







论文提出了LevelRAG方法,通过分离检索逻辑和检索器特定的重写,实现了更高的检索灵活性和准确性。具体为:用户查询最初由高级搜索器处理。分解的原子查询由低级搜索器处理,这些搜索器可能会改写和精炼查询,然后将其发送到相应的检索器。检索到的文档由高级搜索器聚合和总结,然后输入到生成器以生成响应。高级搜索器和低级搜索器都利用检索到的文档反馈来完善或补充它们的输出。
实验结果表明,LevelRAG在单跳和多跳问答任务中均优于现有的RAG方法,特别是在复杂的多跳推理任务中表现出色。高层次搜索器和稀疏搜索器的有效性得到了进一步分析。总体而言,LevelRAG为检索增强生成领域的提供了一个值得一试的方法路径。
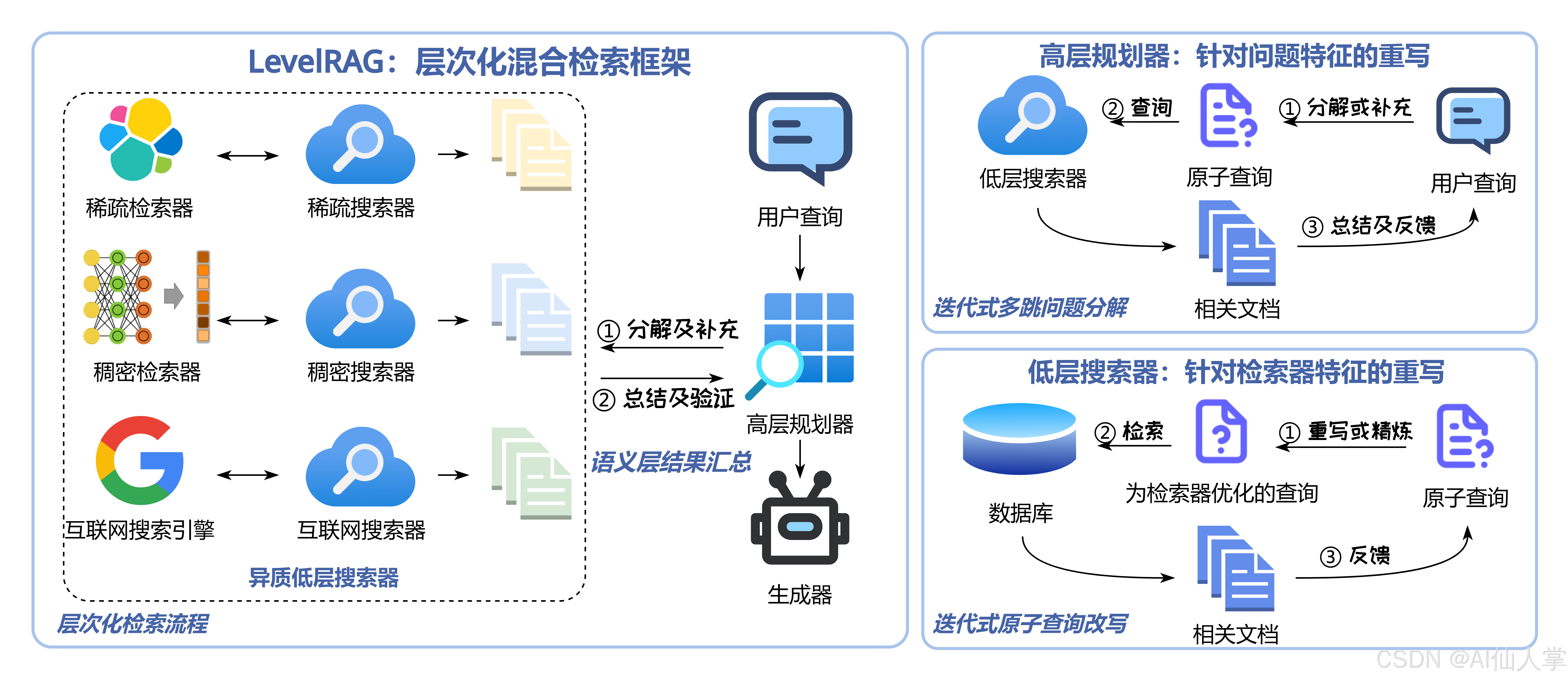
LevelRAG 是一种两阶段的检索增强生成(RAG)框架,结合了多跳逻辑规划和混合检索,以提高检索过程的完整性和准确性。
其中第一阶段采用一个高级搜索器,将用户查询分解为原子查询。
第二阶段利用多个低级搜索器,为每个子查询检索最相关的文档,然后将相关信息汇总到高级搜索器中生成最终答案。在每个低级搜索器中,采用大型语言模型(LLMs)对原子查询进行适应性优化,以更好地适应低级搜索器中内置的检索器。
https://github.com/ictnlp/LevelRAG
项目基于FlexRAG开发,FlexRAG是由中国科学院计算技术研究所自然语言处理团队开发的高性能多模态检索增强生成(RAG)框架
研究方法
这篇论文提出了LevelRAG方法,用于解决混合检索场景下的查询重写问题。具体来说,
-
高层次搜索器:高层次搜索器负责将复杂查询分解为原子查询,并进行多跳逻辑规划和信息组合。它执行四个关键操作:分解、总结、验证和补充。

- 分解:将用户查询分解为更简单、更具体的原子查询。
- 总结:在检索到相关文档后,将其压缩成简短的摘要。
- 验证:检查摘要信息是否足以回答原始用户查询。
