







 2021年zhengfu工作报告通过数据可视化生成词云图,揭示高频词:发展、建设、经济、企业、创新。本文介绍使用Python进行词频统计和词云图绘制的过程,涉及jieba、wordcloud等库的使用。
2021年zhengfu工作报告通过数据可视化生成词云图,揭示高频词:发展、建设、经济、企业、创新。本文介绍使用Python进行词频统计和词云图绘制的过程,涉及jieba、wordcloud等库的使用。
2021年工作报告词频词云分析
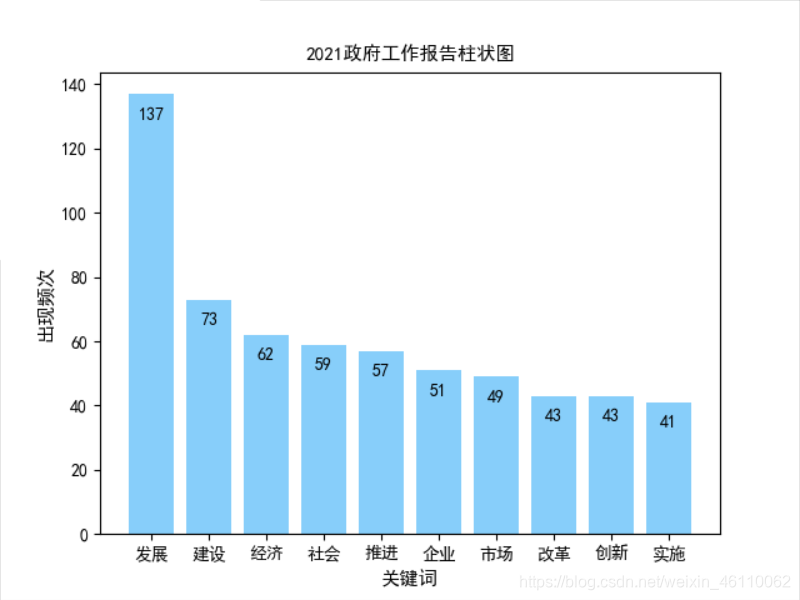
对2021年zhengfu工作报告通过数据可视化生成关键词词云图,统计高频词语发现,今年出现频率最高的前五大词为:发展(137次)、建设(72次)、经济(62次)、企业(52次)、创新(43次)。以下将详细介绍一下该数据可视化实现的完整过程。

1、过程分析
程序主要分为三个步骤,第一个步骤是对报告文本进行数据处理,做一个词语切割和词频统计的工作。第二个步骤是对词频统计的结果,进行词云图可视化处理,绘制出我们需要的词云图。第三个步骤选取前面的一些关键词进行柱状图或饼图折线图等展示分析,获取自己想要的信息。
2、准备工作
1)先准备Windows的Python编程环境,下载安装配置好Python;
2)安装Pycharm ,具体的Pycharm和Anaconda安装教程可以参考以下链接;
https://shimo.im/docs/osGMxDe6E24hx6JT/read
3)安装jieba库,这个jieba库是一个非常强大的中文分词工具,强大到可以把每一个词都单独切开;
4)安装wordcloud库,这个是绘制词云图的第三方库;安装PIL库,用于处理词云图的背景图片;
5)安装matplotlib库,这个是绘制统计图的第三方库;
6)安装nump和collections库,这个是统计收集数据的第三方库;
7)准备需要分析的txt文本(网上复制工作报告全文保存为txt文本文件),还有停用词文本(chineseStopWords.txt),自己在网上下载即可。
3、代码实现
直接在Pycharm里面进行演示。
1)首先依次import导入我们需要的第三方库,分别是jieba、wordcloud、matplotlib、PIL、nump和collections。
注意如果有plt报错将matplotlib卸载安装3.0版本即可。

