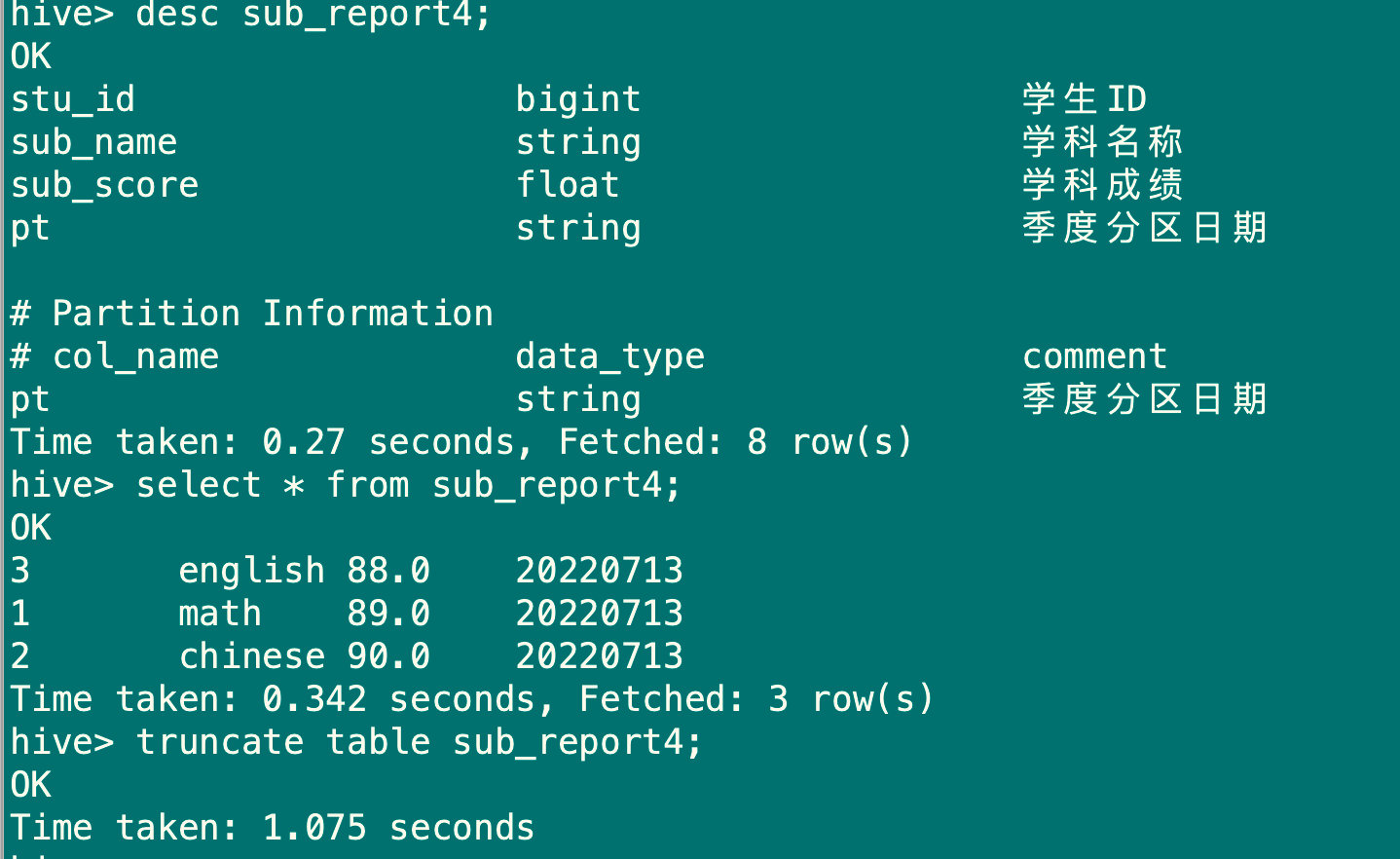
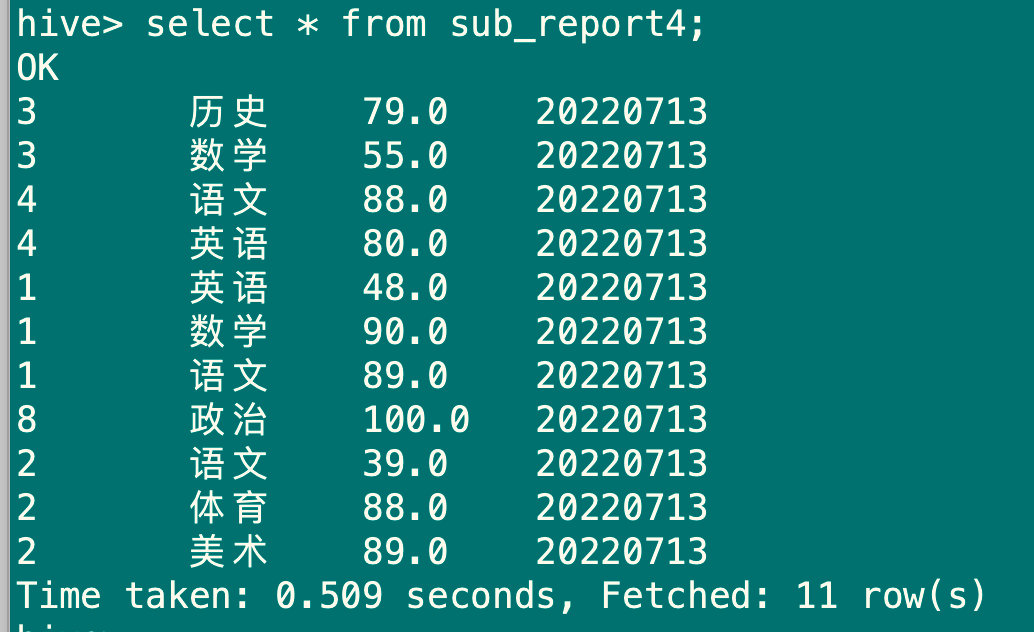
#清空sub_report4表
truncate table sub_report4;
#加载数据
load data local inpath 'score.data' overwrite into table sub_report4 partition(pt='20220713');
select * from sub_report4;

