








一转眼又好久没更新了。
在本文我们介绍一个之前没有看过的新任务:Emotion Cause Extraction (ECE),也就是给定一个上下文,从中寻找情绪子句对应的原因。从直觉来说,大多数带注释的原因子句要么直接位于其相关的情感子句之前,要么就是情感子句本身(如图1所示),因此位置信息是十分重要的,会影响模型的鲁棒性,而现有的方法多是通过相对位置来解决这个问题的,没有图神经网络来得直接。因此,本文提出了一种新的基于图的方法,通过利用常识增强候选子句和情感子句之间的语义依赖关系来显式建模情感触发路径。建立情感触发路径需要借助外部知识库ConceptNet,构建了包含序列边(SEdge)和知识边(K-Edge)两种边的图结构。S-Edge连接两个连续的子句来获取子句的邻域信息,而K-Edge连接候选子句和情感子句,如果它们之间存在从概念网中提取的知识路径。

Method
任务定义
首先给出任务的公式化描述。给定一个包含 N N N个clause的文档 D = { C i } i = 1 N D=\{ C_i \}_{i=1}^N D={Ci}i=1N,其中有一个 C E C_E CE被标记为含有某种情感,ECE的任务许要从中找出一个或者多个造成该情感的原因 C t , 0 < t < N + 1 C_t, 0<t<N+1 Ct,0<t<N+1。注意,emotion子句本身可以是cause子句。
模型架构
模型总体的架构如图所示:
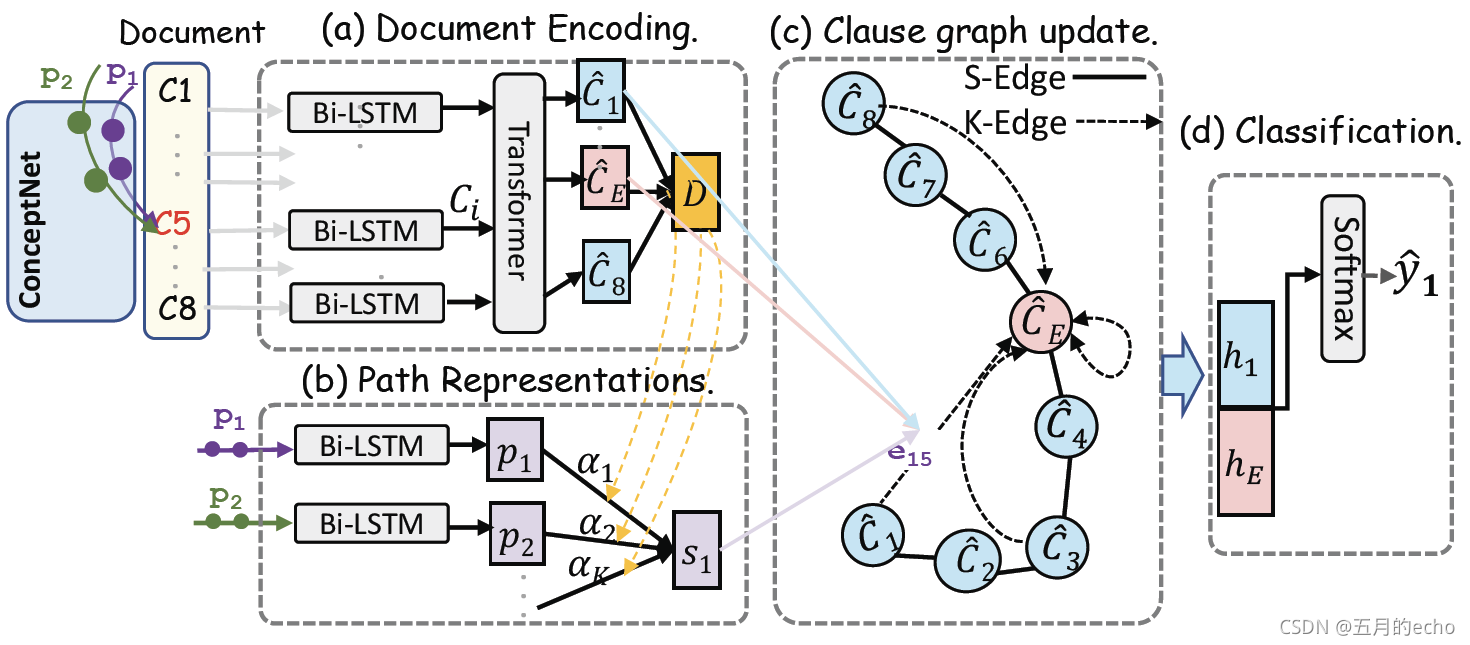
首先,对于
D
D
D,使用BiLSTM得到句子的向量化表示,并从ConceptNet中选出一个情感依赖的路径。对于路径,因为其内部必定包含某些单词节点,因此也可以使用BiLSTM+Attention进行路径表示。之后,就是基于GNN的特征提取,判断某一个节点是否为