- 补充:根据摘要信息的完整性,识别并添加额外的原子查询以完全回答用户查询。
-
低层次搜索器:低层次搜索器包括稀疏搜索器、密集搜索器和网络搜索器,分别用于精确的关键词检索、复杂查询的语义检索和利用互联网知识的广泛检索。
- 稀疏搜索器:利用Lucene语法增强检索精度,通过迭代重写查询来提高检索效果。
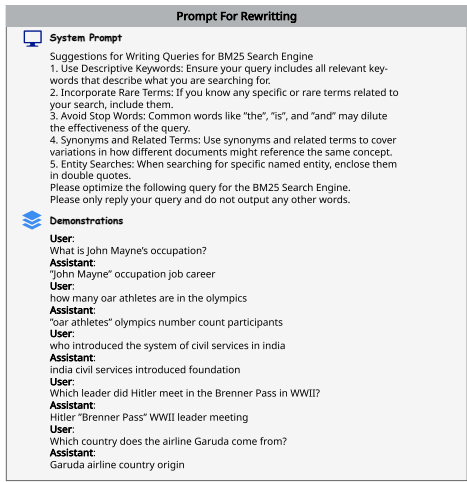
- 密集搜索器:通过构建伪文档来丰富查询的语义内容。
- 网络搜索器:直接将原子查询输入搜索引擎,并返回摘要作为上下文。

- 稀疏搜索器:利用Lucene语法增强检索精度,通过迭代重写查询来提高检索效果。
实验设计
- 数据集:实验在五个广泛使用的知识密集型问答任务上进行,包括三个单跳问答任务(PopQA、Natural Questions、TriviaQA)和两个多跳问答任务(HotpotQA、2WikimultihopQA)。
- 评估指标:使用检索成功率、响应准确率和响应F1分数来评估检索过程和响应质量。对于Natural Questions数据集,使用精确匹配(EM)代替响应准确率。
- 基线方法:评估了包括无检索生成和有检索生成在内的多种基线方法,如有检索生成的方法ITRG、IR-COT、SelfRAG、RQ-RAG、ReSP以及专门的RAG模型ChatQA和RankRAG。
- 实现细节:使用Qwen2 7B作为基础模型,部署在NVIDIA GPU上,设置温度为零以确保结果的可重复性。稀疏检索器使用Elasticsearch构建索引,密集检索器使用contriever和SCaNN进行编码和索引,网络搜索器使用Azure的Bing Web Search API。
结果与分析
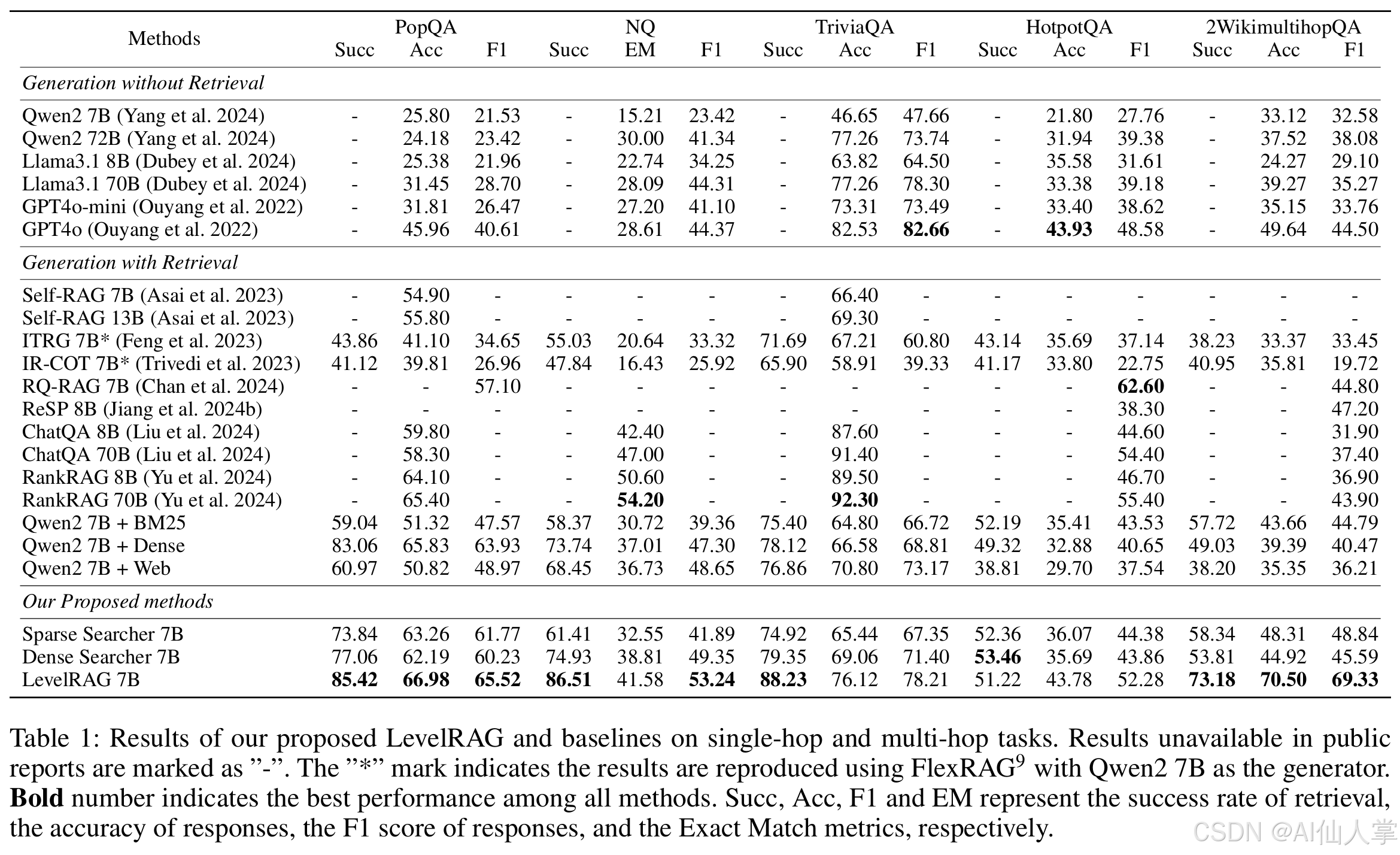
- 主要结果:LevelRAG在单跳和多跳任务中均表现出色,特别是在使用F1分数评估时,LevelRAG在PopQA和2WikimultihopQA数据集上分别超越了现有方法1.58和22.13。
