







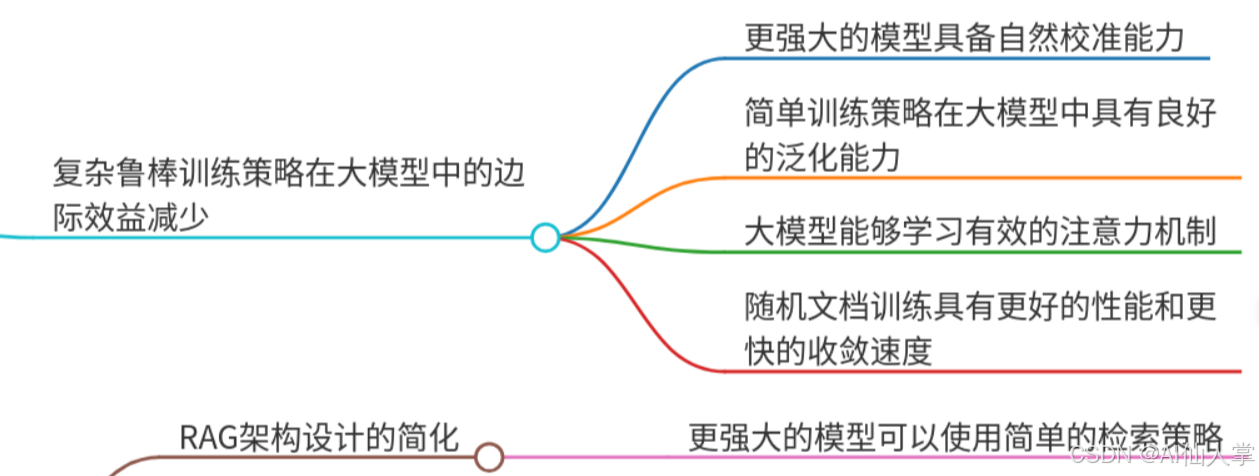
论文系统地探讨了在模型能力增强时,复杂鲁棒训练策略的必要性。实验结果表明,对于较弱的模型,复杂的文档选择策略和对抗性损失函数显著提高了模型的鲁棒性和泛化能力。然而,随着模型能力的提升,这些策略的效果显著下降。强大的模型在使用简单训练策略时表现出更好的自然校准、跨数据集泛化和注意力机制。这些发现表明,随着模型能力的提升,RAG系统可以从更简单的训练策略中受益,从而实现更可扩展的应用。
研究背景
- 研究问题:这篇文章探讨了在大语言模型(LLMs)能力不断提升的背景下,复杂的鲁棒训练策略是否仍然必要。具体来说,研究了在模型能力增强时,复杂鲁棒训练方法的效果是否会显著下降。
- 研究难点:该问题的研究难点包括:如何系统地评估不同训练策略在不同模型和数据集上的效果,以及理解强大模型在自然校准、跨数据集泛化和注意力机制方面的内在优势。
- 相关工作:该问题的研究相关工作包括RetRobust、RAAT和IRM等鲁棒训练方法,这些方法旨在通过选择高质量文档或引入对抗性正则化项来提高RAG系统对噪声上下文的鲁棒性。
研究方法
这篇论文提出了通过系统的实验和分析来探讨复杂鲁棒训练策略在强大模型中的必要性。具体来说,
- 文档选择策略:研究了四种文档选择策略,包括RALM、RetRobust、Top-1 Document和Golden Document。RALM策略通过预处理金色检索文本来微调模型;RetRobust策略通过随机选择排名靠前、靠后或随机的文档进行训练;Top-1 Document策略使用得分最高的检索文档;Golden Document策略选择包含正确答案的最相关文档。
- 对抗性损失设计:评估了两种流行的对抗性损失策略,包括RAAT和IRM。RAAT通过惩罚最佳和最差检索情况之间的性能差异来减少模型对检索噪声的敏感性;IRM通过最小化不同检索环境下的性能方差来确保模型在不同场景下的可靠性。
- 实验设置:在四个广泛使用的问答数据集(Single-hop QA: NaturalQuestions和WebQuestions;Multi-hop QA: TriviaQA和HotpotQA)上进行实验,使用Exact Match(EM)和F1指标进行评估。实验采用了标准的两阶段RAG框架,检索器使用BERT基的密集检索器Contriever,知识库为预处理后的Wikipedia-2018。
实验设计
- 数据集和评估指标:实验在四个问答数据集上进行评估,包括NaturalQuestions、WebQuestions、TriviaQA和HotpotQA。所有实验结果在其开发集上使用EM和F1指标进行评估。
- RAG流程:实现了标准的两阶段RAG框架,检索阶段使用Contriever进行检索,生成阶段将检索到的文档与查询拼接作为输入进行答案生成。训练和开发过程中,每个查询检索前20个相关文档,生成阶段使用前5个检索文档。
- 鲁棒RAG训练设置:评估了两种文档选择策略和两种对抗性损失策略。文档选择策略包括RALM、RetRobust、Top-1 Document和Golden Document;对抗性损失策略包括RAAT和IRM。
结果与分析
