






docker-compose以及docker安装参考我的一下两篇博文
docker-compose搭建prometheus+grafana
k8s单master集群在线安装
开始搭建之前同样我们先来看一下prometheus的官方生态架构图

我们说到监控就肯定会提到报警,没有报警的监控就像是没有可乐的炸鸡,他是不完善的。那么alertmanager报警究竟是怎么实现呢,它又是怎么和prometheus一起协调,并且完成报警的发送呢?
上一篇中我们知道prometheus可以抓取exporter中暴露出来的指标数据并且存储,prometheus有自己的查询语句PromQL,grafana面板中的显示的都是PromQL查询prometheus时序数据库出来的数据。prometheus和alertmanager的通信其实就是依靠prometheus的PromQL,我们在prometheus中可以定义一些PromQL语句,当语句查询出来的值不符合我们预期我们就可以把该项当做一个报警发送给alertmanager了,alertmanager只负责把prometheus发送过去的相关的报警指标分类并且报警(微信,邮件,企微)
prometheus配置alertmanager通信(用于prometheus向alertmanager发送报警信息)
在prometheus的配置文件中我们看到会有以下默认配置项,非别定义了报警组件alertmanager的地址以及prometheus定义的需要发送报警的一些规则文件(就是上面说到的一些PromQL语句的集合)
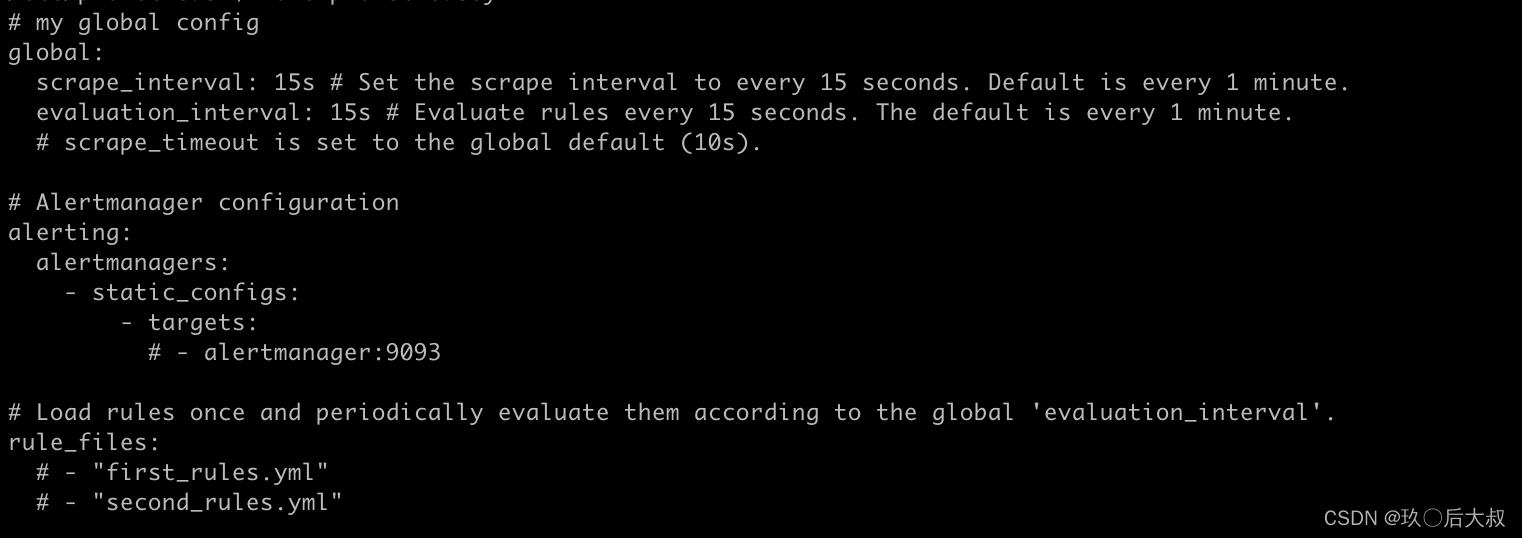
我们编写一个rules.yaml文件内容如下,
vi rules.yaml
groups:
- name: example
rules:
- alert: DataNodeDown
expr: up == 0