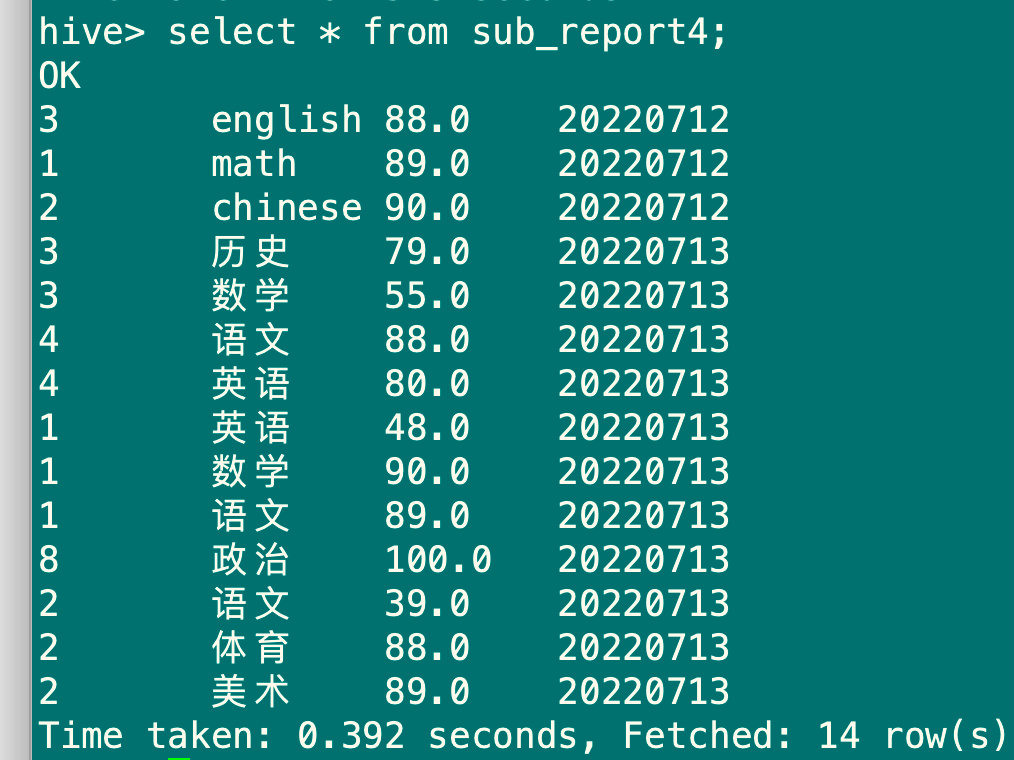
5.1.3 通过查询方式加载数据
insert overwrite table sub_report4 partition(pt='20220712')select stu_id,sub_name,sub_score from sub_report;
select * from sub_report4;
5.1.4 在创建表时指定location加载数据
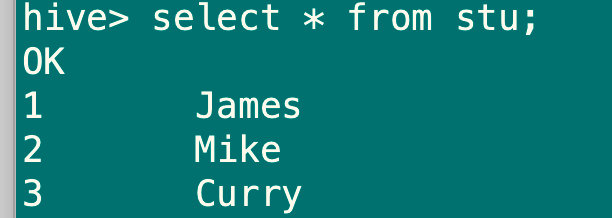
hive> insert into table stu values(1,'James'),(2,'Mike'),(3,'Curry');
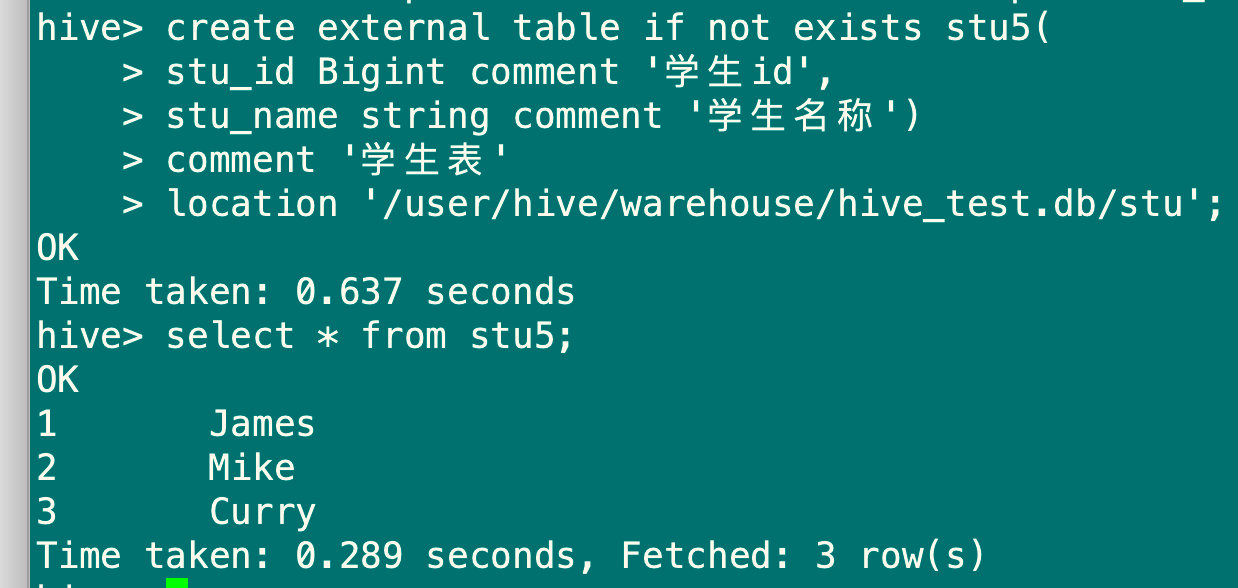
create external table if not exists stu5(
stu_id Bigint comment '学生id',
stu_name string comment '学生名称')
comment '学生表'
location '/user/hive/warehouse/hive_test.db/stu';
#这里的location是从stu表里查询的,不同路径需要手动修改
5.2 从Hive表中导出数据
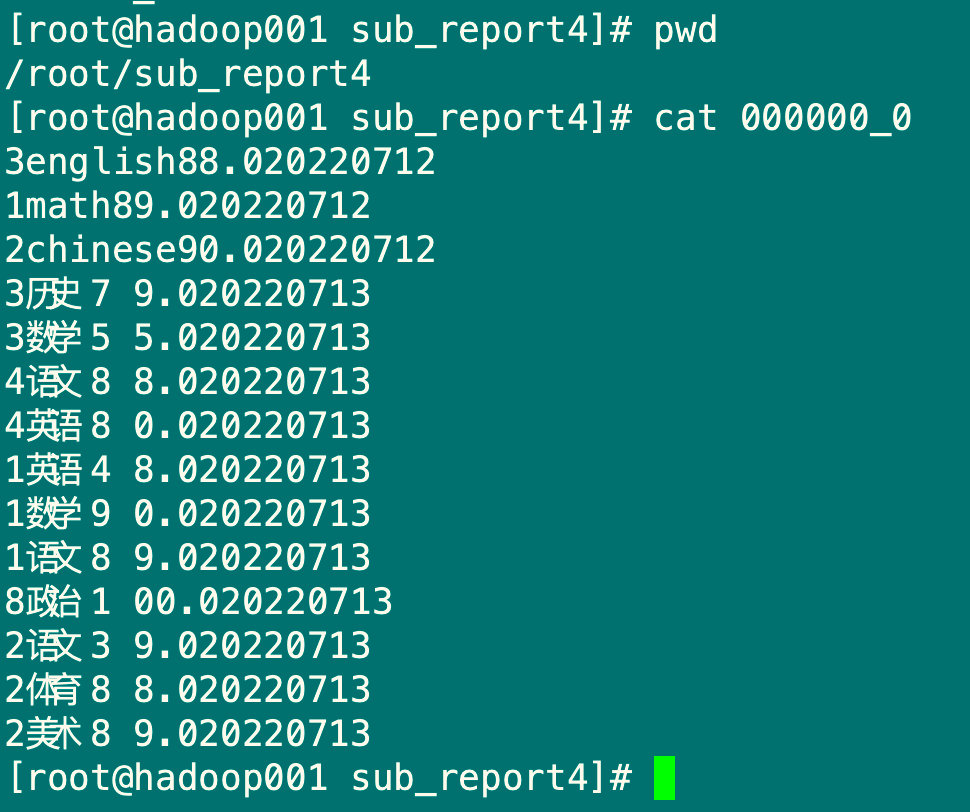
5.2.1 将查询结果导出到本地
insert overwrite local directory '/root/sub_report4' select * from sub_report4;

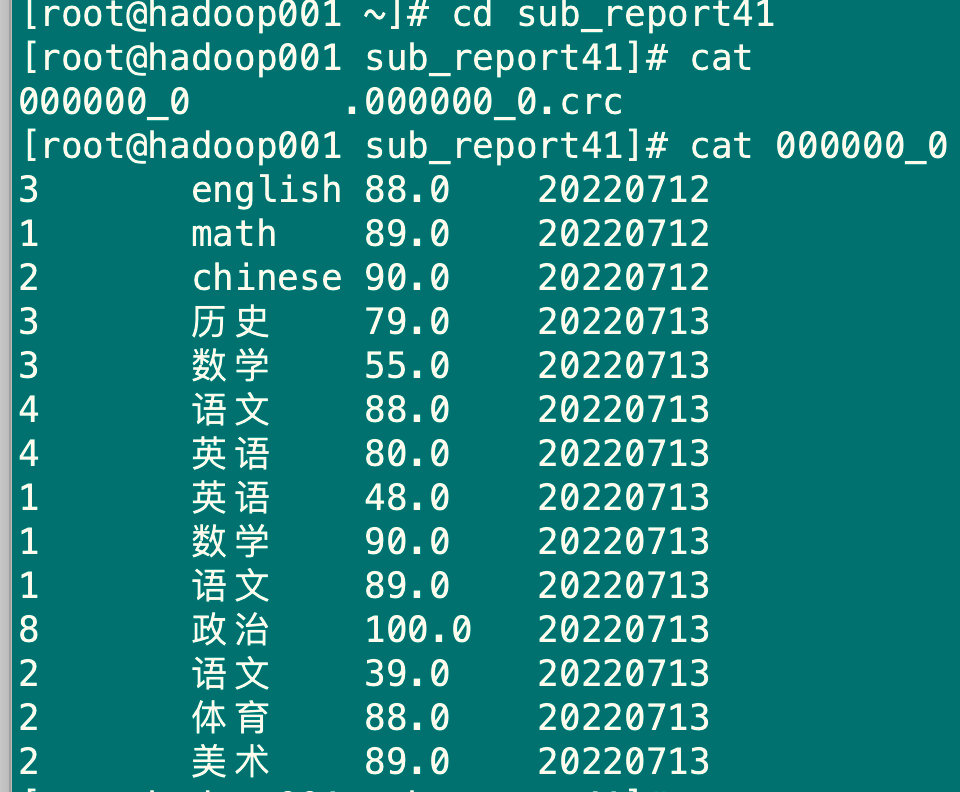
5.2.2 将查询结果格式化导出到本地
insert overwrite local directory '/root/sub_report41' row format delimited fields terminated by '\t' select * from sub_report4;