- 复杂文档选择策略的有效性:实验结果表明,对于较弱的模型,复杂的文档选择策略显著提高了模型的鲁棒性。例如,Llama-2-7b-chat-hf模型在HotpotQA数据集上,使用Golden Document策略的EM得分从3.3提高到30.67。然而,随着模型能力的提升,这些策略的效果显著下降。
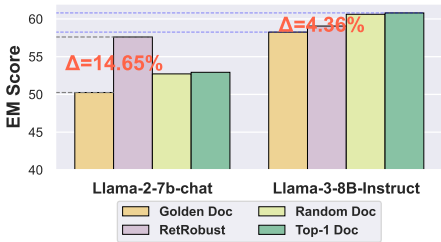
- 对抗性损失函数的影响:对于较弱的模型,对抗性损失函数显著提高了模型的性能。例如,Llama-2-7b-chat-hf模型在使用RAAT策略时,HotpotQA数据集上的EM得分从2.21提高到40.64。然而,对于较强的模型,对抗性损失函数的效果不明显,甚至可能阻碍性能提升。
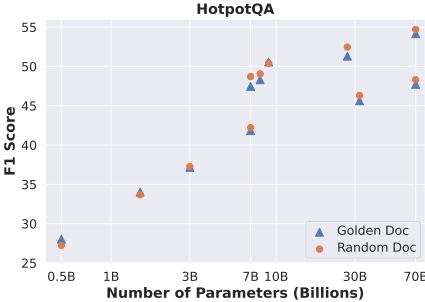
- 简单训练策略的泛化能力:实验结果显示,强大的模型在使用简单训练策略时表现出显著的跨数据集泛化能力。例如,Qwen-3-8B-Instruct模型在使用随机文档选择策略时,TriviaQA数据集上的F1得分为68.64,接近使用RetRobust策略的69.5 F1得分。
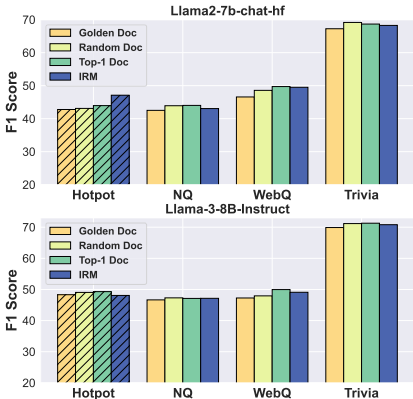
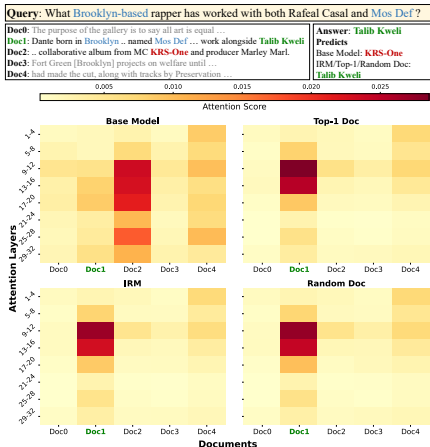
- 注意力机制的优化:实验表明,强大的模型在使用简单训练策略时也能学习到有效的注意力机制。注意力分布热图显示,无论是复杂策略还是简单策略,模型都能集中在正确答案对应的文档上。
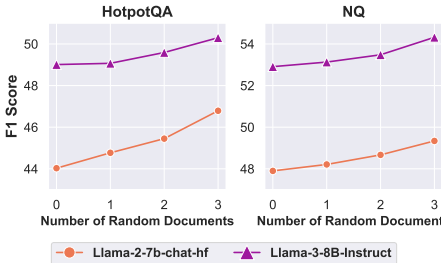
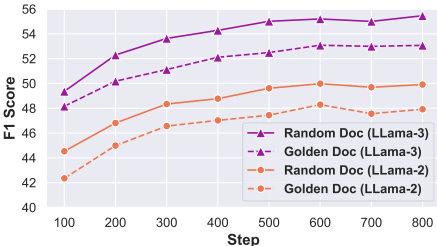
- 随机文档训练的优越性:实验结果显示,随机文档训练不仅在性能上表现优异,还能加速收敛。例如,Llama-2-7b-chat-hf模型在使用3个随机文档时,HotpotQA数据集上的F1得分提高了3分。
优点与创新
- 发现:论文揭示了随着模型能力的提升,复杂训练策略的好处显著减少。
- 理由:通过系统分析,论文将这一发现追溯到强大模型的内在能力,证明了它们自然具备强大的信心校准、泛化能力和有效的注意力机制,无论训练复杂性如何。
- 见解:论文为未来的RAG发展提供了实用的指导,主张在强大模型中使用简化的架构设计原则,强调了在最小监督下进行可扩展开放领域应用的机会,并提出了关于模型扩展规律的理论视角。
- 实验:通过跨多个语言模型和不同能力水平的广泛实验,论文验证了复杂训练策略在不同模型中的有效性。
- 自校准分析:论文通过自校准分析发现,更强大的模型自然展现出优越的正确与错误答案区分能力。
- 泛化能力:论文发现这些模型在基本随机文档训练下表现出显著的跨数据集泛化能力。
- 注意力机制可视化:论文通过可视化注意力分布直接展示了简单训练策略也能实现良好的性能。
- 随机文档训练的优越性:论文研究了随机文档训练为何表现良好,发现更多随机文档可以带来更好的性能和更快的收敛速度。
不足与反思
- 模型限制:论文的分析仅限于密集的基于Transformer的模型,未探索稀疏模型(如MoE架构)的有效性。未来工作可以研究类似趋势是否适用于具有动态路由机制的稀疏激活模型。