for: 3s
labels:
severity: page
annotations:
summary: "node {{ $labels.host }} down"
description: "{{ $labels.host }} of job {{ $labels.job }} has been down "
groups:对文件中的报警查询指标进行分组
name:组名
rules: 详细规则,以下定义多个
alert:报警组名
expr: 报警触发的PromQL查询语句
for:报警持续多长时间向alertmanager发送报警
labels:向给alertmanager发送的报警指标中添加的标签
annotations:告诉alertmanager中需要发送的信息
说明: up 指标是prometheus添加一个exporter后默认生成的一个检测该exporter健康状态的监控指标,如果一个exporter可以被抓取,那么该指标的值就会是1,利用这个up指标我们就可以在部署了node-exporter的机器,通过up指标数值来模拟机器是否宕机了,我们在prometheus控制台查询如下:
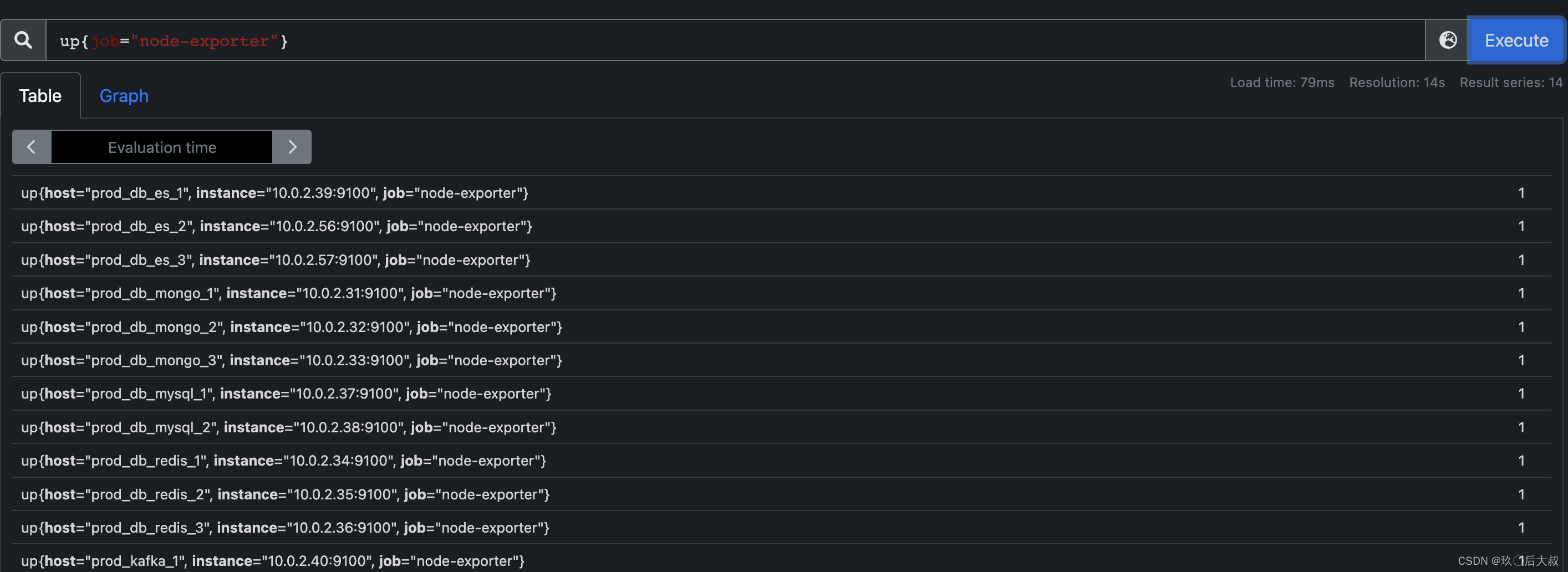
那么上面的rules.yaml就很好理解了,当存在up指标为0的时候prometheus就会把expr中的语句查询出来所有up为0的指标并携带所有查询出来的标签发送给alertmanager,这里注意是所有查询出来的标签而不是该指标的所有标签,比如expr中的语句为
avg(up{job=“node-exporter”})by (instance) == 0
此语句在prometheus中查询结果为:
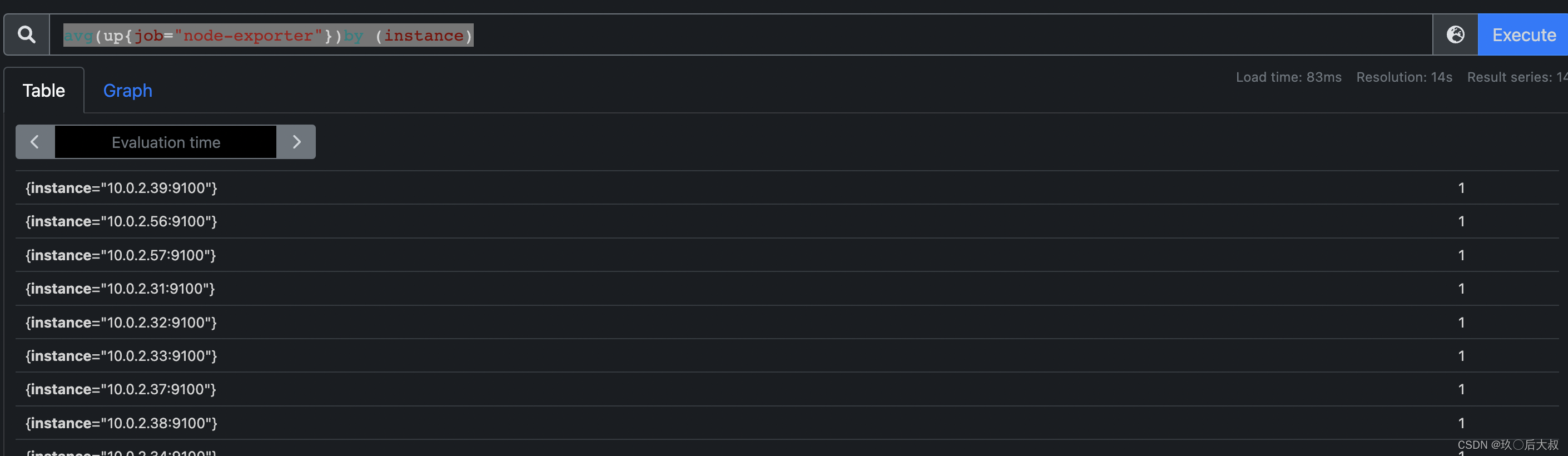
