







🧠 向所有学习者致敬!
“学习不是装满一桶水,而是点燃一把火。” —— 叶芝
我的博客主页: https://lizheng.blog.csdn.net
🌐 欢迎点击加入AI人工智能社区!
🚀 让我们一起努力,共创AI未来! 🚀
嘿,各位AI探险家们!今天咱们聊的RAG家族的新晋“纠错小能手”——CRAG!它就像是一个开卷考试里的“学霸助手”,不仅能帮你快速找到答案,还能自动过滤掉那些“不靠谱”的信息,确保你写的答案既准确又靠谱。通过本文你将理解以下信息
-
CRAG的三大绝招:
- 轻量级检索评估器:这个小家伙能快速判断检索到的文档是否靠谱,帮你过滤掉那些“牛头不对马嘴”的内容。
- 知识精炼算法:它能把检索到的文档“切碎”再“重组”,只留下最精华的部分,确保你拿到的是“纯干货”。
- 网络搜索补充:如果检索到的文档不够用,CRAG还能自动上网搜一搜,确保你不会因为信息不足而“卡壳”。
-
CRAG vs Self-RAG:谁更牛?
- CRAG:轻量级、即插即用,适合那些不想折腾复杂训练的小伙伴。
- Self-RAG:功能强大但复杂,适合那些愿意花时间“调教”模型的高手。
面对开卷考试。通常,我们有三种策略:
- 方法1:对于熟悉的话题快速作答。对于不熟悉的话题,参考参考书。快速定位相关部分,在脑海中整理和总结,然后在试卷上写下答案。
- 方法2:对于每个话题,参考书籍。识别相关部分,在脑海中总结,然后在试卷上写下答案。
- 方法3:对于每个话题,查阅书籍并识别相关部分。在形成观点之前,将收集到的信息分为三类:
正确、错误和模糊。分别处理每种类型的信息。然后,基于这些处理后的信息,在脑海中整理和总结。在试卷上写下答案。
最后,方法3被称为纠正性检索增强生成(CRAG),本文将介绍这一方法。
CRAG的动机
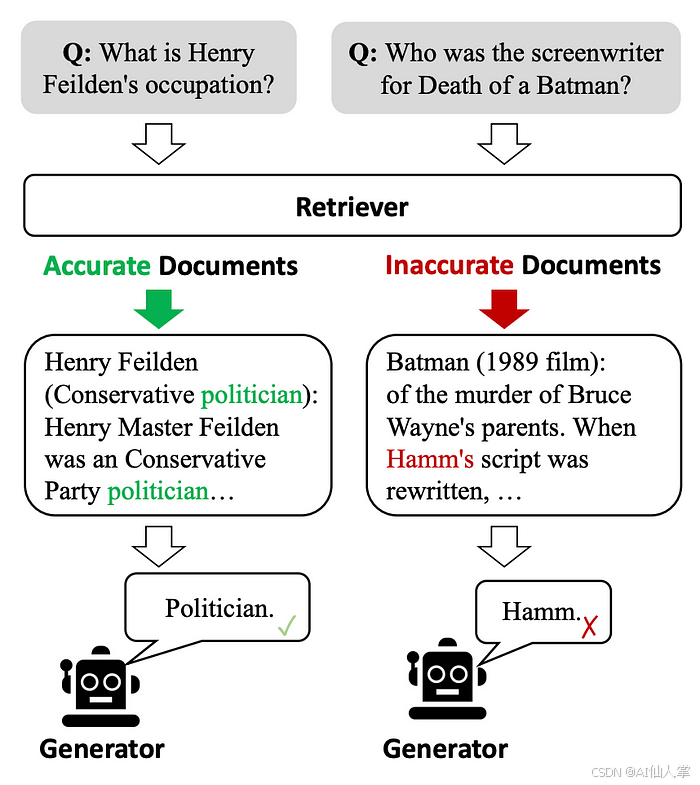
图1:示例显示低质量的检索器容易引入大量不相关信息,阻碍生成器获取准确知识并可能误导它们。来源:纠正性检索增强生成。
图1说明,大多数传统RAG方法不考虑文档与问题的相关性,只是简单地合并检索到的文档。这可能会引入不相关信息,阻碍模型获取准确知识并可能导致幻觉问题。
此外,大多数传统RAG方法将整个检索到的文档作为输入。然而,这些检索到的文档中的大部分文本通常对生成并不必要,也不应平等地参与RAG。
CRAG的核心思想
CRAG设计了一个轻量级的检索评估器,用于评估为特定查询检索到的文档的整体质量。它还使用网络搜索作为补充工具来改进检索结果。
CRAG是即插即用的,可以与各种基于RAG的方法无缝集成。整体架构如图2所示。
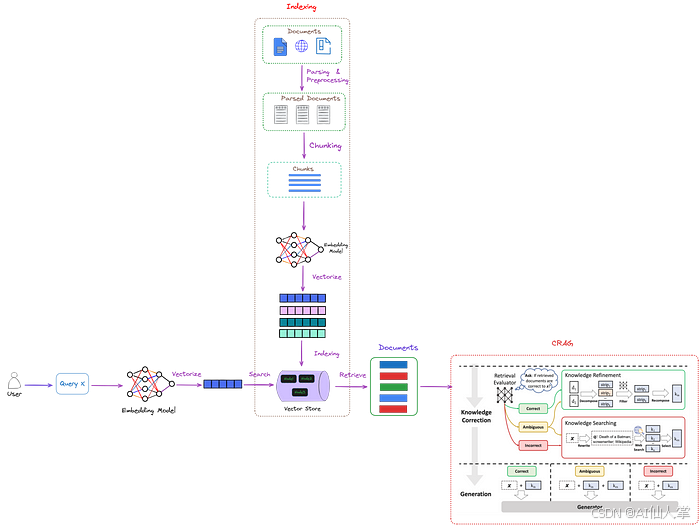
图2:CRAG(红色虚线框)在RAG中的位置。设计了一个检索评估器来评估检索到的文档与输入的相关性。它还估计一个置信度,可以触发不同的知识检索操作,即**{正确, 错误, 模糊}。这里,“x**”代表查询。图片由作者提供,CRAG部分(红色虚线框)来自纠正性检索增强生成。
如图2所示,CRAG通过引入检索评估器来评估检索到的文档与查询之间的关系,从而增强了传统RAG。
有3种可能的判断结果。
- 如果判断为**