- 非检索模型:与无检索生成模型相比,LevelRAG在大多数数据集上表现出显著的性能优势,特别是在参数规模较大的情况下。
- 检索方法比较:与现有的检索方法相比,LevelRAG在PopQA、NQ和2WikimultihopQA数据集上的F1分数均优于其他方法。与最强的专用模型RankRAG 70B相比,LevelRAG在使用参数仅为其十分之一的情况下表现出相当的性能。
- 消融研究:高层次搜索器的分解和补充操作显著提高了检索成功率,而总结操作虽然导致了一些信息损失,但有效减少了噪声,提高了响应质量。稀疏搜索器的重写和反馈操作均有助于提高检索成功率和响应质量。
论文评价
优点与创新
- 高层次搜索器与低层次搜索器的结合:提出了LevelRAG方法,通过将检索逻辑与特定于检索器的重写解耦,实现了更高的灵活性。高层次搜索器负责多跳逻辑规划和信息组合,而低层次搜索器(稀疏、网络和密集)则优化查询以适应相应的检索器。
- 新的稀疏搜索器:开发了一种新的稀疏搜索器,利用Lucene语法提高检索准确性,特别适用于精确的关键词检索。
- 多跳逻辑规划:通过高层次搜索器进行多跳逻辑规划,确保检索结果的完整性和准确性,克服了当前混合检索场景中查询重写技术的局限性。
- 实验验证:在五个数据集上进行了广泛的实验,包括单跳和多跳问答任务,证明了LevelRAG在性能上优于现有的RAG方法,甚至超过了最先进的专有模型GPT4o。
- 组件有效性分析:进一步分析了高层次搜索器和稀疏搜索器中关键操作的有效性,展示了每个组件的贡献。
不足与反思
- 缺乏自适应机制:尽管LevelRAG在处理复杂的多跳推理任务时表现出色,但缺乏确定何时需要检索的自适应机制。这导致了在某些情况下检索效果不佳。
- 对基础模型选择的敏感性:实验表明,基础模型的选择对LevelRAG的性能有显著影响。使用Qwen2 7B作为基础模型时,方法未能在所有数据集上超越所有非检索模型。