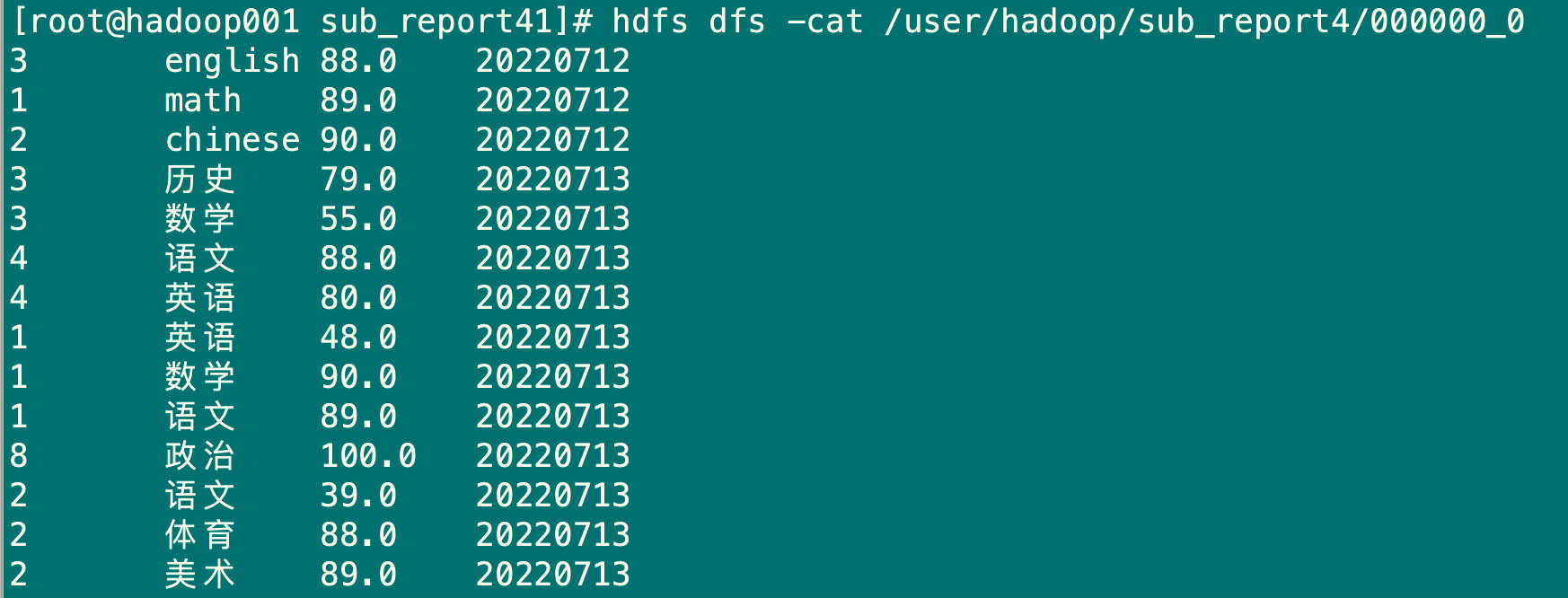
5.2.3 将查询结果导出到hdfs(没有local)
insert overwrite directory '/user/hadoop/sub_report4' row format delimited fields terminated by '\t' select * from sub_report4;
hdfs dfs -ls /user/hadoop/sub_report4
hdfs dfs -cat /user/hadoop/sub_report4/000000_0

6.DQL数据查询语言
6.1 单表查询
6.1.1 select语句
使用all、distinct选项对重读记录的处理,默认是all,distinct表示去掉重复的记录
select * from stu;

6.1.2 where语句
查询过滤条件,支持and、or、between、in、not in
select * from stu where stu_id >2;

