









目录
Combining Both Loss Contributions
论文名称:Cross and Learn: Cross-Modal Self-supervision(2018 GCPR: German Conference on Pattern Recognition)
论文作者:Nawid Sayed, Biagio Brattoli, and Bj¨orn Ommer
下载地址:https://link.springer.com/chapter/10.1007/978-3-030-12939-2_17
Contributions
In this paper, we use cross-modal information as an alternative source of supervision and propose a new method to effectively exploit mutual information to train powerful feature representations for both modalities. The main motivation of our approach is derived from the following observation: Information shared across modalities has a much higher semantic meaning compared to information from modality-specific. So, our goal is to obtain feature representations that are sensitive to cross-modal information while being invariant to modality-specific content. These conditions are fulfilled by feature representations that are similar for a pair and dissimilar across different pairs. To achieve that we utilize a trainable two stream architecture with one network per modality similar to (Two-stream network) as the backbone of the proposed framework. Meanwhile, to achieve the former we propose a cross-modal loss L_cross, and to achieve the latter we utilize a diversity loss L_div, both of which act directly in feature space thus promising better training signals.

Method
Our method requires paired data from two different modalities x ∈ X and y ∈ Y, which is available in most use cases i.e. RGB and optical flow. We utilize a two-stream architecture with trainable CNNs in order to obtain our feature representations f(x) and g(y). With exception of the first layer, the networks share the same architecture but do not share weights. To calculate both loss contributions we need a tuple of pairs xi, yi and xj, yj from our dataset.

Cross-Modal Loss
In order to enforce cross-modal similarity between f and g we enforce the feature representations of a pair to be close in feature space via some distance d. Solving this task requires the networks to ignore information which is only present in either x or y
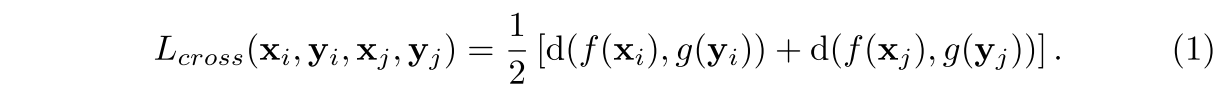
We utilize the bounded cosine distance for d, which is given by
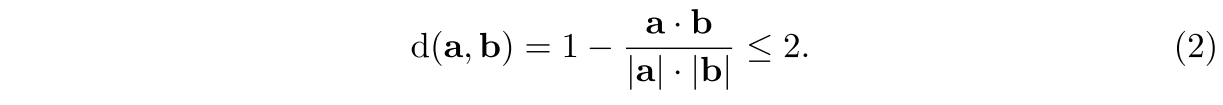
Diversity Loss
We obtain diversity by enforcing the feature representation for both modalities to be distant across pairs with respect to the same distance d as before. This spreads the features of different pairs apart in feature space. Due to the cross-modal loss these features mostly encode cross-modal information, thus ensuring sensitive feature representations for this content. The distance across pairs therefore contributes negatively into the loss

Combining Both Loss Contributions
Given our observations, we weight both loss contributions equally which yields our final loss
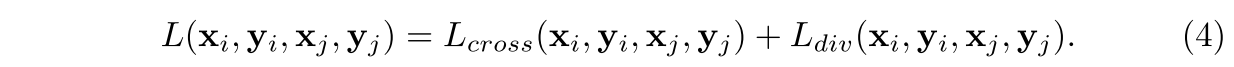
Results

















 1376
1376











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









