







- 编写 Cypher 代码
- 过滤查询
- 查看图中的唯一性约束索引
- SHOW CONSTRAINTS
- 查看图中关系的属性类型
- CALL db.schema.relTypeProperties()
- 查看图中节点的属性类型
- CALL db.schema.nodeTypeProperties()
- 查看数据模型
- CALL db.schema.visualization()
- 用 WHERE 子句添加过滤条件
- 查询执行历史
- :history
- EXPLAIN 关键字检查是否将使用索引(相当于Oracle中的执行计划)
- EXPLAIN MATCH(m:Movie) WHERE m.title STARTS WITH 'Toy Story' RETURN m.title,m.released
- 使用了索引
- EXPLAIN 提供了查询步骤的估计值
- EXPLAIN MATCH(m:Movie) WHERE m.title STARTS WITH 'Toy Story' RETURN m.title,m.released
- PROFILE 关键字来显示从查询中的图形中检索到的总行数。
- 主要看执行计划 plan 中的 db hits
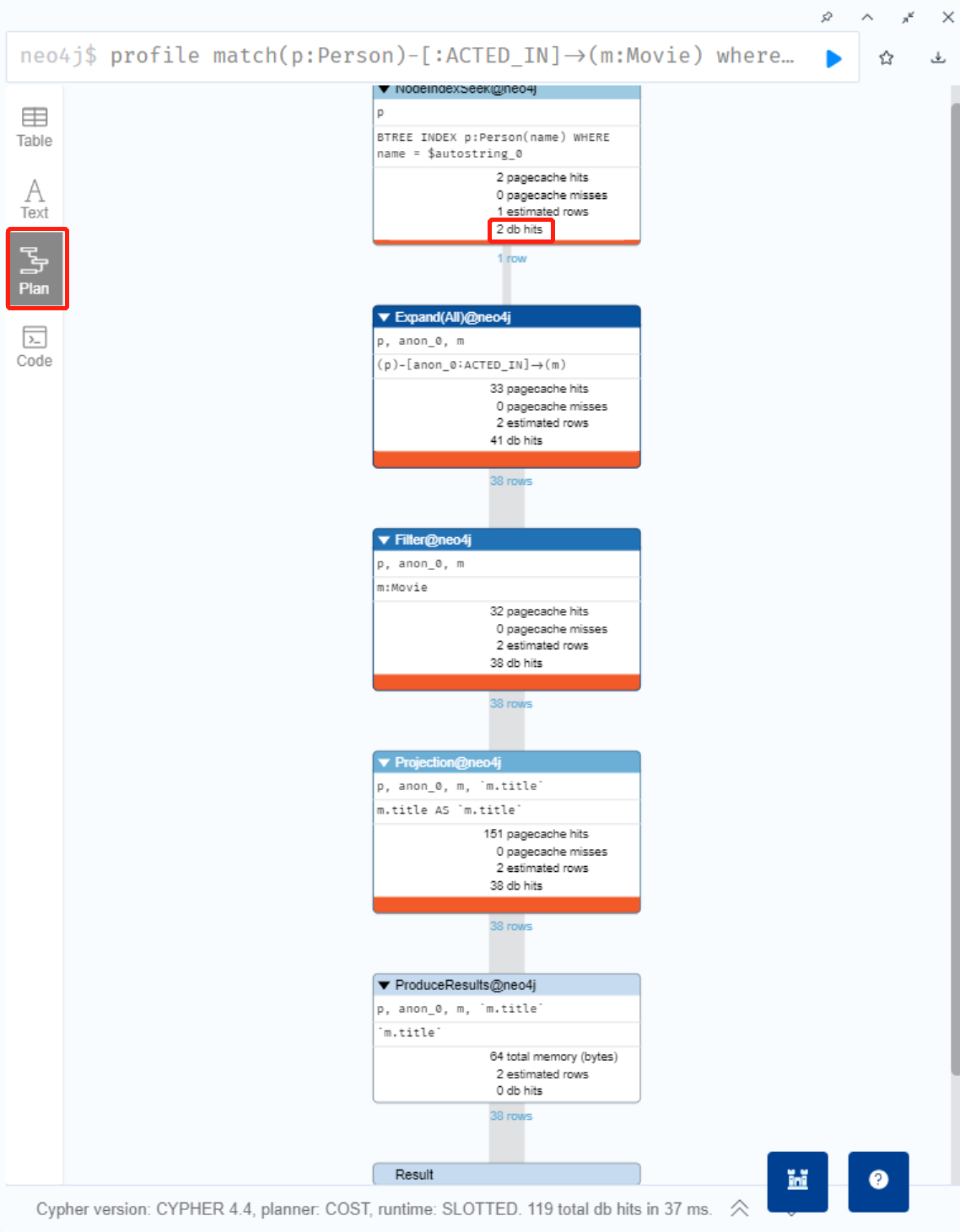
- PROFILE 提供了为查询检索的确切步骤和行数。
- 只是查询图形而不更新任何内容,则可以使用 PROFILE
- 主要看执行计划 plan 中的 db hits
- 使用多 MATCH 子句
- 包含两 MATCH 子句
- OPTIONAL MATCH 类似于 MATCH 区别在于前者对模式的缺失部分使用空值。
- MATCH (m:Movie) WHERE m.title = "Kiss Me Deadly" MATCH (m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie) OPTIONAL MATCH (m)<-[:ACTED_IN]-(a:Actor)-[:ACTED_IN]->(rec) RETURN rec.title, a.name
- 模式理解:用 | 表示关系或语句的并列
- MATCH (p:Person)-[ :ACTED_IN | DIRECTED ] ->(m) RETURN p
- 模式理解是一种非常强大的方法,可以在不改变查询基数的情况下创建列表。它的行为类似于 OPTIONAL MATCH 与 collect() 。
- 对于模式理解,我们用方括号指定列表以包含模式,后跟竖线字符,然后指定将根据模式将什么值放入列表中。 [<pattern> | value]
- MATCH (m:Movie) WHERE m.year = 2015 RETURN m.title,[(dir:Person)-[:DIRECTED]->(m) | dir.name] AS directors,[(actor:Person)-[:ACTED_IN]->(m) | actor.name] AS actors
- 查看图中的唯一性约束索引
- 返回结果
- 映射投影以返回数据
- 更改返回的数据
- 添加或合并属性值用 + 号(类似Oracle的 || )
- match(m:Movie)<-[:ACTED_IN]-(p:Person) where m.title contains 'Toy Story' and p.died is null return 'Movie:'+ m.title as movie
- 添加或合并属性值用 + 号(类似Oracle的 || )
- 有条件返回数据
- CASE WHEN...THEN...ELSE...END
- 返回列表
- match(p:Person) return p.name,[p.born,p.died] as lifeTime limit 10
- 返回别名用 AS ,Oracle可用可不用,但Neo4j必须要用