h
E
h_E
hE所对应情绪的原因,将原因的提取转化为了一个节点二分类的任务。
Knowledge-Aware Graph (KAG) Model for Emotion Cause Extraction
首先看如何构图。
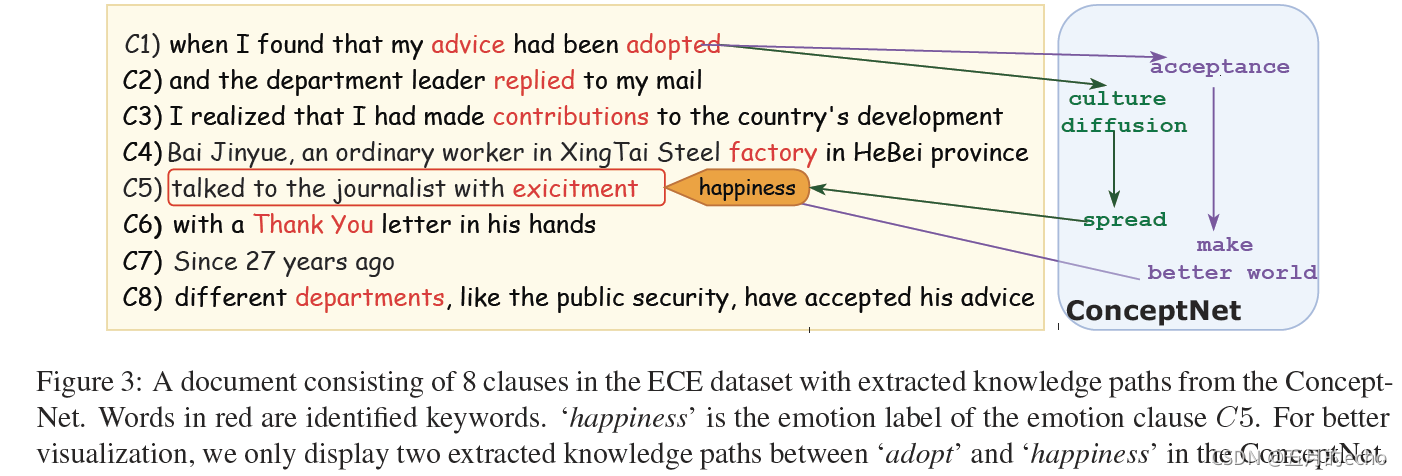
首先对一个句子使用jieba对emotion clause进行分词,然后使用TextRank提取出排名前三的关键词。之后,将candidate clause中的每个单词视为头实体
e
h
e_h
eh,去ConceptNet中查找尾实体
e
t
e_t
et(排名前三的关键词)。如果在三跳之内,能够到达
e
t
e_t
et,则说明candidate clause与emotion clause存在强依赖关系,因此可以给它们之间添加边K-Edge。因为并不是概念网中的所有关系都与因果关系相关或表明因果关系,进一步去除包含这四种关系中的任何一种的路径:‘antonym’, ‘distinct from’, ‘not desires’, and ‘not capable of ’。一个具体的例子如下:
Knowledge-Aware Graph (KAG) Model
有了图之后,就可以使用GCN建模了。
首先,将BiLSTM的输出
C
i
C_i
Ci(这个是句子级别的表示)与位置信息编码
o
i
o_i
oi进行拼接,并输入到Transformer中进行表示学习,目的是借助Transformer强调位置信息,并在后续的操作中方便对
o
i
o_i
oi进行替换以验证文本提出的方法的抗位置干扰的能力:

C
i
^
\hat{C_i}
Ci^学习到的是当前clause
i
i
i在整个文档
D
D
D中的位置。之后对路径进行表示。实际上,一对实体之间可能存在多条路径,如图3所示,一个紫色一个绿色,而紫色知识路径与文档上下文的关联更紧密。因此,使用路径与上下文的相似度去计算对最终结果的影响:

p
t
p_t
pt是使用BiLSTM得到的路径向量,
D
D
D是文档的表示。之后,就可以借助GCN的变体R-GCN对图进行更新了。在更新的时候,考虑了两个不同类型的边扮演的不同角色。
对于K-Edge,受到一些Trans家族方法的启发,如果一个子句对包含由K-Edge描述的可能推理过程,应该有如下的近似:

也就是说,假如候选clause
i
i
i能够由某种关系
s
i
s_i
si推到出
E
E
E情感,那么三者应该有类似于一个三元组的表示方式。因此,使用scaled Dot-Attention去计算衡量上述三元组关系的相似因子
e
i
E
e_{iE}
eiE,并用以作为注意力系数得到当前的clause
i
i
i对最终情感的贡献程度:

之后,节点的更新表示为:

其中
N
i
r
s
N_i^{rs}
Nirs是S-Edges类型边对应的邻居节点。最终,将候选子句节点
h
i
h_i
hi与由图生成的情感节点表示
h
e
h_e
he连接起来,并应用softmax函数得到预测类分布:

Experiments

模型的效果要好于其他基线。通过去除K-Edge或S-Edge或两者进行了消融研究(无R-GCNs)。结果表明,去除RGCNs导致F1的下降近4.3%。此外,K-Edge和S-Edge都有助于提取情绪原因。由于上下文建模考虑了位置信息,因此去除S-Edge的下降幅度小于去除K-Edge的下降幅度。
Impact of Encoding Clause Position Information
为了检验在不同模型中使用子句位置信息的影响,我们将候选子句的相对位置信息替换为绝对位置信息。在极端情况下,我们从模型中删除位置信息。

可见本文提出的方法对于位置信息的改变具备更强的鲁棒性。
Performance under Adversarial Samples
通过交换两个子句
C
r
1
C_{r1}
Cr1和
C
r
2
C_{r2}
Cr2生成对抗性的例子来欺骗ECE模型,其中
r
1
r1
r1表示最有可能的原因子句的位置,而
r
2
r2
r2表示最不可能的原因子句的位置。
r
1
r_1
r1选取:由于数据集中观测到的分布(如图1所示)显示,数据集中超过一半的原因子句位于emotion子句之前,因此假设原因子句的位置可以用高斯分布建模,并直接从数据估计均值和方差,也就是:

由于采样值是连续的,本文将其四舍五入到最接近的整数:

r
2
r_2
r2选取:为了找到最小可能的原因子句,我们建议根据候选子句和情感子句之间的注意分值来选择:

将这两个节点的位置对换之后,不同模型的表现如下:

所列四个ECE模型分别受到由各自鉴别器产生的对抗样本的攻击。与其他列出的ECE模型相比,本文的模型显示了所有对抗样本集的最小下降率。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