- 信息丢失问题:高层次搜索器中的摘要操作虽然减少了噪声,但也可能导致一些信息的丢失,从而影响最终响应的质量。
关键问题及回答
问题1:LevelRAG方法中的高层次搜索器是如何工作的?它有哪些关键操作?
高层次搜索器在LevelRAG方法中扮演着关键角色,主要负责将复杂查询分解为原子查询,并进行多跳逻辑规划和信息组合。具体来说,高层次搜索器执行以下四个关键操作:
- 分解(Decompose):将用户查询分解为更简单、更具体的原子查询。这些原子查询更容易单独处理。
- 总结(Summarize):在检索到相关文档后,高层次搜索器将其压缩成简短的摘要。这一步骤通过直接回答原子查询来实现。
- 验证(Verify):高层次搜索器检查摘要信息是否足以回答原始用户查询。如果信息不足,则会触发进一步的补充操作。
- 补充(Supplement):根据摘要信息的完整性,高层次搜索器识别并添加额外的原子查询以完全回答用户查询。
这些操作共同确保了检索过程的完整性和准确性,从而提高了整体检索效果。
问题2:LevelRAG方法中的低层次搜索器有哪些类型?它们各自的作用是什么?
LevelRAG方法中的低层次搜索器包括三种类型,每种类型都有其独特的作用:
- 稀疏搜索器(Sparse Searcher):该搜索器利用Lucene语法增强检索精度,适用于精确的关键词检索。它通过迭代重写查询来提高检索效果,特别擅长识别基于显式实体的内容。
- 密集搜索器(Dense Searcher):该搜索器更擅长捕捉查询中的语义信息,适用于复杂查询的语义检索。它通过构建伪文档来丰富查询的语义内容,从而提高检索的相关性。
- 网络搜索器(Web Searcher):该搜索器利用互联网上的广泛知识,适用于利用互联网信息的广泛检索。它将原子查询直接输入搜索引擎,并返回摘要作为上下文,从而补充本地数据库的知识。
这三种低层次搜索器与高层次搜索器协同工作,确保检索过程的完整性和准确性。
问题3:LevelRAG方法在实验中表现如何?与其他方法相比有哪些优势?
