







基于词频生成词云图
背景目的
有一篇中文文章,或者一本小说。想要根据词频来生成词云图。


为什么中文需要分词
中文分词是理解和处理中文文本的关键步骤,它直接影响到后续的文本分析和信息提取的准确性和有效性。
-
无明显单词分隔:中文文本不像英文那样使用空格来分隔单词,中文字符通常连续书写,没有明显的单词边界。
-
语言单位:中文的基本语言单位是字,但单独的字往往不能表达完整的意思。中文的表达往往需要由多个字组成的词语来实现。
-
语境依赖性:中文词语的意义很大程度上依赖于语境,相同的字在不同的词语中可能有不同的意义。
-
词义丰富性:中文中的词语往往比单个的字具有更丰富的语义信息,分词有助于更准确地理解文本内容。
-
语法复杂性:中文的语法结构相对复杂,词语的顺序、搭配和使用习惯对句子意义的影响很大。
-
自然语言处理:在自然语言处理领域,分词是中文文本分析的基础步骤,无论是进行词性标注、命名实体识别还是句法分析,都需要先进行分词。
-
信息检索和文本挖掘:分词可以提高中文信息检索和文本挖掘的准确性,有助于提取关键词和短语,从而更好地理解文本内容。
文本预处理
最终目的是,生成句子数组。
在进行中文文本分析前,必须执行数据预处理步骤,以提升后续处理的准确性和效率。这包括:
- 移除文本中的特殊符号,因为它们通常不携带有用信息,且可能干扰分词算法。
- 统一替换空格、换行符、制表符等空白字符为中文逗号,以保持句子的连贯性。
- 删除无意义的英文字母,因为它们对于中文文本分析不是必要的。
- 清除文本中的网址、图片链接、日期等信息,这些通常与文本的主题无关,可能会影响分析结果。
数据处理函数
处理文本,过滤不需要无意义的字符。
import re
def data_process(str_data):
# 定义正则表达式模式
# 去除换行、空格
str_data = re.sub(r'[\n\s]+', '', str_data)
# 匹配网址
url_pattern = r'http[s]?://(?:[a-zA-Z]|[0-9]|[$-_@.&+]|[!*\\(\\),]|(?:%[0-9a-fA-F][0-9a-fA-F]))+'
# 匹配日期格式如 YYYY/MM/DD, YYYY-MM-DD, YYYY年MM月DD日
date_pattern = r'\d{4}[/\\-]?\d{1,2}[/\\-]?\d{1,2}'
# 匹配邮箱地址
email_pattern = r'\b[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Z|a-z]{2,}\b'
# 匹配数字
number_pattern = r'\d+'
# 匹配英文字母
english_letter_pattern = r'[a-zA-Z]'
# 替换空白字符为空格
str_data = re.sub(r'\s', ',', str_data)
# 删除特殊符号、网址、日期、邮箱、数字和英文字母
str_data = re.sub(url_pattern, '', str_data)
str_data = re.sub(date_pattern, '', str_data)
str_data = re.sub(email_pattern, '', str_data)
str_data = re.sub(number_pattern, '', str_data)
str_data = re.sub(english_letter_pattern, '', str_data)
# 删除标点符号
punctuation = r""""!!??#$%&'()()*+-/:;▪³/<=>@[\]^_`●{|}~⦅⦆「」、、〃》「」『』【】[]〔〕〖〗〘〙{}〚〛*°▽〜〝〞〟〰〾〿–—‘'‛“”„‟…‧﹏"""
str_data = re.sub(f"[{re.escape(punctuation)}]+", '', str_data)
return str_data.strip()
sample_text = "这是一个例子。\n包含网址 http://example.com,参考文献[1]{,日期2024-06-18。"
processed_text = data_process(sample_text)
print(processed_text)
句子数组函数封装
读取txt文件生成句子数组
def getText(filename):
sentences = []
with open(filename, 'r', encoding='utf-8') as fp:
for line in fp:
processed_line = data_process(line)
if processed_line: # 检查处理后的句子是否为空或只包含空白字符
sentences.extend(re.split(r'[。!?]', processed_line)) # 使用更复杂的句子划分规则
# 去除列表中的空字符串
sentences = [sentence for sentence in sentences if sentence.strip()]
return sentences
输出结果