6.1.3 group by语句
对查询的结果进行分组聚合,如果使用group by 分组,则select后只能写分组字段或者聚合函数
hive> select sub_name,avg(sub_score) from sub_report4 group by sub_name;
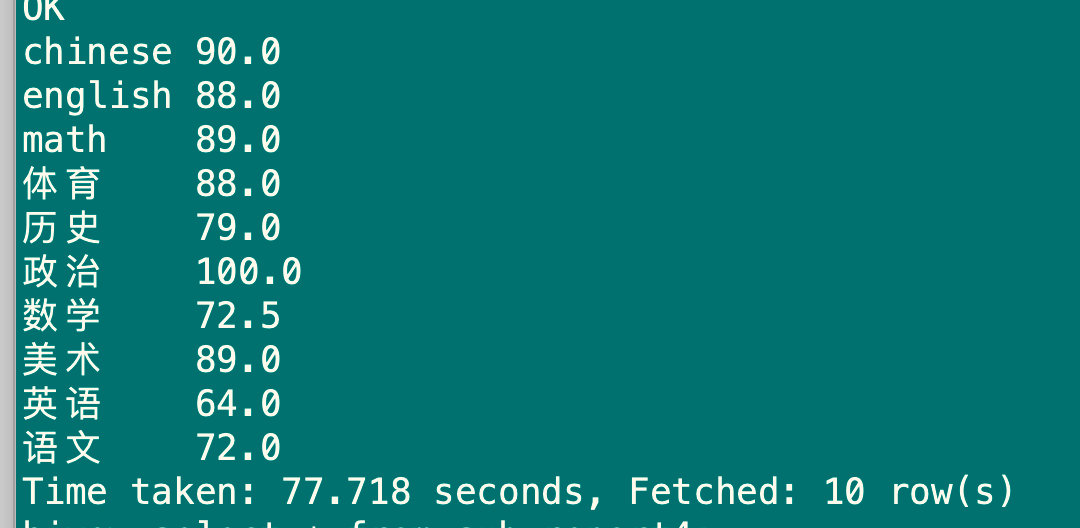
6.1.4 having语句
hiving是在group by分完组之后再对数据进行筛选,having要筛选的字段只能是分组字段或者聚合函数
hive> select sub_name,avg(sub_score) as avg_sub_score from sub_report4 group by sub_name having avg_sub_score>75;
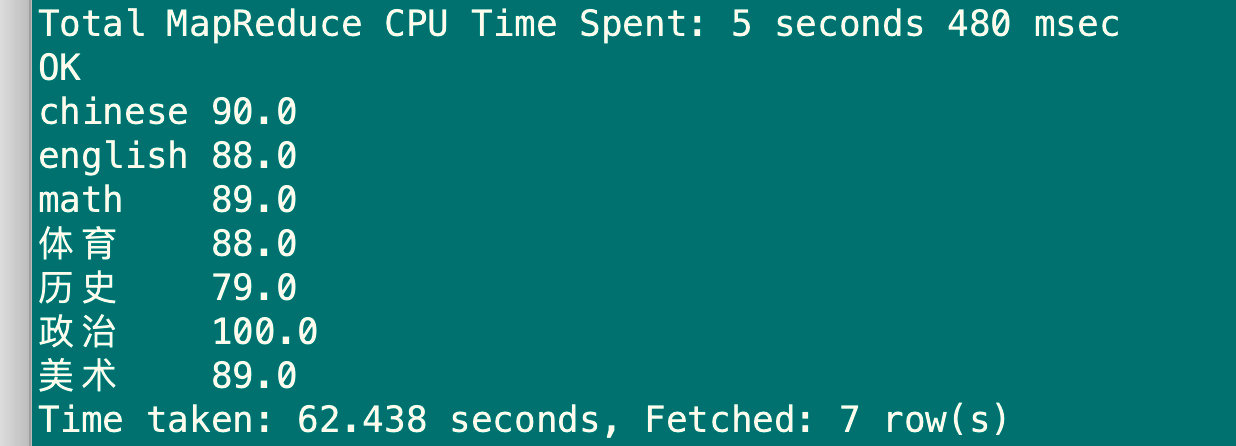
6.1.5 order by语句
order by是全局排序,所以最后只有一个reduce,也就是在一个节点执行,如果数据量太大,就会耗费较长时间,desc是descend 降序意思 ,asc 是ascend 升序意思
select stu_id,sub_score from sub_report4 order by sub_score desc;
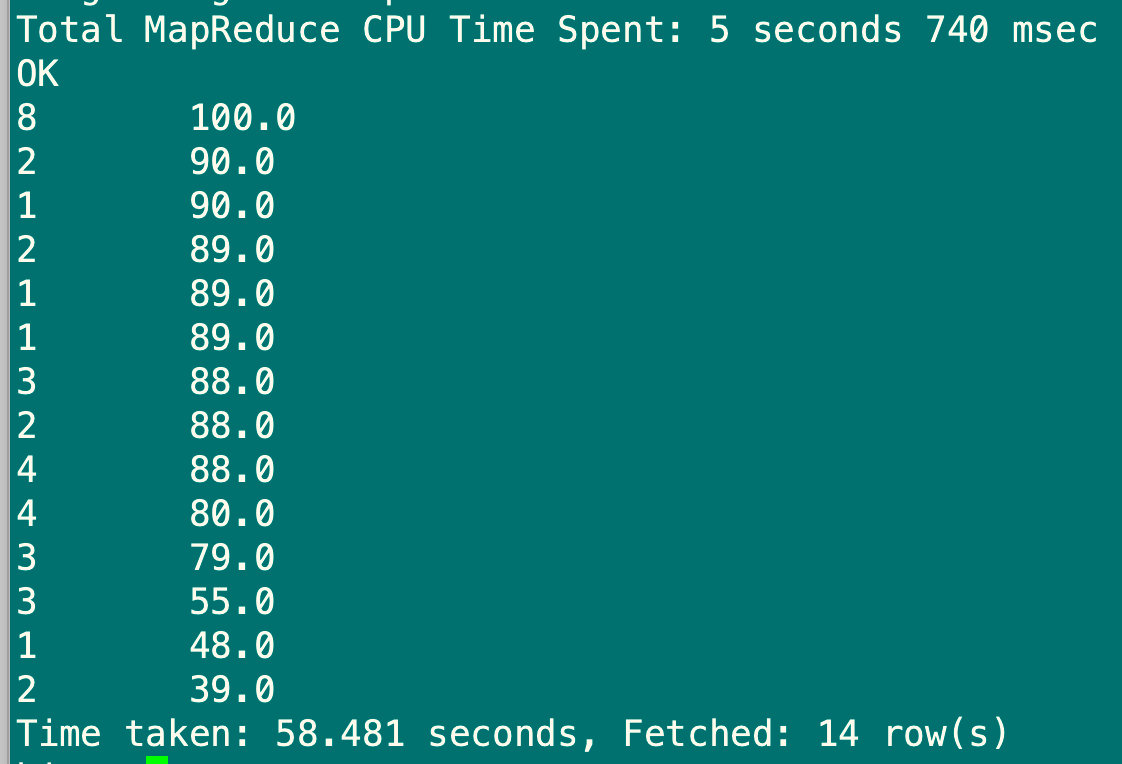
6.1.6 sort by语句
每个MapReduce内部进行排序,对全局结果集来说不是排序
set mapreduce.job.reduces=3;
select stu_id,sub_score from sub_report4 sort by sub_score desc;
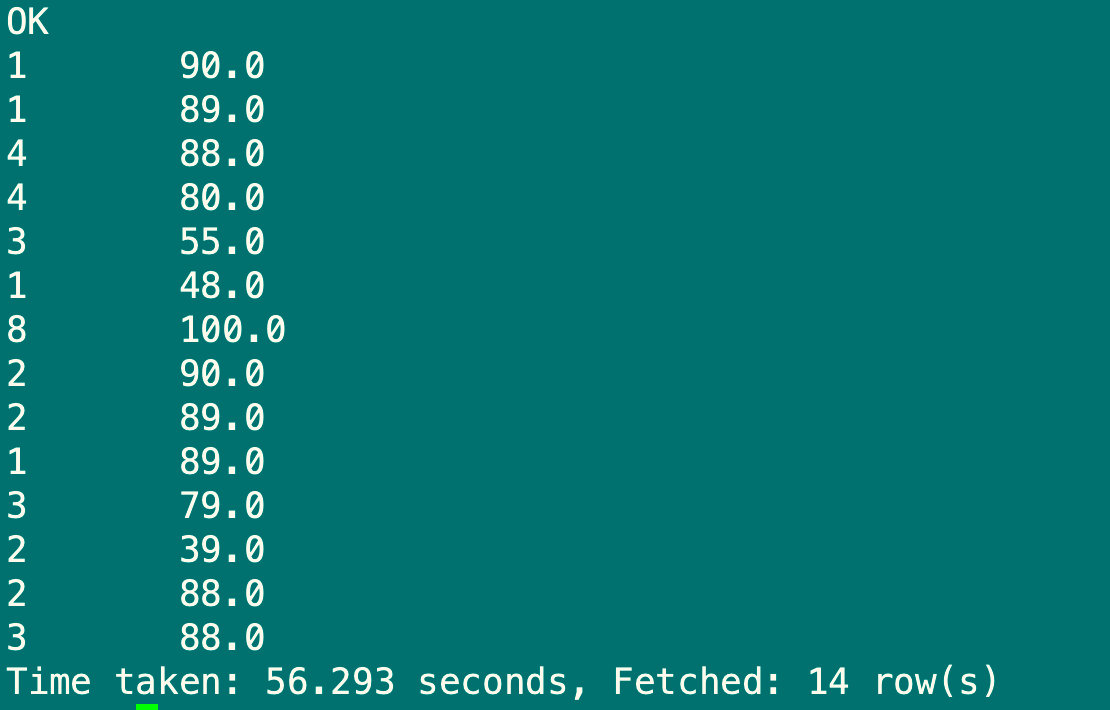
6.1.7 distribute by语句
Distribute by:分区排序,类似MapReducepartition,进行分区结合sort by使用
hive要求distribute by语句要写在sort by语句之前
set mapreduce.job.reduce=3;
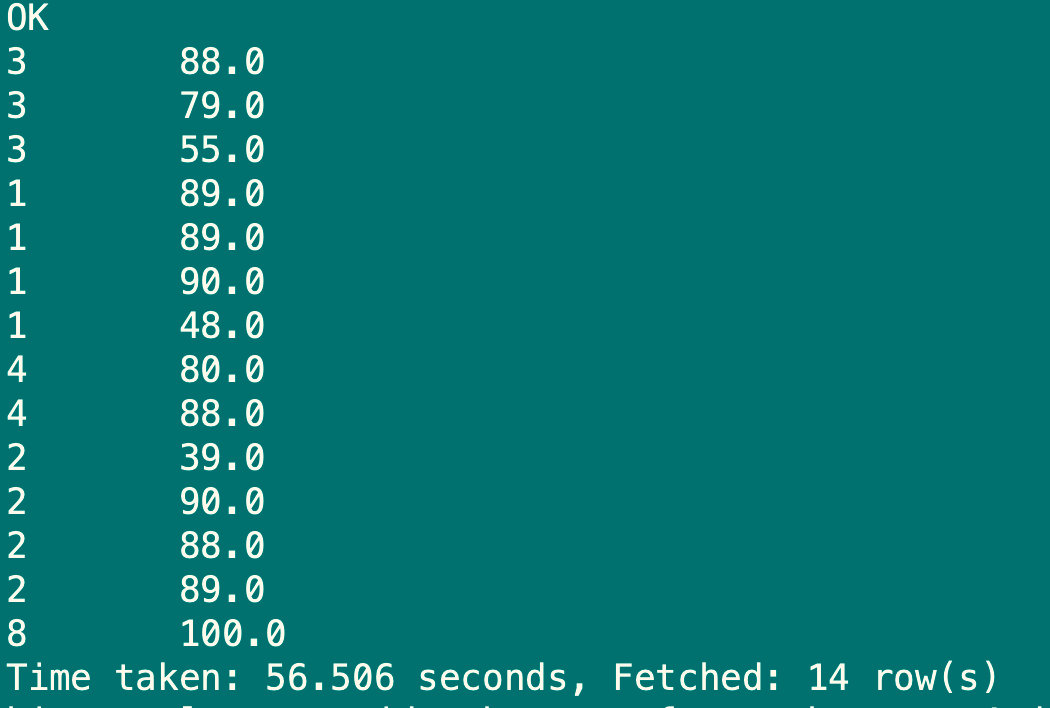
select stu_id,sub_score from sub_report4 distribute by stu_id sort by sub_score;
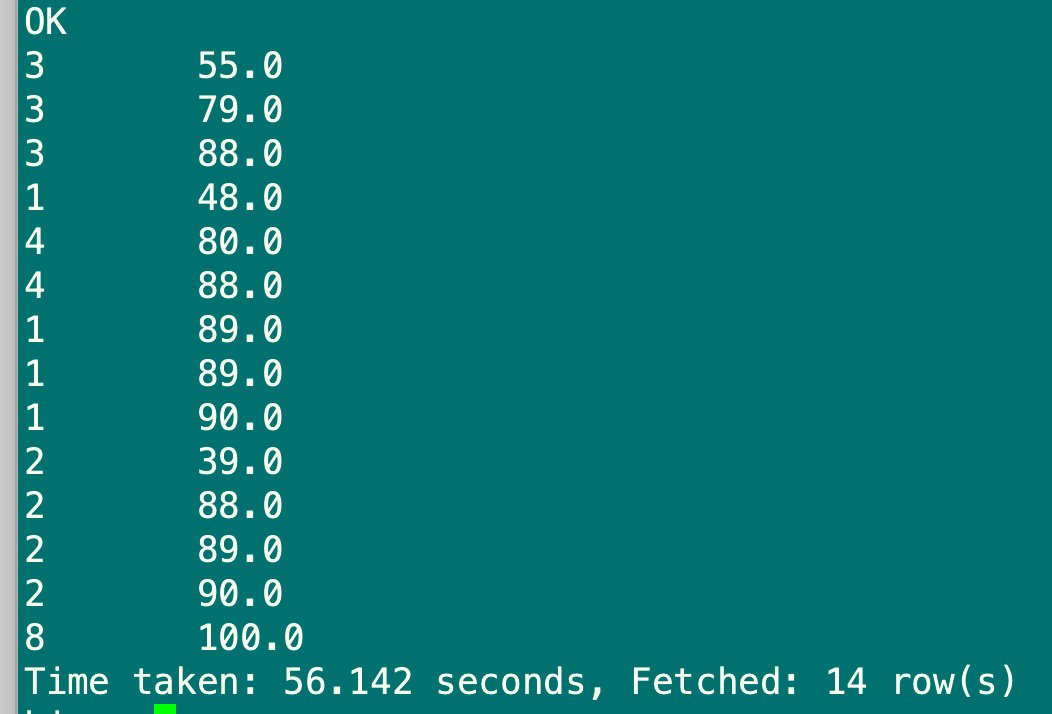
6.1.8 cluster by语句
当distribute by和sort by字段相同时,可以使用cluster by方式,除了具有distribute by功能外还兼具sort by功能,但是排序只能正序排序,不能指定为asc或desc
select stu_id,sub_score from sub_report4 cluster by stu_id;
select stu_id,sub_score from sub_report4 distribute by stu_id sort by stu_id;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BOrtSKbf-1658213282380)(/Users/chenmh/Library/Application Support/typora-user-images/image-20220718161923802.png)]
6.1.9 limit语句
限制查询的记录数
select stu_id,stu_name from stu limit 2;