如果是以此查询语句实现报警那么发送给alertmanager的up的报警指标中就不会再带有job和host指标了,那么alertmanager就无法在annotations中利用$labels获取相关指标值了,当然这里为例举才这样做,一般我们up指标的报警不会这样做。
alertmanager介绍
先来看一下alertmanager的配置文件结构
global:
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: 'xxxxxx@qq.com'
smtp_auth_username: 'xxxxxxxxx@qq.com'
smtp_auth_password: 'xxxxxxxxx'
smtp_require_tls: false
route:
group_by: [alertname]
group_wait: 5s
group_interval: 5m
repeat_interval: 5s
receiver: default-receiver
receivers:
- name: 'default-receiver'
email_configs:
- to: 'xxxx@163.com'
global: 定义邮件发送人信息,此处我们选择qq邮箱,注意smtp_auth_password不是邮箱登录密码而是qq邮箱授权第三方登录的授权码
group_by: 默认为alertname,报警指标的分组,我们看到prometheus的rules.yaml中有一项alert配置,当报警触发后,prometheus会在当前报警指标中添加一个alertname:DataNodeDown(rules.yaml中配置的值)的标签,那么如果有多个up指标值为0的时候,alertmanager收到的多个报警指标的alertname:DataNodeDown标签值是一样的,那么此处的分组就会把相同的alertname:DataNodeDown指标报警作为一条邮件发送,这样可以减少同类报警邮件的多次发送
