







(2024)豆瓣电影TOP250爬虫详细讲解和代码
这是一个关于如何用Python爬取2024年豆瓣电影Top250的详细教程。教程涵盖了生成分页URL列表和解析页面以获取电影信息的函数。
getAllPageUrl()生成前10页的链接,而getMoiveListByUrl()使用PyQuery解析HTML,提取电影标题、封面、评价数和评分。代码示例展示了测试这些函数的方法,输出包括电影详情的字典列表。
爬虫目的
获取 https://movie.douban.com/top250 电影列表的所有电影的属性。并存储起来。说起来很简单就两步。
- 第一步爬取数据
- 第二步存储
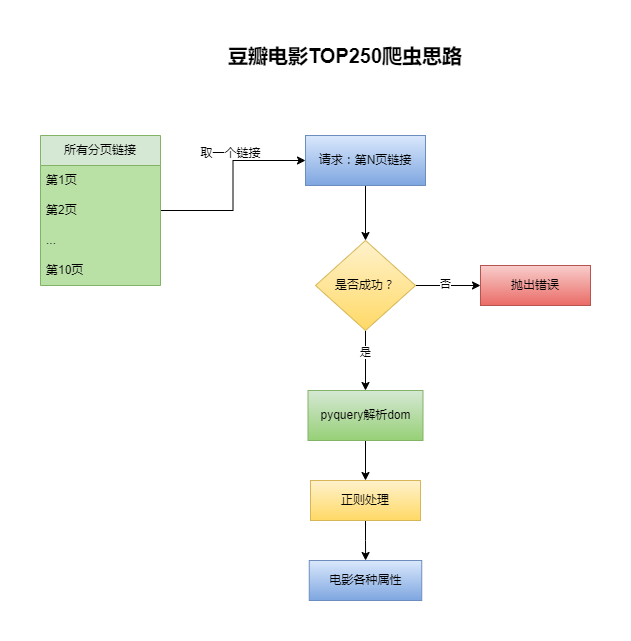
爬虫思路
总体流程图
由于是分页的,要先观察分页的规律,如下很容易知道每一页的规律。
- 第一页:https://movie.douban.com/top250?start=0&filter=
- 第二页:https://movie.douban.com/top250?start=25&filter=
代码思路
- 函数
getAllPageUrl:生成分页链接列表 - 函数
getMoiveListByUrl:根据某一页的分页链接,输出电影属性
函数:getAllPageUrl
def getAllPageUrl():
"""
通过观察规律,生成所有分页的链接list
:return:
"""
list = []
for i in range(10):
url = f'https://movie.douban.com/top250?start={
i*25}&filter='
list 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 2928
2928

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











