







8.SubmittingFrom A Kernel从kernel 提交
本文是Kaggle自助学习下的文章,转回到目录点击这里
This is partof the MachineLearning course. Inthis step, you will learn to submit your model to a machine learningcompetition. It's fun, and it will give you a way to see your progress as yourskills keep improving.这是机器学习课程的一部分。在这一步中,您将学习向机器学习竞赛提交您的模型。有趣的是,它会让你看到你的进步,使你的技能不断提高。
Introduction 介绍
Machine learning competitions are a great way to improve your skillsand measure your progress as a data scientist. If you are using data from acompetition on Kaggle, you can easily submit it from your notebook. Here's howyou do it.机器学习竞赛是一种提高你的技能,让你作为一名数据科学家的进步的好方法。如果你使用的是Kaggle竞赛的数据,你可以很容易地从你的notebook上提交它。这里将告诉你怎么做。
Example 例
We're doing veryminimal data set up here so we can focus on how to submit modeling results tocompetitions. Other tutorials will teach you how build great models. So themodel in this example will be fairly simple. We'll start with the code to readdata, select predictors, and fit a model.本节课设置的数据非常少,是因为我们要专注于如何将建模结果提交到竞赛。其他教程将教你如何建立伟大的模型。所以这个例子中的模型将非常简单。我们将从代码开始读取数据,选择预测因子并拟合模型。
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
# Read the data
train = pd.read_csv('../input/train.csv')
# pull data into target (y) and predictors (X)
train_y = train.SalePrice
predictor_cols = ['LotArea', 'OverallQual', 'YearBuilt', 'TotRmsAbvGrd']
# Create training predictors data
train_X = train[predictor_cols]
my_model = RandomForestRegressor()
my_model.fit(train_X, train_y)
In addition to yourtraining data, there will be test data. This is frequently stored in a filewith the title test.csv. This data won't include a column with your target (y), becausethat is what we'll have to predict and submit. Here is sample code to do that. 除了你的训练数据之外,还会有测试数据。这通常存储在标题为test.csv的文件中。这些数据不会包含您的目标(y)列,必须用模型预测这个数据并且提交。这里的示例代码可以做到这一点。
# Read the test data
test = pd.read_csv('../input/test.csv')
# Treat the test data in the same way as training data. In this case, pull same columns.
test_X = test[predictor_cols]
# Use the model to make predictions
predicted_prices = my_model.predict(test_X)
# We will look at the predicted prices to ensure we have something sensible.
print(predicted_prices)
Prepare Submission File 准备提交文件
We make submissions in CSV files. Yoursubmissions usually have two columns: an ID column and a prediction column. TheID field comes from the test data (keeping whatever name the ID field had inthat data, which for the housing data is the string 'Id'). The predictioncolumn will use the name of the target field.我们将用CSV进行提交。您提交的csv通常有两个列:一个ID列和一个预测值。ID字段来自测试数据(保留ID字段在该数据中的任何名称,对于住房数据,该名称是字符串‘ID’)。“预测”列就是你预测得出的值。
We will create a DataFrame with thisdata, and then use the dataframe's to_csv methodto write our submission file. Explicitly include the argument index=False to prevent pandas fromadding another column in our csv file.我们将用这些数据创建一个DataFrame,然后使用数据框的to_csv方法编写我们的提交文件。显式包含参数index = False,这是以防止pandas在我们的csv文件中添加另一列。
my_submission = pd.DataFrame({'Id': test.Id, 'SalePrice': predicted_prices})
# you could use any filename. We choose submission here
my_submission.to_csv('submission.csv', index=False)
MakeSubmission 去提交吧
Hit the blue Publish buttonat the top of your notebook screen. It will take some time for your kernel torun. When it has finished your navigation bar at the top of the screen willhave a tab for Output. Thisonly shows up if you have written an output file (like we did in the Prepare Submission File step).点击notebook屏幕顶部的蓝色“发布”按钮。kernel运行需要一些时间。完成后,屏幕顶部的导航栏将有一个输出选项卡。这只有在你写了一个输出文件时才会显示出来(就像我们在准备提交文件中所做的那样)。
1.