- 对抗训练的长期稳定性:尽管论文分析了对抗训练的有效性,但未明确检查其长期稳定性或收敛特性,这些可能因超参数选择和优化动态而异。
- 机制不明确:尽管论文展示了更强大的模型从对抗损失和文档选择策略中获得的收益递减,但背后的确切机制仍不清楚。需要进一步研究以理解模型能力与检索鲁棒性之间的相互作用。
- 偏见和误导输出的风险:虽然对抗训练增强了模型的可靠性,但它并未消除偏见或误导输出的风险,特别是在检索源包含固有偏见或错误信息的情况下。未来工作应探索公平感知的对抗训练以减轻潜在的伤害。
- 资源分配:论文发现更强大的模型需要较少的文档选择和损失设计干预,这可能影响现实世界应用中的资源分配。研究人员和从业者应确保模型改进不会不成比例地惠及资源丰富的机构,同时使较小模型较不稳健。
- 领域多样性:论文的实验是在广泛使用的基准数据集上进行的,可能无法完全反映现实世界信息需求的多样性。鼓励进一步研究在不同领域(包括低资源语言和专业知识领域)的鲁棒性评估,以确保RAG技术的公平进步。
关键问题及回答
问题1:在实验中,哪些文档选择策略在不同模型能力下表现最佳?
实验结果表明,不同的文档选择策略在不同模型能力下表现各异。对于较弱的模型(如Llama-2-7b-chat-hf),使用高质量的文档选择策略(如Golden Document)显著提高了模型的鲁棒性。然而,随着模型能力的提升(如Llama-3-8B-Instruct和Qwen-3-8B-Instruct),这些策略的效果显著下降。相反,使用随机文档选择策略在这些较强模型中表现优异,甚至在某些情况下接近或超过了复杂的策略(如RetRobust)。
问题2:对抗性损失函数在模型鲁棒性提升中的作用是什么?它们在不同模型能力下的效果如何?
对抗性损失函数(如RAAT和IRM)在较弱模型中显著提高了模型的鲁棒性。例如,Llama-2-7b-chat-hf模型在使用RAAT策略时,HotpotQA数据集上的EM得分从2.21提高到40.64。然而,对于较强的模型(如Llama-3-8B-Instruct和Qwen-3-8B-Instruct),对抗性损失函数的效果不明显,甚至可能阻碍性能提升。这表明对抗性损失函数在模型能力较弱时有效,但在模型能力较强时效果有限。
问题3:为什么强大的模型在使用简单训练策略时表现出更好的自然校准和跨数据集泛化能力?
强大的模型在使用简单训练策略时表现出更好的自然校准和跨数据集泛化能力,主要原因在于这些模型本身具有更强的内在鲁棒性和学习能力。具体来说:
- 自然校准:强大的模型在自然校准方面表现更好,能够更准确地预测其回答的正确性。例如,Llama-3-8B-Instruct模型在使用随机文档选择策略时,HotpotQA数据集上的正确回答置信度显著高于错误回答。
- 跨数据集泛化:强大的模型能够更好地利用简单训练策略在不同数据集上进行泛化。例如,Qwen-3-8B-Instruct模型在使用随机文档选择策略时,TriviaQA数据集上的F1得分接近使用RetRobust策略的性能。
- 注意力机制:强大的模型在使用简单训练策略时也能学习到有效的注意力机制,能够集中在正确答案对应的文档上,从而提高推理和生成的准确性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