LevelRAG方法在实验中表现出色,特别是在单跳和多跳问答任务中均优于现有的RAG方法。具体优势包括:
- 综合性能优越:LevelRAG在多个数据集上的F1分数均优于其他方法,特别是在使用F1分数评估时,LevelRAG在PopQA和2WikimultihopQA数据集上分别超越了现有方法1.58和22.13。
- 参数效率:与最强的专用模型RankRAG 70B相比,LevelRAG在使用参数仅为其十分之一的情况下表现出相当的性能,显示出其在参数使用上的高效性。
- 检索成功率提高:LevelRAG的检索成功率显著高于传统的朴素BM25搜索,特别是在单跳问答任务中,稀疏搜索器和密集搜索器分别提高了14.8和1.19个百分点。
- 高层次搜索器的有效性:高层次搜索器的分解和补充操作显著提高了检索成功率,而总结操作虽然导致了一些信息损失,但有效减少了噪声,提高了响应质量。
- 稀疏搜索器的贡献:稀疏搜索器的重写和反馈操作均有助于提高检索成功率和响应质量,进一步展示了其在精确关键词检索中的优势。
代码解读
搜索器模块(searchers/)
BaseSearcher:搜索器的基类,定义了搜索器的基本接口和初始化方法。
DenseSearcher:密集搜索器,使用密集检索技术进行文档检索。支持查询重写功能,通过大语言模型对查询进行重写以提高检索效果。
KeywordSearcher:关键字搜索器,基于关键字进行文档检索。
WebSearcher:网络搜索器,用于从网络上检索相关文档,需要提前准备 Bing 搜索 API_KEY。
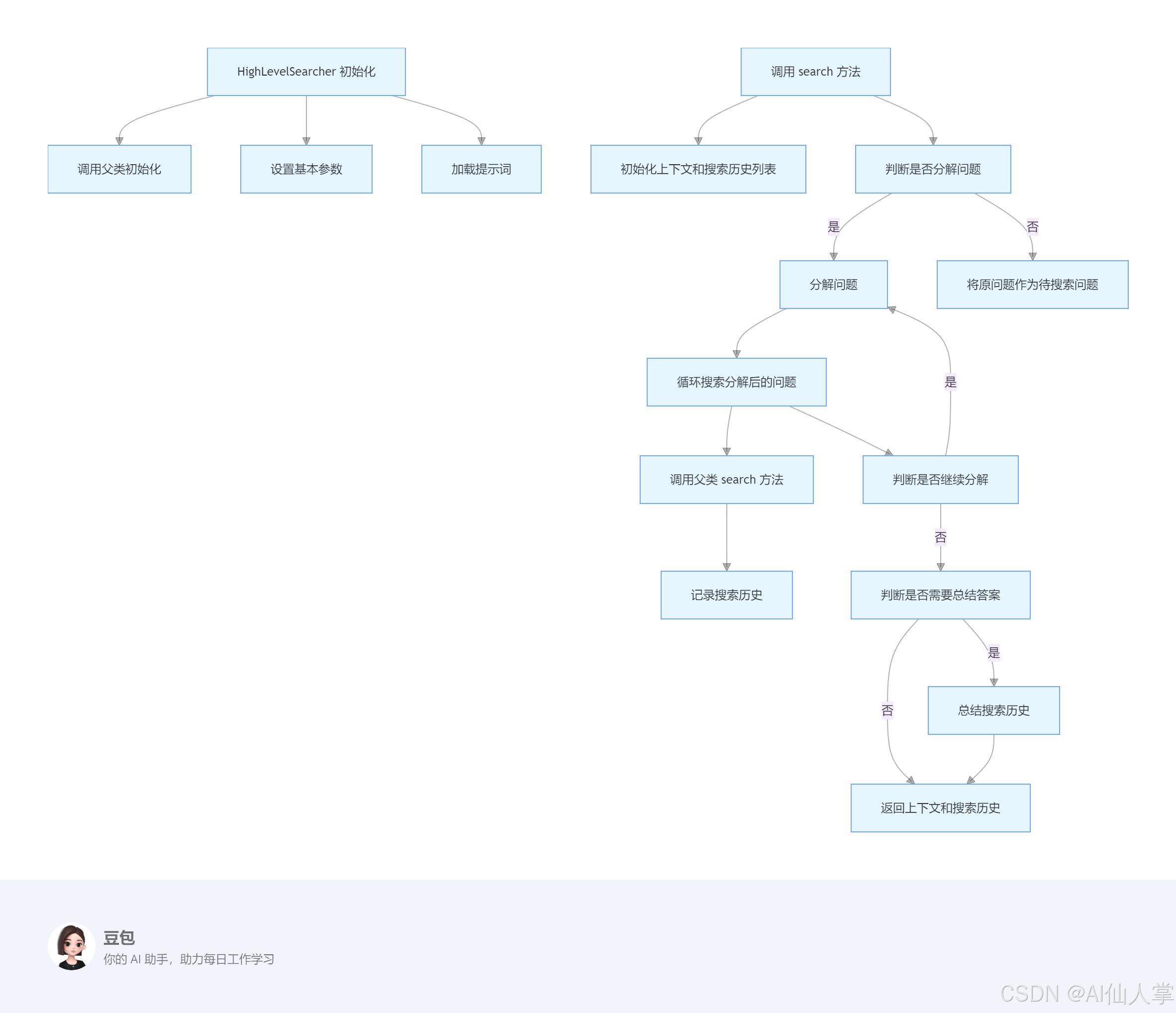
# 引入相关的装饰器和类,用于定义搜索器及其配置
@ASSISTANTS("highlevel", config_class=HighLevelSearcherConfig)
class HighLevelSearcher(HybridSearcher):
# 初始化方法,接收一个 HighLevelSearcherConfig 类型的配置对象
def __init__(self, cfg: HighLevelSearcherConfig) -> None:
# 调用父类的初始化方法
super().__init__(cfg)
# 设置基本参数
if not cfg.decompose:
# 如果配置中不进行问题分解,则最大分解次数设为 0
self.max_decompose_times = 0
else:
# 否则,将最大分解次数设为配置中的值
self.max_decompose_times = cfg.max_decompose_times
# 是否在分解问题时进行总结
self.summarize_for_decompose = cfg.summarize_for_decompose
# 是否在生成答案时进行总结
self.summarize_for_answer = cfg.summarize_for_answer
# 加载提示信息
# 加载带有上下文的问题分解提示
self.decompose_prompt_w_ctx = ChatPrompt.from_json(
os.path.join(
os.path.dirname(__file__),
"prompts",
"decompose_with_context_prompt.json",
)
)
# 加载不带有上下文的问题分解提示
self.decompose_prompt_wo_ctx = ChatPrompt.from_json(
os.path.join(
os.path.dirname(__file__),
"prompts",
"decompose_without_context_prompt.json",
)
)
# 加载用于根据答案进行总结的提示
self.summarize_prompt = ChatPrompt.from_json(
os.path.join(
os.path.dirname(__file__),
"prompts",
"summarize_by_answer_prompt.json",
)
)
return
