









写在前面
方法部分好多公式变量,编辑器再打一遍好麻烦。。。偷个懒,就直接把这部分的笔记导出成图片咯,并且我按我自己理解比较顺的逻辑重新捋了一下。
3D Human Action Representation Learning via Cross-View Consistency Pursuit
(2021 CVPR)
Linguo Li, Minsi Wang, Bingbing Ni, Hang Wang, Jiancheng Yang, Wenjun Zhang
Notes
1. Contributions
We propose CrosSCLR, a cross-view contrastive learning framework for skeleton-based action representation. First, we develop Contrastive Learning for Skeleton-based action Representation (SkeletonCLR) to learn the singleview representations of skeleton data. Then, we use parallel SkeletonCLR models and CVC-KM to excavate useful samples across views, enabling the model to capture more comprehensive representation unsupervisedly. We evaluate our model on 3D skeleton datasets, e.g., NTU-RGB+D 60/120, and achieve remarkable results under unsupervised settings.
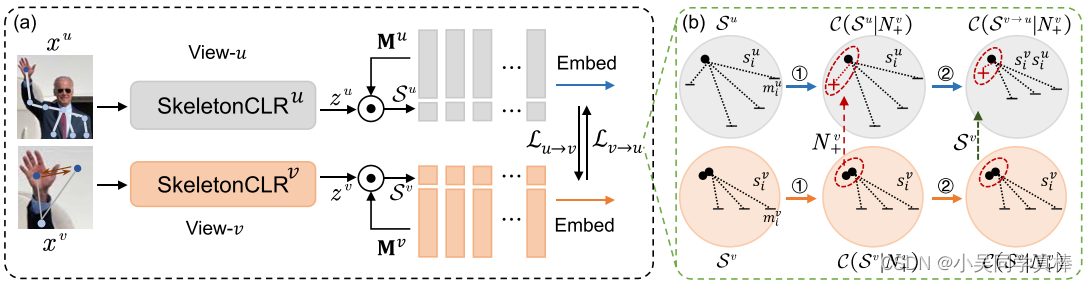
2. Method
2.1 SkeletonCLR.
It is a memory-augmented contrastive learning method for skeleton representation, which considers one sample’s different augments as its positive samples and other samples as negative samples. In each training step, the batch embeddings are stored in first-in-first-out memory to get rid of redundant computation, serving as negative samples for the next steps.


2.2 High-confidence Knowledge Mining
We define as the similarity set S among z and M as
![]()
Then, we set the most similar embeddings as positive to make it more clustered:

where Γ = Topk is the function to select the index of top-K similar embeddings and N+ is their index set in memory bank.
2.3 Cross-View Consistency Learning
The views of skeleton can be joint, motion, bone, and motion of bone. We design the cross-view consistency learning which not only mines the high-confidence positive samples from complementary view but also lets the embedding context be consistent in multiple views. It contains two aspects:

2.4 Learning CrosSCLR
For more views, CrosSCLR has following objective:
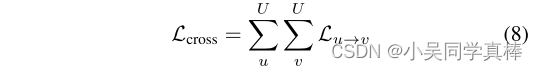
where U is the number of views and v ≠ u . In the early training process, the model is not stable
and strong enough to provide reliable cross-view knowledge without the supervision of labels. As the unreliable information may lead astray, it is not encouraged to enable cross-view communication too early. We perform two-stage training for CrosSCLR:
1) each view of the model is individually trained with Equation (1) without cross-view com- munication.
2) then the model can supply high-confidence knowledge, so the loss function is replaced with Equation (8), starting cross-view knowledge mining.















 907
907











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