6.2 关联查询
6.2.1 内连接inner join
只有进行连接的两个表中都存在与连接条件相匹配的数据才会保留下来,inner可省略
select u1.stu_id,u1.stu_name,u2.stu_id,u2.sub_name,u2.sub_score from (select stu_id,stu_name from stu) u1
inner join
(select stu_id,sub_name,sub_score from sub_report4)u2 on (u1.stu_id=u2.stu_id);

6.2.2 左外连接left outer join
左边所有数据都会返回,右边所有符合条件的被返回,outer可省略
select u1.stu_id,u1.stu_name,u2.stu_id,u2.sub_name,u2.sub_score from (select stu_id,stu_name from stu) u1
left join
(select stu_id,sub_name,sub_score from sub_report4)u2 on (u1.stu_id=u2.stu_id);
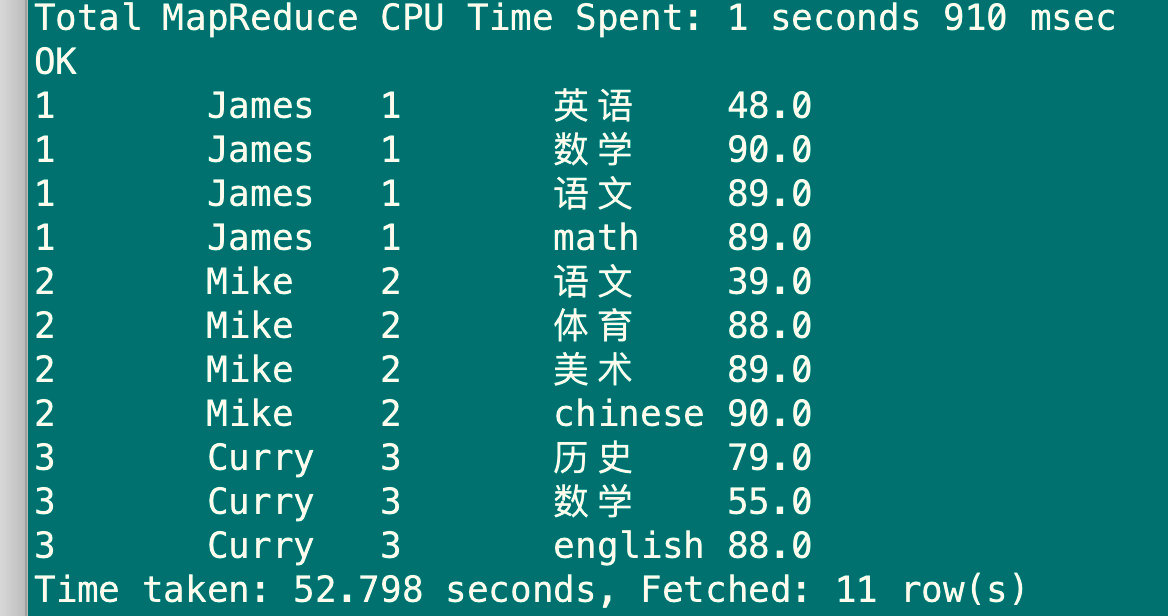
6.2.3 右外连接right outer join
右边所有数据都会返回,左边符合条件的数据返回,outer可省略
select u1.stu_id,u1.stu_name,u2.stu_id,u2.sub_name,u2.sub_score from (select stu_id,stu_name from stu) u1
right join
(select stu_id,sub_name,sub_score from sub_report4)u2 on (u1.stu_id=u2.stu_id);
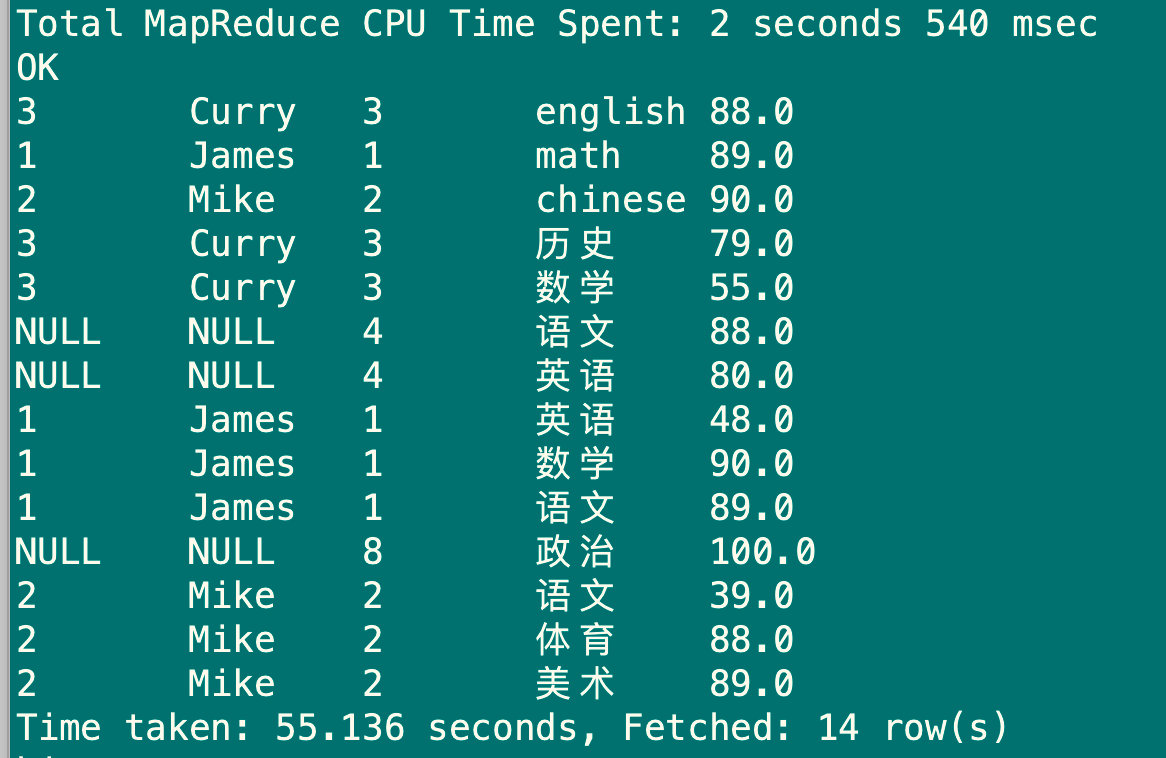
6.2.4 全外连接full outer join
将会返回所有表中的符合条件的记录,如果任一表字段没有符合值的话,那么使null替代,outer可省略
select u1.stu_id,u1.stu_name,u2.stu_id,u2.sub_name,u2.sub_score from (select stu_id,stu_name from stu) u1
full join
(select stu_id,sub_name,sub_score from sub_report4)u2 on (u1.stu_id=u2.stu_id);