# 分解问题的方法,接收问题和搜索历史作为参数,返回分解后的问题列表
def decompose_question(
self,
question: str,
search_history: list[dict[str, str | RetrievedContext]] = [],
) -> list[str]:
# 形成提示信息
if len(search_history) > 0:
# 如果有搜索历史,使用带有上下文的提示模板
prompt = deepcopy(self.decompose_prompt_w_ctx)
# 组合上下文信息
ctx_str = self.compose_contexts(search_history)
# 更新提示内容,包含问题和上下文信息
prompt.update(
ChatTurn(role="user", content=f"Question: {question}\n\n{ctx_str}")
)
else:
# 如果没有搜索历史,使用不带有上下文的提示模板
prompt = deepcopy(self.decompose_prompt_wo_ctx)
# 更新提示内容,仅包含问题
prompt.update(ChatTurn(role="user", content=f"Question: {question}"))
# 获取响应
response = self.agent.chat([prompt], generation_config=self.gen_cfg)[0][0]
if "No additional information is required" in response:
# 如果响应中包含不需要额外信息的提示,返回空列表
return []
# 定义用于分割响应的正则表达式模式
split_pattern = r"\[\d+\] ([^\[]+)"
# 使用正则表达式提取分解后的问题
decompsed = re.findall(split_pattern, response)
# 如果问题没有被分解且没有搜索历史,使用原问题
if (len(decompsed) == 0) and (len(search_history) == 0):
decompsed = [question]
# 去重问题
searched = set()
for s in search_history:
# 将搜索历史中的问题添加到集合中
searched.add(s["question"])
# 过滤掉已经搜索过的问题
decompsed = [i for i in decompsed if i not in searched]
return decompsed
# 组合上下文信息的方法,接收搜索历史作为参数,返回组合后的上下文字符串
def compose_contexts(
self, search_history: list[dict[str, str | list[RetrievedContext]]]
) -> str:
if self.summarize_for_decompose:
# 如果在分解问题时需要总结
# 对搜索历史进行总结
summed_text = self.summarize_history(search_history)
ctx_text = ""
for n, text in enumerate(summed_text):
# 组合总结后的上下文信息
ctx_text += f"Context {n + 1}: {text}\n\n"
# 去除最后多余的换行符
ctx_text = ctx_text[:-2]
else:
ctx_text = ""
n = 1
for item in search_history:
for ctx in item["contexts"]:
# 组合原始的上下文信息
ctx_text += f"Context {n}: {ctx.data['text']}\n\n"
n += 1
# 去除最后多余的换行符
ctx_text = ctx_text[:-2]
return ctx_text
# 对搜索历史进行总结的方法,接收搜索历史作为参数,返回总结后的文本列表
def summarize_history(