group_wait:有的时候为了能够一次性收集和发送更多的报警时,可以通过group_wait参数设置等待时间,如果在等待时间内当前group接收到了新的告警,这些告警将会合并为一个通知向receiver发送。
group_interval:用于定义相同的Gourp之间发送告警通知的时间间隔。如果一个指标持续报警,可以理解为每隔5分钟发送一次邮件
repeat_interval:如果警报已经成功发送通知, 如果想设置发送告警通知之前要等待时间,则可以通过repeat_interval参数进行设置,此项可以理解为在发送邮件前的等待时间,有时候我们可以在线看到有一些指标报警了,在此项配置的时间内我们解决了报警,就不会发送邮件
receivers:定义邮件接收人
此处的邮件接收人可以配合group_by使用,上面的配置会所有报警根据alertname分组发送给同一个收件人,有时候我们需要根据职能的分工将报警分类发送,请看如下配置
route:
receiver: 'default-receiver'
group_wait: 30s
group_interval: 5m
repeat_interval: 4h
group_by: [alertname]
routes:
- receiver: 'dba'
group_wait: 10s
match_re:
service: mysql|redis
- receiver: 'app'
group_by: [management, enviroment]
match:
team: app
match_re:当报警指标中的标签值包含其中就发送给相关接收人
group_by:根据相关标签的分组,发送给相关接收人
我们在receivers在定义好相关接收人信息后即可
默认情况下所有的告警都会发送给管理员default-receiver,因此在Alertmanager的配置文件的根路由中,对告警信息按照告警的名称对告警进行分组。