7.HIVE函数
7.1 聚合函数

select count(1) as total_sub_score_cnt,
sum(sub_score) as total_sub_score,
max(sub_score) as max_sub_score,
min(sub_score) as min_subject_score,
avg(sub_score) as avg_subject_score
from sub_report4;

7.2 关系运算
hive支持等值=,不等值!==或<>,小于<,大于>,小于等于<=,大于等于>=,空值判断is null,非空判断is not null
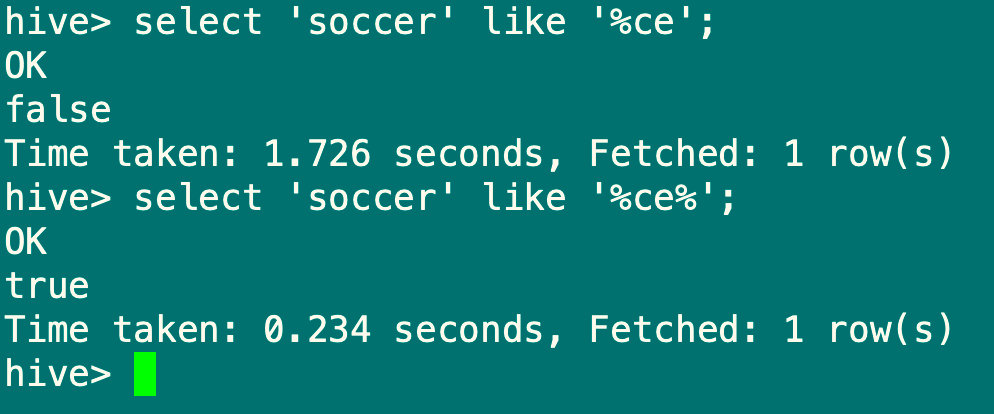
7.2.1 like比较
语法:a like b
操作类型:string
描述:如果字符串a或者字符串b为null,则返回null;如果字符串a复合表达式b的正则语法,则为true,否则为false。b中字符_表示任意单个字符,而字符%表示任意数量的字符
select 'soccer' like '%ce';
select 'soccer' like '%ce%';
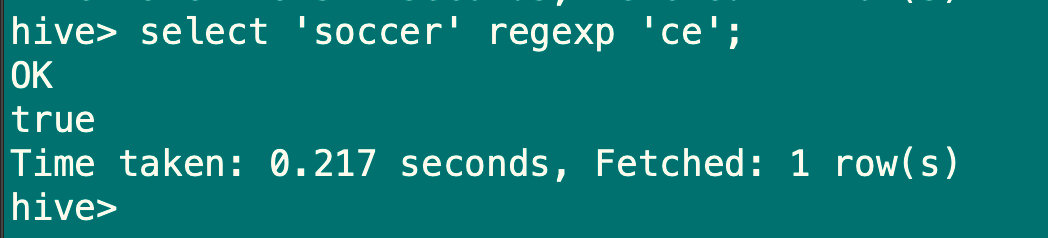
7.2.2 regexp操作
语法:a regexp b
操作类型:string
描述:功能与rlike类似
select 'soccer' regexp 'ce';
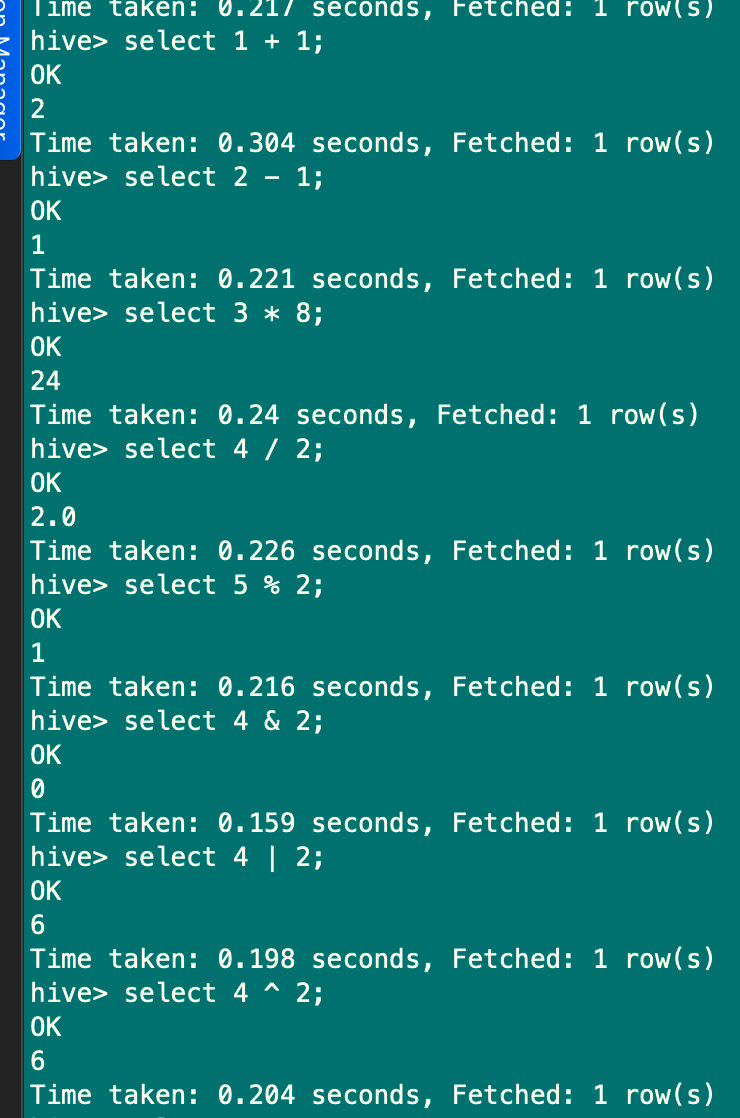
7.3 数学运算
支持所有数值类型:加+,减-,乘*,除/,取余%,位与&,位或|,位异或^,位取反~
select 1 + 1;
select 2 - 1;
select 3 * 8;
select 4 / 2;
select 5 % 2;
select 4 & 2;
select 4 | 2;
select 4 ^ 2;
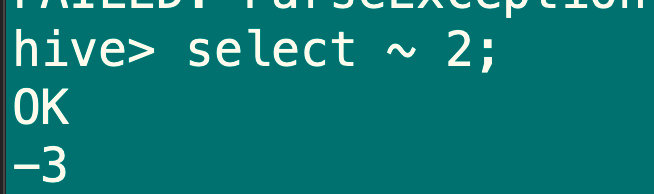
select ~ 2;
7.4 数值运算
7.4.1 取整函数:round
语法:round(double a);
返回值:Bigint
说明:返回double类型的整数值部分(遵循四舍五入)
select round(3.14159);

7.4.2 指定精度取整函数:round
语法:rount(double a, int b)
返回值:Bigint
说明:返回精度为d的double类型
select round(3.14159, 5);

7.4.3 向下取整函数:floor
语法:floor(double a)
返回值:Bigint
说明:返回等于或者小于该double变量的最大整数
select floor(3.5);