2)设置好柱状图XY轴可以显示中文字体,再设置坐标轴的字体格式。
此处注意字体SimHei其实就是黑体,如果系统一直报错,那么需要将字体SimHei下载下来,然后复制到venv\Lib\site-packages\matplotlib\mpl-data\fonts\ttf文件夹里面,再修改一些参数,具体可以百度查找相关的教程。
3)接下来是报告文本导入,使用jieba进行分词和词频词数统计。
首先打开我们两个txt文件,并返回一个列表:(这里需要注意的是文件编码有可能是utf-8,也有可能是gbk,我这里试了一下是gbk,另外需要注意文件路径的输入格式(符号、空格等),为避免报错最好手动输入)。
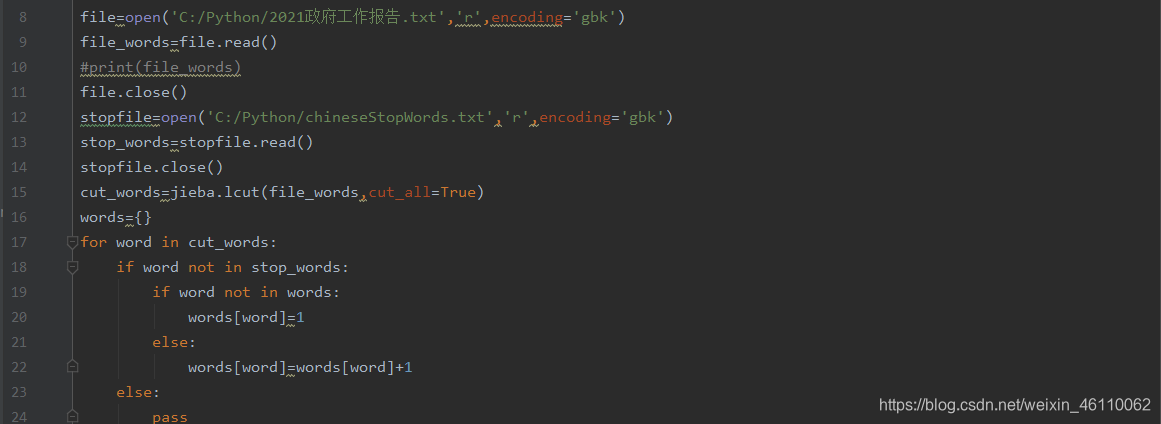
4)紧接着,我们构造一个空字典words,它接收的对象是字典类型,这样词云图才会根据键值显示对应词的大小,接着用jieba切文本,返回一个列表,然后把出现在停用词里面的词去掉,对清洗之后的词用遍历循环进行词频统计。
到了这里,我们就已经得到了我们需要的字典words了,这里面已经储存了每个词,而对应的键值就是其频数,我们测试一下“发展”这个词,在报告中出现了多少次:结果是137次。
或者用print()打印关键词的统计结果,看看是否能正常实现。结果正常,如图:

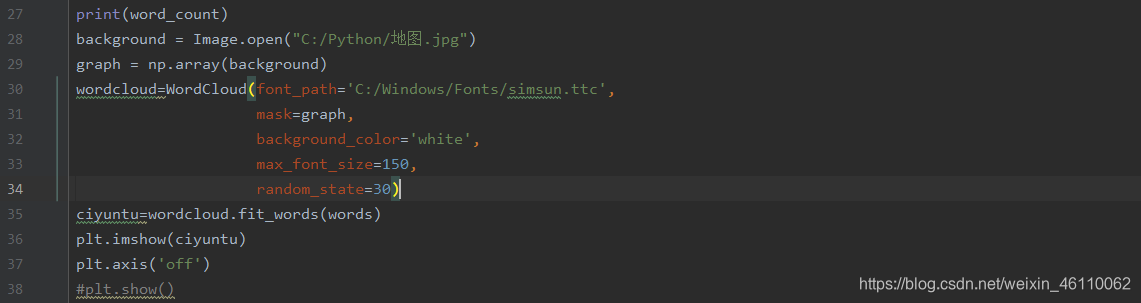
5)我们就可以直接用wordcloud绘制我们需要的词云图了。
先下载好要使用的背景图片,图片需改为白色背景,图片越高清处理速度越快,词云图效果越好。可以网上下载不同的图片生成各种图形。如果不设置图片那么默认的是长方形的图形。
6)最后在使用plt相关函数绘制柱状图。先设置柱状图的XY轴参数,显示数据数量,颜色,显示数值等
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 595
595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