如果告警时来源于数据库服务如MySQL或者redis,此时则需要将告警发送给相应的数据库管理员(dba)。这里定义了一个单独子路由,如果告警中包含service标签,并且service为MySQL或者redis,则向dba发送告警通知,由于这里没有定义group_by等属性,这些属性的配置信息将从上级路由继承,dba将会接收到按alertname进行分组的告警通知。
而某些告警规则来源可能来源于开发团队的定义,这些告警中通过添加标签team来标示这些告警的创建者。在Alertmanager配置文件的告警路由下,定义单独子路由用于处理这一类的告警通知,如果匹配到告警中包含标签team,并且team的值为app,Alertmanager将会按照标签management和environment对告警进行分组。此时如果应用出现异常,开发团队就能清楚的知道哪一个环境(environment)中的哪一个应用程序出现了问题,可以快速对应用进行问题定位。
在了解了prometheus和alertmanager的相关机制后,下面我们来一步一步搭建报警实现发送
搭建报警实现邮件发送
继上一篇中prometheus配置文件我们添加如下alertmanager地址配置以及rules.yaml文件地址配置(注意此处为容器中地址,需要在宿主机挂载进容器)
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.0.2:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "/etc/prometheus/rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'node-exporter'
static_configs:
- targets: ['192.168.0.1:9100']