7.4.4 向上取整函数:ceil
语法:ceil(double a)
返回值:Bigint
说明:返回等于或者大于该double变量的最小整数
select ceil(3.5);

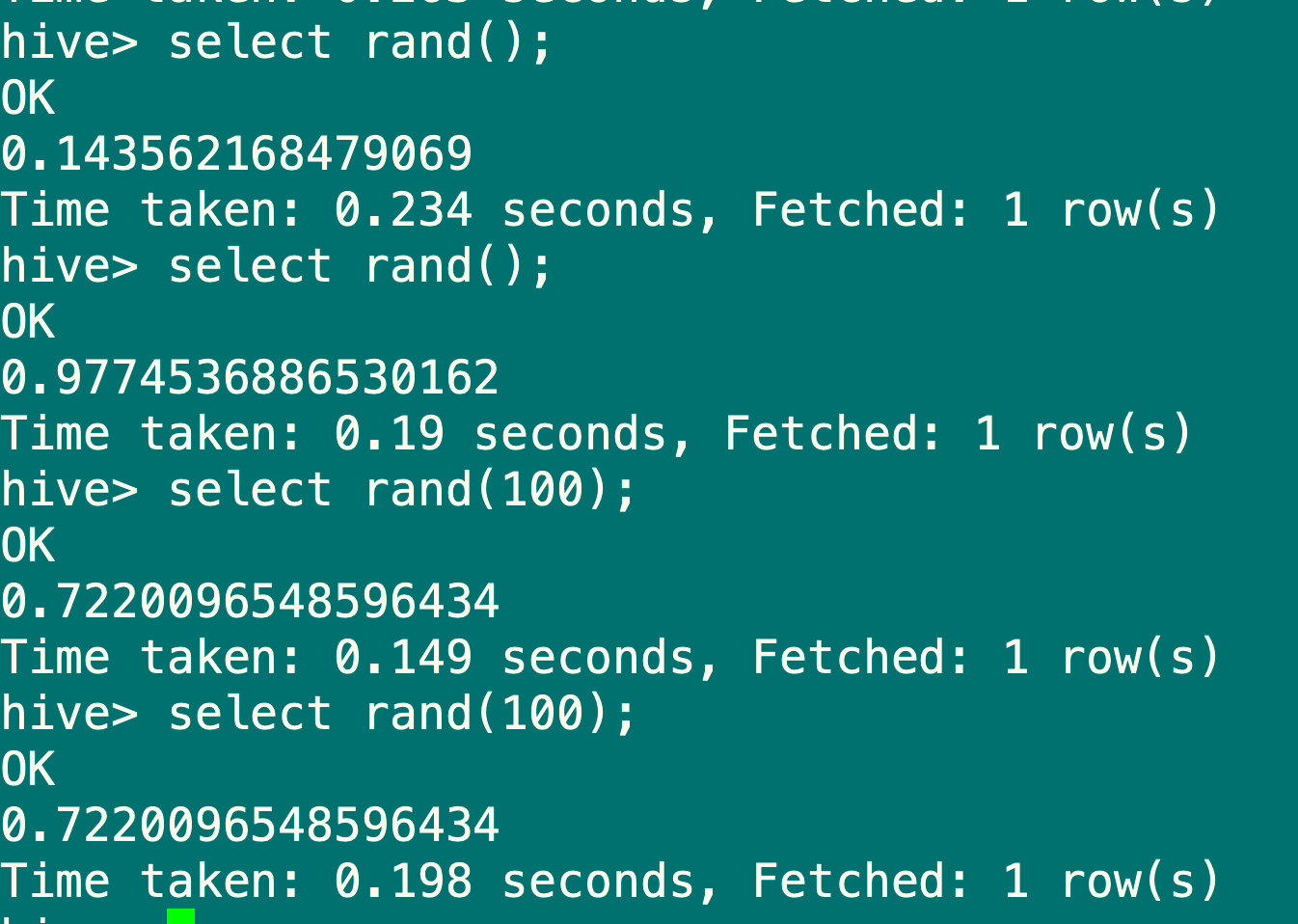
7.4.5 随机取整函数:rand
语法:rand(), rand(int seed)
返回值:double
说明:返回一个0到1范围内的随机数,如果指定种子seed,则会得到一个稳定的随机数序列
#每次执行结果都不同
select rand();
#只要指定种子每次执行的结果都是一样的
select rand(100);
7.5 条件函数
7.5.1 if函数
语法:if(boolean testCondition, T valueTrue, T valueFalseOrNull)
返回值:T
说明:当条件testCondition为true时,返回valueTrue,否则返回valueFalseOrNull
select if(1=2,1100,200);
select if(1=1,100,200);

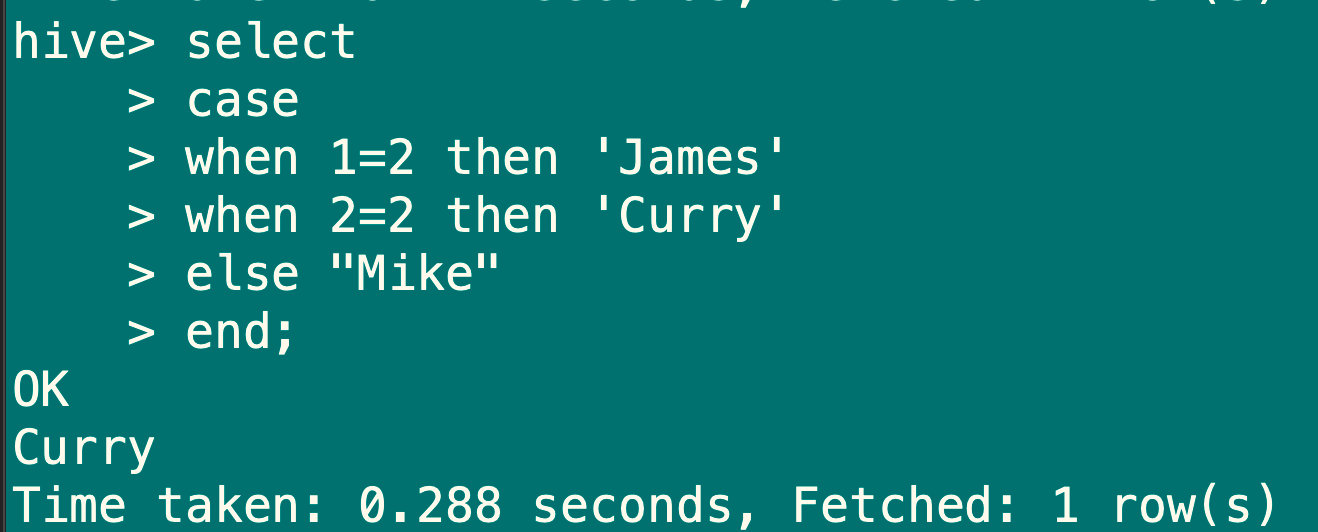
7.5.2 条件判断函数:case、when
语法:case when a then b [when c then d]* [else e ] end
返回值:T
说明:如果a为true,则返回b,如果c为true,则返回d,否则返回e
select
case
when 1=2 then 'James'
when 2=2 then 'Curry'
else "Mike"
end;
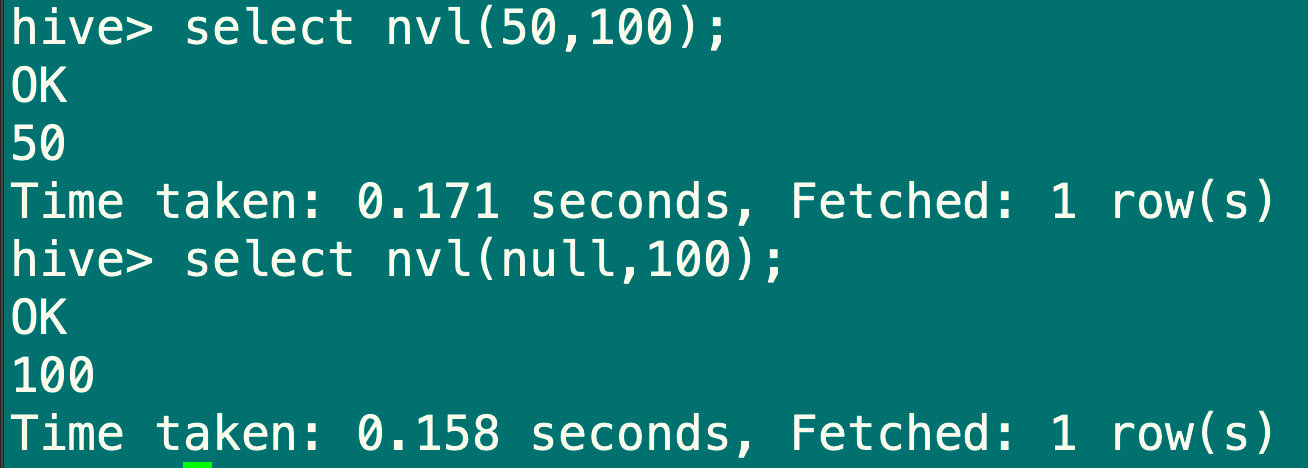
7.5.3 空值转换函数:NVL
1.如果expr1为null,返回值为expr2,则返回expr1
2.适用于数字型,字符型和日期型,但是expr1和expr2的数据类型必须为同类型
select nvl(null,100);
select nvl(50,100;)
7.6 日期函数
7.6.1 获取当前unix时间戳函数:unix_timestamp
语法:unix_timestamp()
返回值:bigint
说明:获得当前时区的unix时间戳
select unix_timestamp();