- 聚合函数
- count()
- 查询处理期间对节点、关系、路径、行进行计数。
- Cypher 中的聚合不同于 SQL 中的聚合。
- Cypher不需要分组,一旦 count() 使用类似聚合函数,所有非聚合结果列都会成为分组。RETURN分组是根据子句中的字段隐式完成的。
- collect()
- 创建列表,能够将值聚合到一个列表中。
- match(p:Person)-[:ACTED_IN]->(m:Movie) return p.name as actor,count(*) as total,collect(m.title) as movies order by total desc limit 10
- 该值可以是任何表达式,例如属性值、节点或函数或操作的结果。
- 消除列表中的重复数据
- match(p:Person)-[:ACTED_IN]->(m:Movie) return p.name as actor,count(*) as total,collect(m.title) as movies order by total desc limit 10
- 采集结点
- MATCH(p:Person)-[:ACTED_IN]->(m:Movie) WHERE p.name="Tom Cruise" RETURN collect(m) AS tomCruiseMovies
- 访问列表元素
- [index-value]您可以使用列表以索引 0 开头的符号访问列表的特定元素。
- 访问列表的一个元素(字符串)
- 访问列表中二个或十个以上字符
- 列表的理解
- 如Oracle中的数组或集合
- 创建列表,能够将值聚合到一个列表中。
- size()
- 返回列表中元素的数据条数(列表计数)
- min()
- max()
- avg()
- stddev()
- sum()
- 时间函数
- RETURN date(), datetime(), time()
- date()
- datetime()
- time()
- 创建时间测试节点
- MERGE (x:Test {id: 1}) SET x.date = date(), x.datetime = datetime(), x.time = time() RETURN x
- 添加时间节点属性
- MATCH (x:Test {id: 1})SET x.date1 = date('2022-01-01'), x.date2 = date('2022-01-15') RETURN x
- 查询两时间属性的时间差
- MATCH (x:Test {id: 1}) RETURN duration.between(x.date1,x.date2)
- MATCH (x:Test {id: 1})RETURN duration.inDays(x.datetime1,x.datetime2).days
- 属性添加时间
- MATCH (x:Test {id: 1}) RETURN x.date1 + duration({months: 6})
- 使用APOC格式化日期和时间
- match(x:Test{id:1}) return x.datetime as Datetime,apoc.temporal.format(x.datetime,'HH:mm:ss.SSSS') as forDateTime
- match(x:Test{id:1}) return apoc.date.toISO8601(x.datetime.epochMillis,'ms') as iso8601
- count()
- 函数
- trim() 函数来确保语言名称中没有多余的空白字符。
- 过滤查询
















03-21
02-12
 387
387
387
07-13
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