正确**,这意味着检索到的文档包含查询所需的内容,然后使用知识精炼算法重写检索到的文档。 - 如果检索到的文档是**
错误**的,这意味着查询和检索到的文档不相关。因此,我们不能将文档发送给LLM。在CRAG中,使用网络搜索引擎检索外部知识。 - 对于**
模糊**的情况,这意味着检索到的文档可能接近但不足以提供答案。在这种情况下,需要通过网络搜索获取更多信息。因此,同时使用知识精炼算法和搜索引擎。
最后,处理后的信息被转发给LLM以生成响应。图3正式描述了这一过程。
图3:评估和处理。来源:纠正性检索增强生成。
注意,网络搜索并不直接使用用户的输入查询进行搜索。相反,它构建一个提示,并以少量示例的方式呈现给GPT-3.5 Turbo,以获取搜索查询。
在对方法有了大致了解后,让我们分别讨论CRAG的两个关键组件:检索评估器和知识精炼算法。
检索评估器
如图4所示,检索评估器显著影响后续程序的结果,并在确定整体系统性能方面至关重要。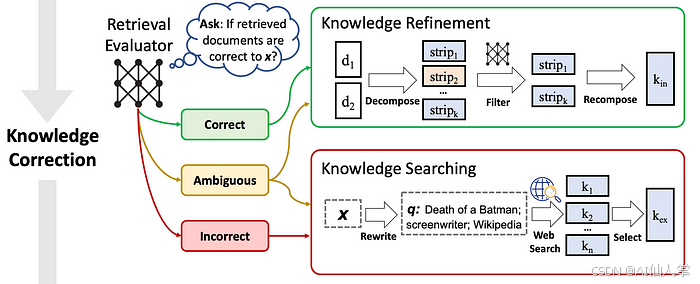
图4:CRAG中的知识纠正。来源:纠正性检索增强生成。
CRAG采用轻量级的T5-large模型作为检索评估器并对其进行微调。值得注意的是,在大语言模型时代,T5-large也被认为是轻量级的。
对于每个查询,通常检索十个文档。然后将查询与每个文档分别连接作为输入,以预测它们的相关性。在微调过程中,将正样本标记为1,负样本标记为-1。在推理过程中,评估器为每个文档分配一个相关性分数,范围从-1到1。
这些分数将根据阈值分为三个级别。显然,这种分类需要两个阈值。在CRAG中,阈值设置可能因实验数据而异:
触发三种操作的两个置信度阈值是根据经验设置的。具体来说,在PopQA中设置为(0.59, -0.99),在PubQA和ArcChallenge中设置为(0.5, -0.91),在Biography中设置为(0.95, -0.91)。
知识精炼算法
对于检索到的相关文档,CRAG设计了一种分解-重组的知识提取方法,以进一步提取最关键的知识陈述,如图4所示。
首先,应用启发式规则将每个文档分解为细粒度的知识条,旨在获得细粒度的结果。如果检索到的文档仅由一两句话组成,则将其视为独立单元。否则,将文档划分为较小的单元,通常由几个句子组成,具体取决于总长度。每个单元应包含一个独立的信息片段。
接下来,使用检索评估器计算每个知识条的相关性分数。过滤掉相关性分数较低的知识条。然后将剩余的相关知识条按顺序重新组合,形成内部知识。
代码解读
CRAG是开源的,Langchain和LlamaIndex都提供了各自的实现。我们将使用LlamaIndex的实现作为参考进行解释。
环境配置
conda create -n crag python=3.11
conda activate crag
pip install llama-index llama-index-tools-tavily-research
mkdir "YOUR_DOWNLOAD_DIR"
安装后,LlamaIndex和Tavily的对应版本如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