分词和词频统计
jieba分词
Jieba分词是一个流行的中文分词Python库,它的主要特点和作用可以简单概括为:
什么是Jieba分词:一个用于中文文本分词的库。
做了什么:识别中文文本中的单词边界,将连续的文本切分成单独的词语。
得到什么:提供分词后的结果,即文本中各个词语的列表。

Jieba 分词器属于概率语言模型分词,基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况构建成有向无环图,然后采用动态规划寻找最大概率路径,找出基于词频的最大切分组合。对于不存在与前缀词典中的词,采用了汉字成词能力的 HMM 模型,使用了 Viterbi 算法。Jieba 的切分模式有全模式、精确模式、搜索引擎模式,更多详细信息可以查看 github 仓库。
以下是 Jieba 分词器中一些常用函数的:
| 函数名 | 描述 |
|---|---|
| jieba.cut | 对输入文本进行分词,返回一个可迭代的分词结果 |
| jieba.cut_for_search | 在搜索引擎模式下对输入文本进行分词,返回一个可迭代的分词结果 |
| jieba.lcut | 对输入文本进行分词,返回一个列表形式的分词结果 |
| jieba.lcut_for_search | 在搜索引擎模式下对输入文本进行分词,返回一个列表形式的分词结果 |
| jieba.add_word | 向分词词典中添加新词 |
| jieba.del_word | 从分词词典中删除指定词 |
| jieba.load_userdict | 加载用户自定义词典 |
| jieba.analyse.extract_tags | 提取文本中的关键词,返回一个列表形式的关键词结果 |
词频函数封装
统计句子列表中名词(‘n’, ‘nr’, ‘nz’)的词频, 返回一个字典
import jieba.posseg as psg
def getWordFrequency(sentences):
"""
统计句子列表中名词('n', 'nr', 'nz')的词频
:param sentences: 包含多个句子的列表
:return: 包含名词词频的字典
"""
words_dict = {} # 用于存储词频的字典
for text in sentences:
# 去掉标点符号
text = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "", text)
# 使用结巴分词进行词性标注
wordGen = psg.cut(text)
# 遍历分词结果,统计名词词频
for word, attr in wordGen:
if attr in ['n', 'nr', 'nz']: # 判断词性是否为名词
if word in words_dict.keys():
words_dict[word] += 1
else:
words_dict[word] = 1
return words_dict
if __name__ == "__main__":
sentences = getText("../百度百科-黄河.txt")
# pprint(sentences)
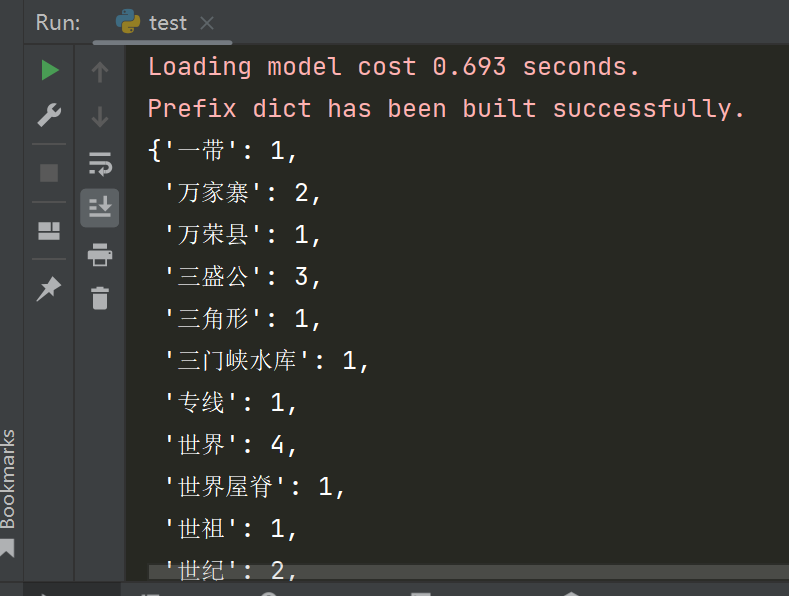
words_dict = getWordFrequency(sentences)
pprint(words_dict)
输出结果
由词频生成词云
完整代码
词云结果


















 7944
7944











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