labels:
host: myhost01
编辑rules.yml文件:
vi /opt/prometneus/rules.yml
groups:
- name: example
rules:
- alert: DataNodeDown
expr: up{job=~".*exporter"} == 0
for: 3s
labels:
severity: page
annotations:
summary: "node {{ $labels.host }} down"
description: "{{ $labels.host }} of job {{ $labels.job }} has been down "
编辑prometheus docker-compose启动yaml文件prometheus.yaml如下:
prometheus:
image: docker.touty.io/library/prometheus:latest
restart: always
container_name: prometheus
hostname: prometheus
environment:
- TZ=Asia/Shanghai
ports:
- 9090:9090
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
- '--storage.tsdb.retention.time=7d'
- '--web.external-url=prometheus'
- "--web.enable-lifecycle"
volumes:
- /opt/prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- /opt/prometheus/rules.yml:/etc/prometheus/rules.yml
- /opt/promdata:/prometheus
启动prometheus
docker-compose -f prometheus.yaml up -d
编辑alertmanager配置文件/opt/alertmanager/alertmanager.yml,如下
global:
smtp_smarthost: 'smtp.qq.com:465'
smtp_from: 'xxx@qq.com'
smtp_auth_username: 'xxx@qq.com'
smtp_auth_password: 'xxx'
smtp_require_tls: false
route:
group_by: [alertname]
group_wait: 5s
group_interval: 5m
repeat_interval: 5s
receiver: default-receiver
receivers:
- name: 'default-receiver'
email_configs:
- to: 'xxx@163.com'
编辑alertmanager docker-compose启动yaml文件alertmanager.yaml
alertmanager:
image: prom/alertmanager:v0.23.0
restart: always
container_name: alertmanager
hostname: alertmanager
environment:
- TZ=Asia/Shanghai
ports:
- 9093:9093
command:
- "--config.file=/etc/alertmanager/alertmanager.yml"
- "--log.level=debug"
volumes:
- /opt/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
