







一、核心问题与领域背景
传统RAG的局限性:
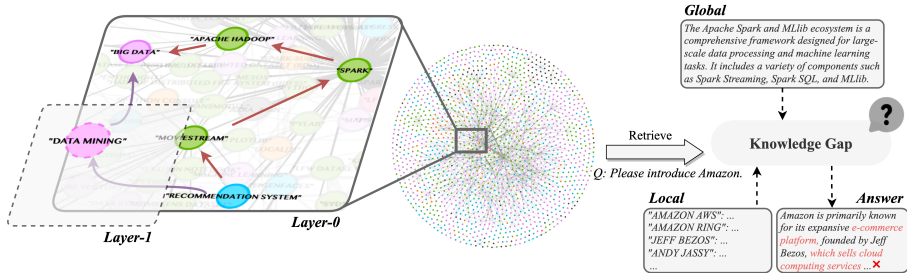
- 实体关系建模不足:传统方法基于文本块检索,忽略实体间的语义关联,导致生成内容缺乏逻辑连贯性。
- 局部与全局知识割裂:现有图谱RAG方法(如GraphRAG)依赖结构邻近性划分社区,但语义相似实体可能因文档分布疏远而无法关联。
- 人工依赖度高:部分方法(如KAG)需人工定义层次结构,难以扩展至通用领域。
领域意义:
HiRAG首次将层次化认知机制引入RAG系统,模仿人类从细节到抽象的多粒度认知过程,为垂直领域的复杂推理任务提供新范式。识别并解决了基于图的关系型自动摘要系统中的两个关键挑战:语义相似实体之间的远距离结构关系以及局部信息与全局信息之间的知识差距。引入了无监督的层次化索引和新颖的桥梁机制以实现有效的知识整合,显著推动了关系型自动摘要系统的最新技术发展。
二、技术原理深度解析 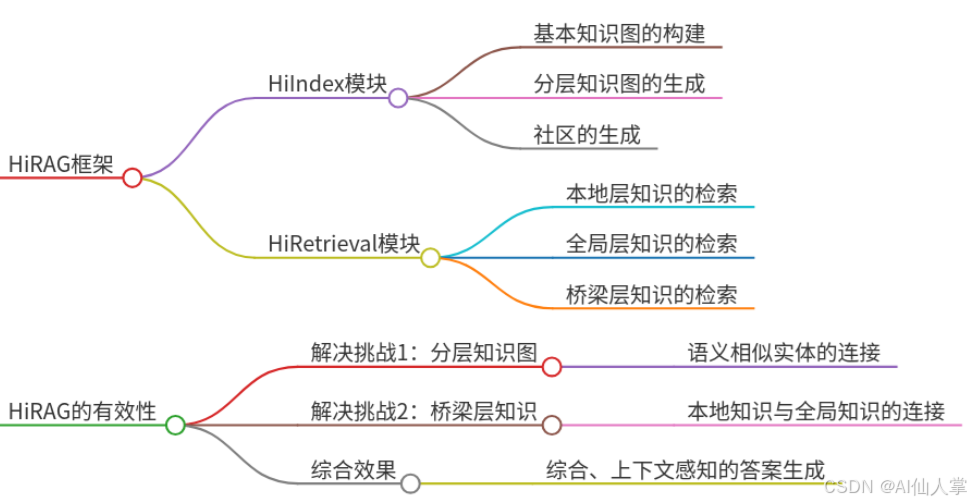
1. 层次化知识索引(HiIndex)
核心思想:构建多层知识图谱(KG),上层节点为下层实体的语义抽象,形成“概念-属性-实例”的认知金字塔。
实现步骤:
- 基础知识图谱构建(第0层)
- 实体提取:将输入文本分块后,利用LLM提取基础实体(如人物、技术、组织等),形成初始实体集合 V 0 \mathcal{V}_0 V0。
- 关系构建:LLM进一步分析文本块,识别实体间显式或隐式关系,生成基础知识图谱 G 0 \mathcal{G}_0 G0(含实体和关系边)。
- 迭代式层次生成(第1层到第k层)
(a) 语义聚类
- 嵌入计算:对当前层(如第i-1层)的实体生成语义嵌入向量 Z i − 1 \mathcal{Z}_{i-1} Zi−1。
- 高斯混合模型(GMM)聚类:基于嵌入向量将实体聚类为语义相似的簇集合 C i − 1 \mathcal{C}_{i-1} Ci−1。例如,"大数据"和"推荐系统"可能被聚到同一簇。
(b) 摘要实体生成
- LLM驱动的抽象化:将每个簇的实体描述输入LLM,结合预定义元摘要类型(如“技术”),生成更高层(第i层)的摘要实体(如“分布式计算”)。
- 跨层关系建立:将下层簇内实体与上层新生成的摘要实体连接,形成跨层关系边 E { i − 1 , i } \mathcal{E}_{\{i-1,i\}} E{ i−1,i}。
© 知识图谱更新
- 实体合并:将新生成的摘要实体加入总实体集合 V i = V i − 1 ∪ L i \mathcal{V}_i = \mathcal{V}_{i-1} \cup \mathcal{L}_i Vi=Vi−1∪
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