7.6.2 unix时间戳转换日期函数:from_unixtime
语法:from_unixtime(bigint unixtime,[string format])
返回值:string
说明:转化unix时间戳(从1970-01-01 00:00:00utc时间到指定时间的秒数)到当前时区的时间格式
select from_unixtime(1658159097,'yyyyMMdd');

7.6.3 指定格式日期转unix时间戳函数:unix_timestamp
语法:unix_timestamp(string date, string pattern)
返回值:bigint
说明:转换pattern格式的日期到unix时间戳,如果转化失败则返回null
select unix_timestamp('2022-07-18 23:52:05','yyyy-MM-dd HH:mm:ss');

7.6.4 日期时间转日期函数:to_date
语法:to_date(string timestamp)
返回值:string
说明:返回日期时间字段中的日期部分
select to_date('2022-07-18 23:52:05');

7.6.5 日期转年函数:year
语法:year(string date)
返回值:int
说明:返回日期中的年
select year('2022-07-18 23:52:05');

7.6.6 日期转月函数:month
语法:month(string date)
返回值:int
说明:返回日期中的月份
select month('2022-07-18 23:52:05');

7.6.7 日期转天函数:day
语法:day(string date)
返回值:int
说明:返回日期中的天
select day('2022-07-18 23:52:05');

7.6.8 日期转小时函数:hour
语法:hour(string date)
返回值:int
说明:返回日期中的小时
select hour('2022-07-18 23:52:05');

7.6.9 日期转周函数:weekofyear
语法:weekofyear(string date)
返回值:int
说明:返回当前日期所在周数
select weekofyear('2022-07-18 23:52:05');

7.6.10 日期比较函数:datediff
语法:datediff(string enddate, string strartdate)
返回值:int
说明:返回结束日期减去开始日期的天数
select datediff('2022-07-18','2022-01-23');

7.6.11 日期增加函数:date_add
语法:date_add(string date, int days)
返回值:string
说明:返回开始日期startdate增加days天后的日期
select date_add('2022-07-18',10);

7.6.12 日期减少函数:date_sub
语法:date_sub(string startdate, int days)
返回值:string
说明:返回开始日期startdate减少days 后的日志
select date_sub('2022-07-18',12);

7.7 字符串函数
7.7.1 字符串长度函数:length
语法:length(string a)
返回值:int
说明:返回字符串a的长度
select length('asdadadssd');

7.7.2 字符串连接函数:concat
语法:concat(string a, string b)
返回值:string
说明:返回输入字符串连接后的结果,支持任意个字符串
select concat('asdasd','qwewqe');

7.7.3 带分隔符字符串连接函数:concat_ws
语法:concat_ws(string sep,string a, string b)
返回值:string
说明:返回输入字符串连接后的结果,sep表示各个字符串之间的分隔符
select concat_ws(',','abc','sad','das');

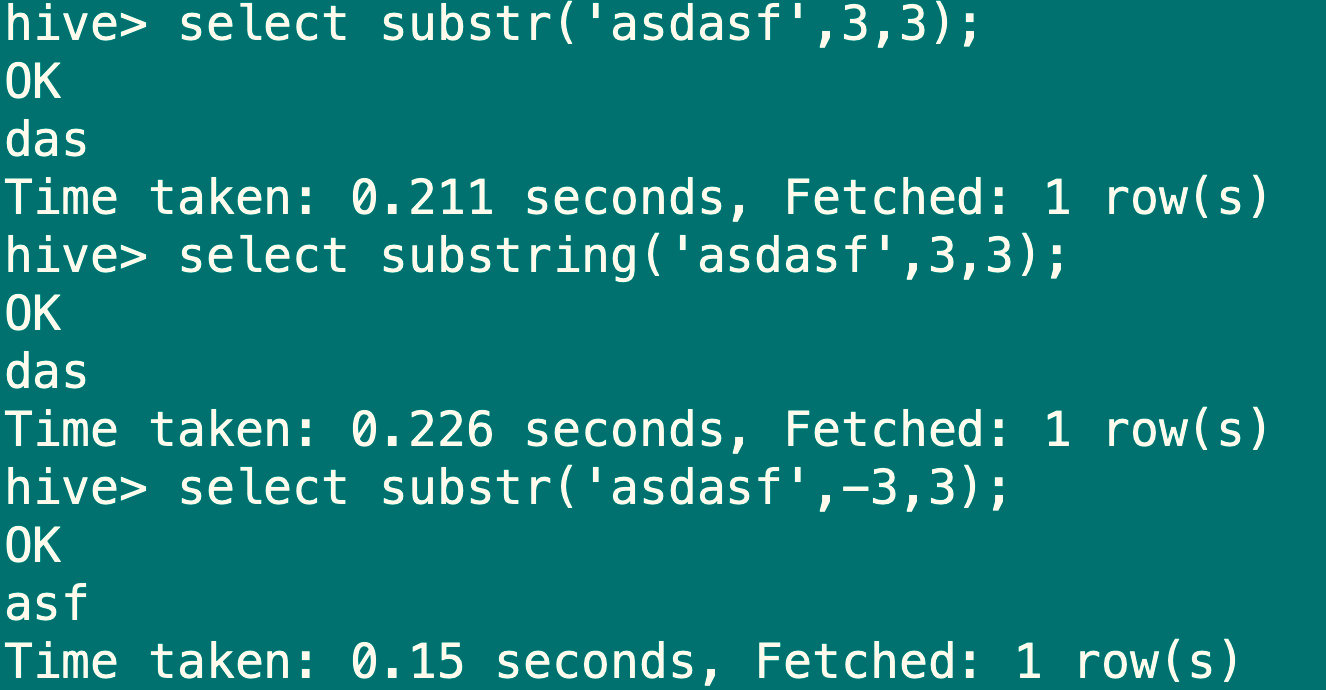
7.7.4 字符串截取函数:substr,substring
语法:substr(string a, int start , int len),substring(string a, int start, int len)
返回值:string
说明:返回字符串a从start位置开始,长度为len的字符串
select substr('asdasf',3,3);
select substring('asdasf',3,3);
select substr('asdasf',-3,3);
7.7.5 字符串转大写函数:upper,ucase
语法:upper(string a), ucase(string a)
返回值:string
说明:返回字符串a的大写格式
select upper('asdasda');

7.7.6 字符串转小写函数:lower,lcase
语法:lower(string a),lcase(string a)
返回值:string
说明:返回字符串a的小写格式
select upper('SDASD');

7.7.7 去空格函数:trim
语法:trim(string a)
返回值:string
说明:去除字符串a两边的空格
select trim(' sad ');

7.7.8 右边与空格函数:rtrim
语法:rtrim(string a)
返回值:string
说明:去除字符串a右边的空格
select rtrim(' sad ');

7.7.9 左边与空格函数:ltrim
语法:ltrim(string a)
返回值:string
说明:去除字符串a左边的空格
select ltrim(' sad ');

7.7.10 正则表达式替换函数:regexp_replace
语法:regexp_replace(string a, string b, string c)
返回值:string
说明:将字符串a中符合java正则表达式b的部分替换为c。注意有些情况下要使用转义字符,类似oracle的regexp_replace函数
select regexp_replace('soccer','oc|er','');
















 4719
4719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