- /data/alertmanager:/alertmanager
启动alertmanager
docker-compose -f alertmanager.yaml up -d
我们访问192.168.0.2就可以看到alertmanager的页面了
致此我们prometheus和alertmanager就搭建完成了。下面我们模拟报警,我们把192.168.0.1的node-exporter停掉模拟机器宕机,
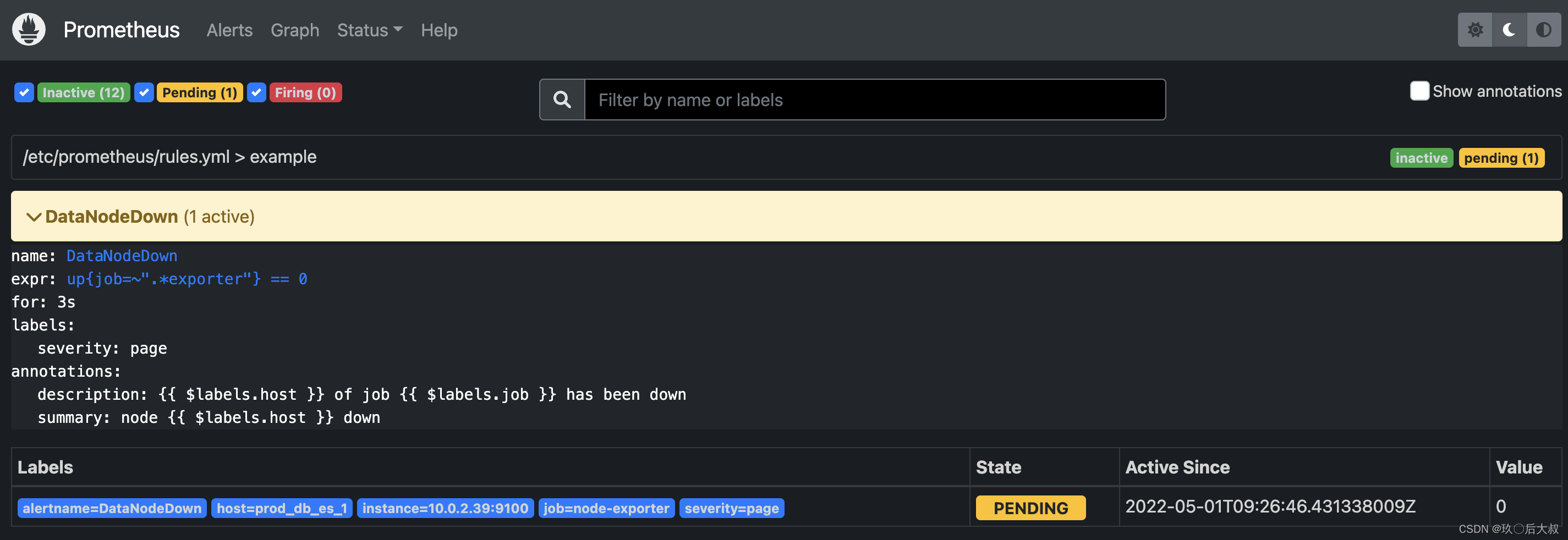
可以看到prometheus Alerts下面收到了收到一条警告,说明prometheus抓到了此报警,state 为PENDING说明报警指标还未给alertmanager发送
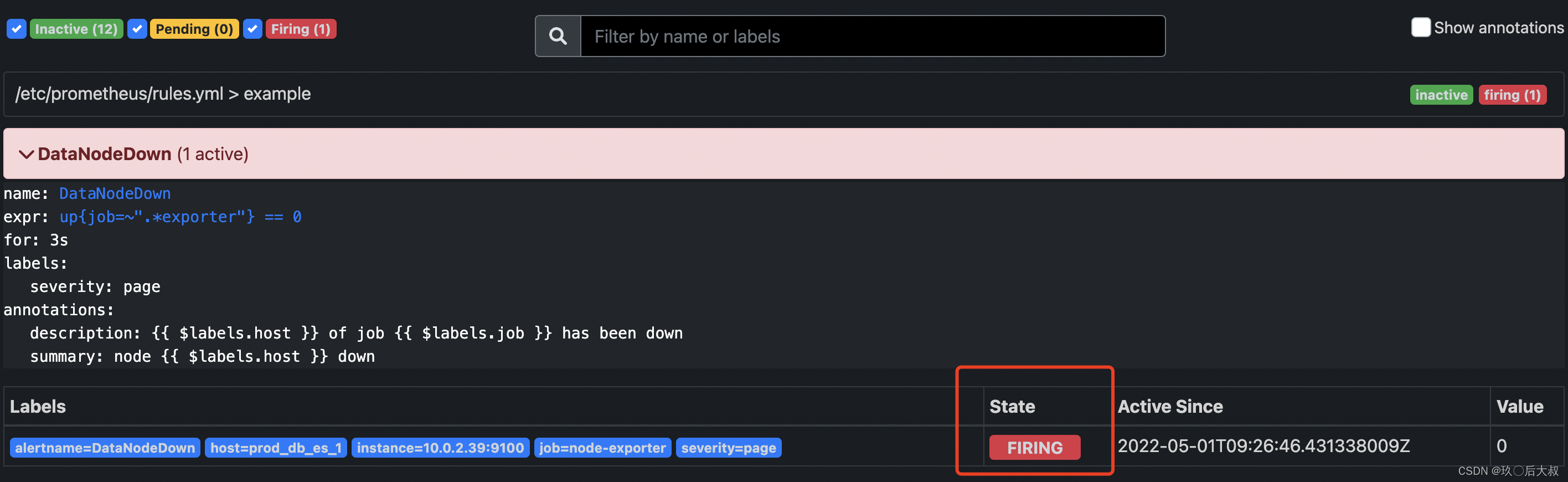
state 为FIRING说明prmetheus已经把该报警指标发送给alertmanager,
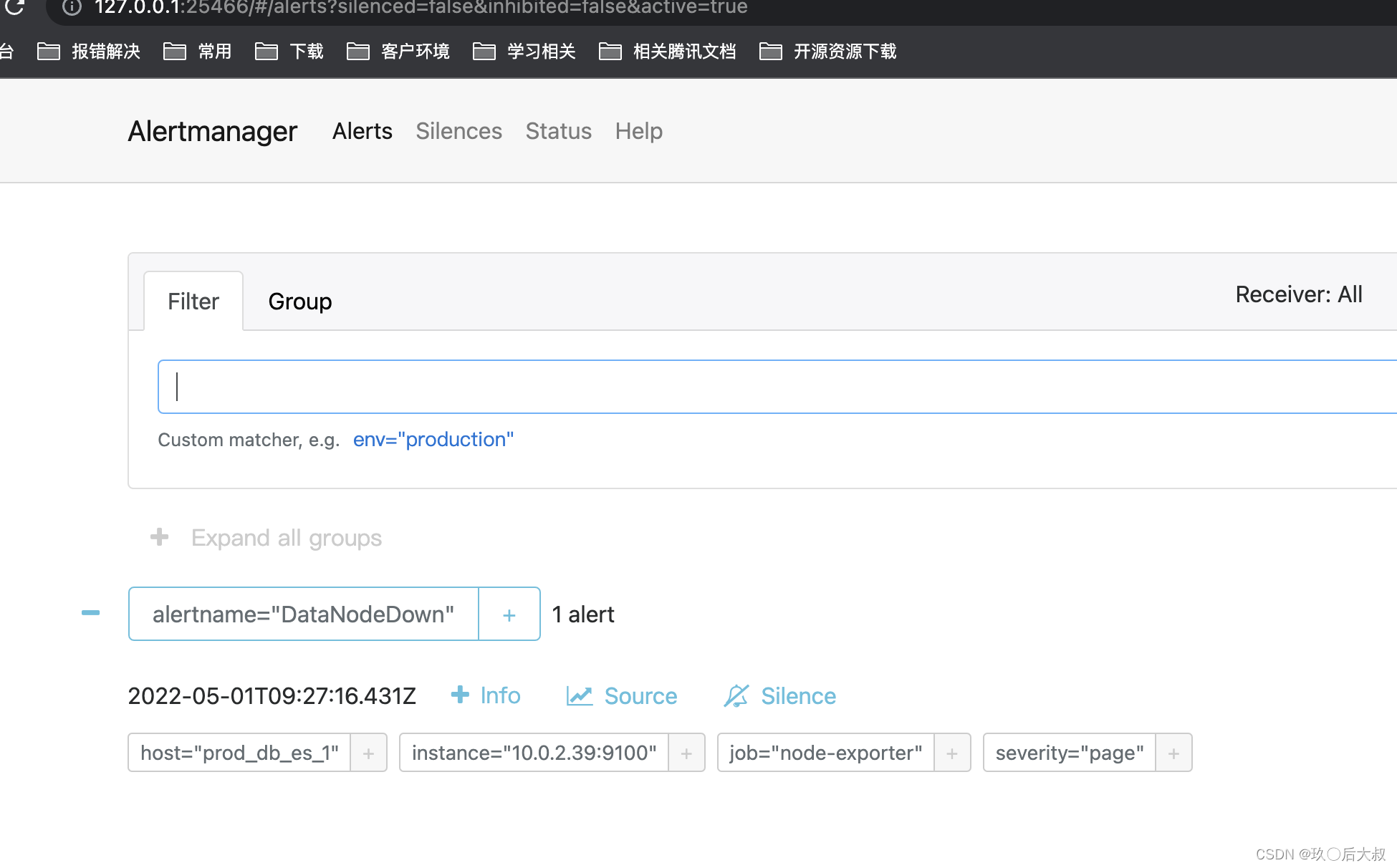
查看alertmanager可以看到收到的报警指标
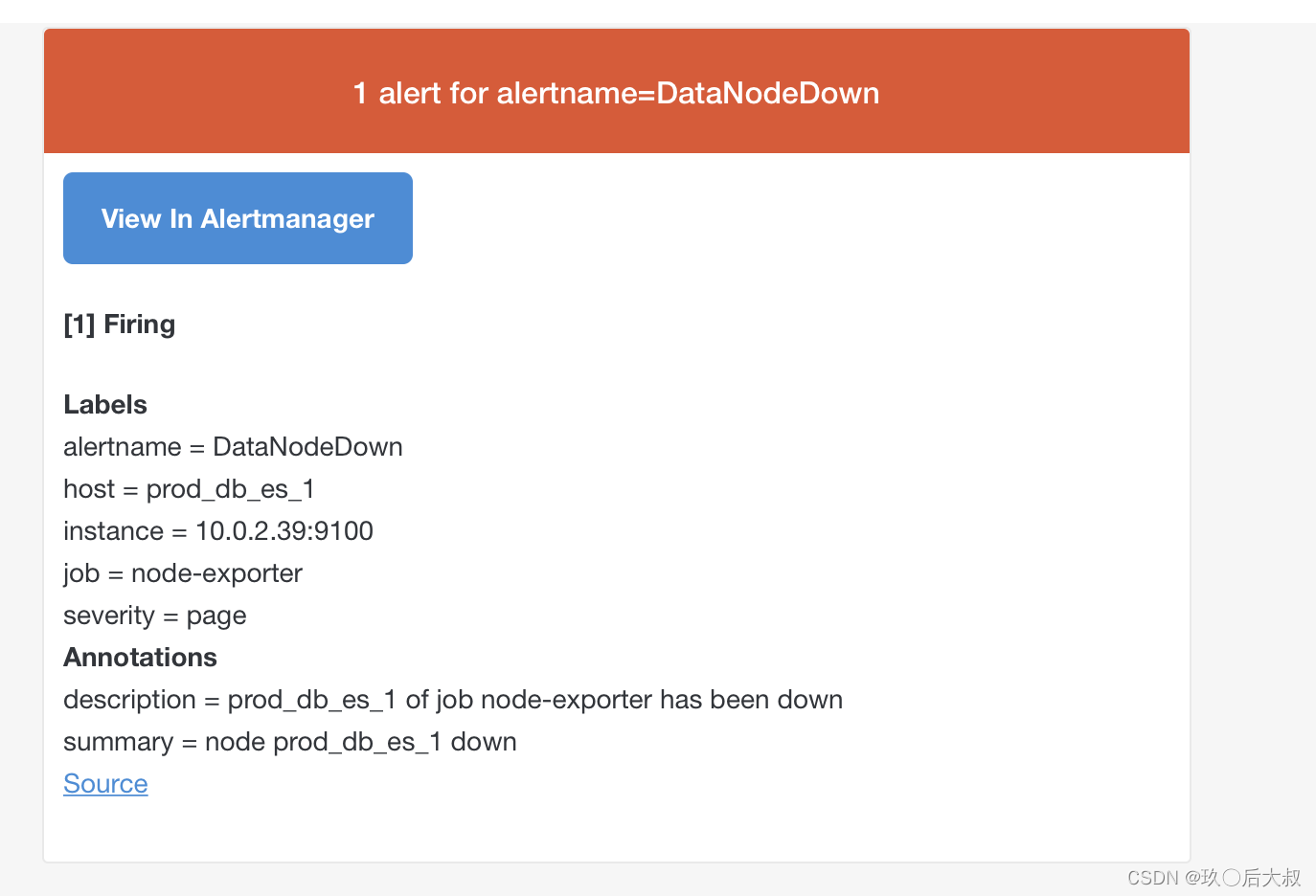
查看邮件我们可以看到如下alertmanager发来的邮件
至此,基于docker-compose搭建的prometheus+grafana+alertmanager实现的监控报警通知就完成了,其中有一些细节还需要搭建过程中自己摸索实现,非常有意思
如果你觉得能够帮助到你,点个赞吧,你的举手之劳是我强大动力,下篇介绍在k8s中搭建prometheus+grafana+alertmanager实现监控报警














 1283
1283











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