self, search_history: list[dict[str, str | list[RetrievedContext]]]
) -> list[str]:
summed_text = []
for item in search_history:
# 复制总结提示模板
prompt = deepcopy(self.summarize_prompt)
# 获取问题
q = item["question"]
usr_prompt = ""
for n, ctx in enumerate(item["contexts"]):
# 组合上下文信息
usr_prompt += f"Context {n + 1}: {ctx.data['text']}\n\n"
# 添加问题信息
usr_prompt += f"Question: {q}"
# 更新提示内容
prompt.update(ChatTurn(role="user", content=usr_prompt))
# 获取总结结果
ans = self.agent.chat([prompt], generation_config=self.gen_cfg)[0][0]
# 将总结结果添加到列表中
summed_text.append(ans)
return summed_text
# 搜索方法,接收问题作为参数,返回检索到的上下文和搜索历史
def search(
self, question: str
) -> tuple[list[RetrievedContext], list[dict[str, object]]]:
contexts = []
search_history = []
# 初始化分解次数
decompose_times = self.max_decompose_times
if decompose_times > 0:
# 如果分解次数大于 0,对问题进行分解
decomposed_questions = self.decompose_question(question)
# 分解次数减 1
decompose_times -= 1
else:
# 否则,使用原问题
decomposed_questions = [question]
# 搜索分解后的问题
while len(decomposed_questions) > 0:
# 取出一个问题
q = decomposed_questions.pop(0)
# 调用父类的搜索方法
ctxs, _ = super().search(q)
# 记录搜索历史
search_history.append({"question": q, "contexts": ctxs})
# 扩展上下文列表
contexts.extend(ctxs)
if (len(decomposed_questions) == 0) and (decompose_times > 0):
# 如果分解后的问题列表为空且还有分解次数,继续分解问题
decomposed_questions = self.decompose_question(question, search_history)
# 分解次数减 1
decompose_times -= 1
**# 后处理**
if self.summarize_for_answer:
# 如果在生成答案时需要总结
# 对搜索历史进行总结
summed_text = self.summarize_history(search_history)
# 重新组合上下文信息
contexts = [
RetrievedContext(
retriever="highlevel_searcher",
query=j["question"],
data={"text": i},
)
for i, j in zip(summed_text, search_history)
]
return contexts, search_history




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