注意先保存到本地
2.
I think "Publish" should be change to"Commit&Run" ,然后等很久很久,直到出现
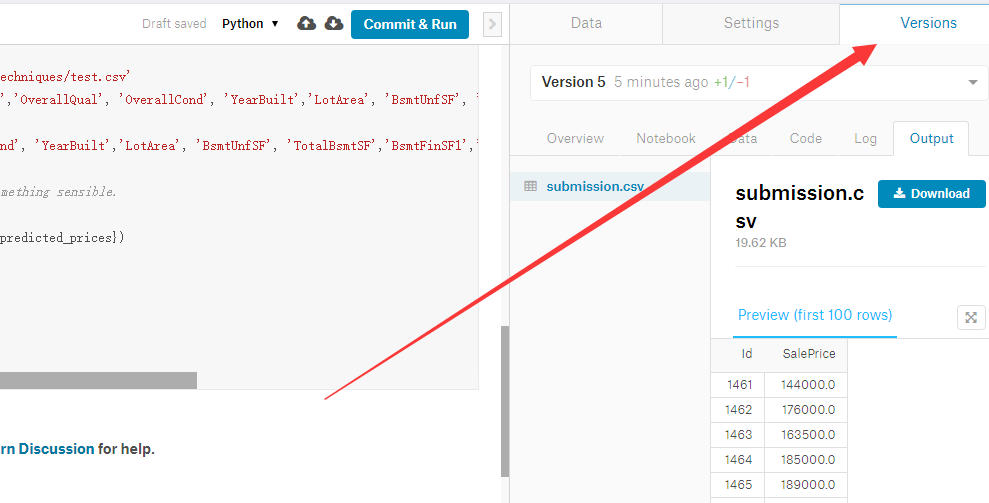
3. 如果你没有输出文件,说明你代码运行失败了或者你根本没有写出最后一行。
4. 在OutPut里,有下载 还有提交到比赛。 如果你没有提交到比赛,说明你还没有报名,请先报名(哪?自己找去)
5. 好吧,我找了半个小时。最终是通过数据Data 里 有个About this Dataset。点击进入那个比赛页面报名。(怪不得评论全都是 Why is there no “submitto Competition” )
6. 我给的测试集可以有提交,但是必须要有1459行(因为到现在学的还不够,所以filter了)
Last Steps最后一步
Clickon the Output button. This will bring you to a screen with an option to Submit to Competition.Hit that and you will see how your model performed.点击输出按钮。然后会有一个选项来提交到竞赛。点击这个,你会看到你的模型是如何的优秀。
If you want to go back toimprove your model, click the Edit button, which re-opens the kernel. You'llneed to re-run all the cells when you re-open the kernel. 如果你想回去改进你的模型,点击编辑按钮,重新打开kernel。重新打开kernel时,您需要重新运行所有单元。
Conclusion 结论
You've completedLevel 1 of Machine Learning. Congrats. 你已经完成了第一级的机器学习。恭喜你。也感谢各位看完我蹩脚的翻译/学习笔记
If you are readyto keep improving your model (and your skills), start level 2 of Learn MachineLearning.如果你准备继续改进你的模型(和你的技能),开始学习机器学习的第2级。
Level 2 coversmore powerful models, techniques to include non-numeric data, and more. You canmake more submissions to the competition and climb up the leaderboard as you gothrough the course.第2级涵盖更强大的模型,包含处理非数字数据的技术等等。您可以在参加比赛时向比赛提交更多意见,并在排行榜上再接再厉~。
致此,第一级到此结束。
本文是Kaggle自助学习下的文章,转回到目录点击这里


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









