






论文解读《Conflict-Based Cross-View Consistency for Semi-Supervised Semantic Segmentation》
论文解读《基于冲突的半监督语义跨视图一致性研究分割》
论文出处:CVPR2023
论文代码:论文代码
论文地址:论文地址
一、摘要: 一种基于冲突的跨视图一致性(CCVC)方法,该方法基于一个双分支协同训练框架,旨在强制两个子网从不相关的视图中学习信息特征。
二、论文的工作:
(1) 一种基于协同训练框架的跨视图一致性(CVC)策略。
(2) 进一步提出了一种新的基于冲突的伪标记(CPL)方法。
三、方法
在SSS任务中,我们给定一组完整的像素级标注图像
和一组未标记图像
分别表示标记图像和未标记图像的数量。N»m。
表示大小为H×W和C通道的输入图像,而
是每个像素的one-hot 标准标签,其中Y表示视觉类别的总数。
3.1 跨视图一致性


图2。跨视图一致性(CVC)方法的网络架构。使用特征差异损失来强制网络从不同的视图生成相同的输入。一方面,我们使用 监督损失和一致性损失 
进行交叉监督。另一方面,我们使用 差异损失
来最小化特征提取器提取的特征之间的相似性,从而迫使两个子网学习不同的信息。下标i表示第i个子网,上标o表示标记数据或未标记数据。//标记表示禁止反向传播。
本节介绍新提出的crossview consistency (CVC)方法。我们利用了一个基于co-training的双分支网络,其中两个子网,即T1和T2,具有相似的架构,但两个子网的参数不共享。网络架构如图2所示。在这里,我们将每个子网分为一个特征提取器Tf,i和一个分类器Tcls,i ,其中i等于1或2,分别表示第一个子网和第二个子网。
,其中i等于1或2,分别表示第一个子网和第二个子网。
使用差异损失 最小化每个特征提取器提取的特征
最小化每个特征提取器提取的特征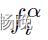 之间的余弦相似度,可以表示为:
之间的余弦相似度,可以表示为: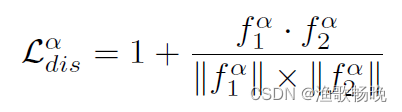 注意系数1是为了确保差异损失的值总是非负的。鼓励两个子网输出没有相互关系的特征,从而强制两个子网学习从两个不相关的视图中推理输入。
注意系数1是为了确保差异损失的值总是非负的。鼓励两个子网输出没有相互关系的特征,从而强制两个子网学习从两个不相关的视图中推理输入。
我们遵循类似BYOL[19]和SimSiam[9]的操作来异构我们的网络,使用一个简单的卷积层,即 ,带一个非线性层,将
,带一个非线性层,将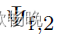 提取的特征映射到另一个特征空间。我们将
提取的特征映射到另一个特征空间。我们将 经过映射后提取的特征记为
经过映射后提取的特征记为 ,差异损失重写为:
,差异损失重写为: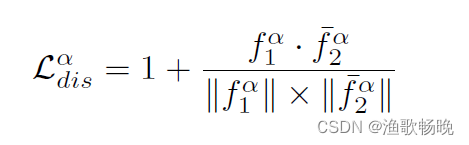 我们对标记数据和未标记数据都应用了差异监督,因此我们计算总差异损失为
我们对标记数据和未标记数据都应用了差异监督,因此我们计算总差异损失为
###self.mapping = nn.Conv2d(high_channels // 8 + 48, high_channels // 8 + 48, 1, bias=False)
# discrepancy loss
cos_dis = nn.CosineSimilarity(dim=1, eps=1e-6)
# labeled
labeled_feature1 = labeled_logits['feature1']
labeled_feature2 = labeled_logits['feature2']
loss_dis_labeled1 = 1 + cos_dis(labeled_feature1.detach(), labeled_feature2).mean()
loss_dis_labeled2 = 1 + cos_dis(labeled_feature2.detach(), labeled_feature1).mean()
loss_dis_labeled = (loss_dis_labeled1 + loss_dis_labeled2) / 2
# unlabeled
unlabeled_feature1 = unlabeled_logits['feature1']
unlabeled_feature2 = unlabeled_logits['feature2']
loss_dis_unlabeled1 = 1 + cos_dis(unlabeled_feature1.detach(), unlabeled_feature2).mean()
loss_dis_unlabeled2 = 1 + cos_dis(unlabeled_feature2.detach(), unlabeled_feature1).mean()
loss_dis_unlabeled = (loss_dis_unlabeled1 + loss_dis_unlabeled2) / 2
loss_dis = (loss_dis_labeled + loss_dis_unlabeled) / 2
loss_dis = loss_dis * args.w_dis
因此,对于标记的数据,我们使用真实值标签作为监督,以训练两个子网以生成有语义意义的预测,我们将监督损失表述如下:
回想一下,下标i表示第i个子网,我们用n表示第m个图像中的第n个像素,因此
分别表示第m个标记图像中第n个像素的预测或真实标签。请注意,我们需要对两个子网都执行监督学习,因此我们可以计算监督损失为
# CE loss for labeled data
criterion_l = nn.CrossEntropyLoss(reduction='mean', ignore_index=255).cuda(args.local_rank)
labeled_logits = model(labeled_img)
labeled_pred1 = labeled_logits['pred1']
labeled_pred2 = labeled_logits['pred2']
loss_CE1 = criterion_l(labeled_pred1, labeled_img_mask)##
loss_CE2 = criterion_l(labeled_pred2, labeled_img_mask)
loss_CE = (loss_CE1 + loss_CE2) / 2
loss_CE = loss_CE * args.w_CE
对于未标记的数据,采用伪标签方法,使每个子网都能从另一个子网学习语义信息。给定一个预测
,其生成的伪标签可以写成
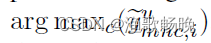
,其中
是
的预测分数的第c维,且c = {1,…, Y}表示类别的索引。我们应用交叉熵损失来微调模型,每个分支的一致性损失可以表示为:

i等于1或2,表示第一个或第二个子网。交叉一致性损失可计算为:


def vote_threshold_label_selection(pred1, pred2, threshold):
"""
input:
pred1 & pred2: logits with per-class prediction probability: B, C, H, W
threshold: confident predictions
output:
label: one label for all three branches
mask: confident or not
"""
# only vote
# same prediction: weight = 1.0
# different prediction: weight = 0.5
pred1_confidence, pred1_label = pred1.max(dim=1)
pred2_confidence, pred2_label = pred2.max(dim=1)
same_pred = (pred1_label == pred2_label)
different_pred = (pred1_label != pred2_label)
different1_confident = different_pred * (pred1_confidence > threshold)
different1_else = ~different1_confident
different2_confident = different_pred * (pred2_confidence > threshold)
different2_else = ~different2_confident
return different1_confident, different1_else, different2_confident, different2_else
different1_confident, different1_else, different2_confident, different2_else = vote_threshold_label_selection(unlabeled_pred1, unlabeled_pred2, conf_threshold)
criterion_u = nn.CrossEntropyLoss(reduction='none').cuda(args.local_rank)
loss_con1_else = criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different1_else & (ignore_img_mask != 255))
loss_con2_else = criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different2_else & (ignore_img_mask != 255))
loss_con1_cc = args.w_confident * criterion_u(unlabeled_pred2, unlabeled_logits['pred1'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different1_confident & (ignore_img_mask != 255))
loss_con2_cc = args.w_confident * criterion_u(unlabeled_pred1, unlabeled_logits['pred2'].softmax(dim=1).max(dim=1)[1].detach().long()) * (different2_confident & (ignore_img_mask != 255))
loss_con1 = (torch.sum(loss_con1_else) + torch.sum(loss_con1_cc)) / torch.sum(ignore_img_mask != 255).item()
loss_con2 = (torch.sum(loss_con2_else) + torch.sum(loss_con2_cc)) / torch.sum(ignore_img_mask != 255).item()
综上所述,在学习模型时,我们联合考虑监督损失Ll sup、一致性损失Lu con和差异损失Ldis,总损失Lall为:

入1, 入2 和 入3 权重参数。
class DeepLabV3Plus(nn.Module):
def __init__(self, args, cfg, use_MLP=False):
super(DeepLabV3Plus, self).__init__()
self.use_MLP = use_MLP
self.use_dropout = args.use_dropout
self.backbone = resnet101
low_channels = 256
high_channels = 2048
self.head = ASPPModule(high_channels, cfg['dilations'])
self.reduce = nn.Sequential(nn.Conv2d(low_channels, 48, 1, bias=False),
nn.BatchNorm2d(48),
nn.ReLU(True))
self.fuse = nn.Sequential(nn.Conv2d(high_channels // 8 + 48, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
nn.Conv2d(256, 256, 3, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True))
self.mapping = nn.Sequential(nn.Conv2d(high_channels // 8 + 48, high_channels // 8 + 48, 1, bias=False), nn.BatchNorm2d(high_channels // 8 + 48), nn.ReLU(True))
self.classifier = nn.Conv2d(256, cfg['nclass'], 1, bias=True)
def forward(self, x):
h, w = x.shape[-2:]
feats = self.backbone(x)##resnet101
c1, c4 = feats[0], feats[-1]
feature, pred = self._decode(c1, c4)##
pred = F.interpolate(pred, size=(h, w), mode="bilinear", align_corners=True)
return feature, pred
def _decode(self, c1, c4):
c4 = self.head(c4)#ASPPModule(high_channels, cfg['dilations'])
c4 = F.interpolate(c4, size=c1.shape[-2:], mode="bilinear", align_corners=True)
c1 = self.reduce(c1)###nn.Sequential(nn.Conv2d(low_channels, 48, 1, bias=False),
# nn.BatchNorm2d(48),
# nn.ReLU(True))
feature = torch.cat([c1, c4], dim=1)
## max the discrepancy between the output feature after concatenation of c1 and c4
# max discrepancy before 3*3 conv
feature = self.mapping(feature)##nn.Sequential(nn.Conv2d(high_channels // 8 + 48, high_channels // 8 + 48, 1, bias=False), nn.BatchNorm2d(high_channels // 8 + 48), nn.ReLU(True))
feature = self.dropout(feature)###nn.Dropout2d(p=args.dropout)
return_feature = feature
feature = self.fuse(return_feature)###nn.Sequential(nn.Conv2d(high_channels // 8 + 48, 256, 3, padding=1, bias=False),
#nn.BatchNorm2d(256),
# nn.ReLU(True),
# nn.Conv2d(256, 256, 3, padding=1, bias=False),
# nn.BatchNorm2d(256),
# nn.ReLU(True))
pred = self.classifier(feature)##nn.Conv2d(256, cfg['nclass'], 1, bias=True)
return return_feature, pred
class Discrepancy_DeepLabV3Plus(nn.Module):
def __init__(self, args, cfg):
super(Discrepancy_DeepLabV3Plus, self).__init__()
self.branch1 = DeepLabV3Plus(args, cfg)
self.branch2 = DeepLabV3Plus(args, cfg, use_MLP=args.use_MLP)
def forward(self, x):
logits = {}
feature1, pred1 = self.branch1(x)
feature2, pred2 = self.branch2(x)
logits['pred1'] = pred1
logits['feature1'] = feature1
logits['pred2'] = pred2
logits['feature2'] = feature2
return logits
3.2 基于冲突的伪标签
使用跨视图一致性(CVC)方法,两个子网将从不同的视图中学习语义信息。然而,训练可能不稳定。然而,由于特征差异损失会对模型引入太强的扰动,训练可能会不稳定。因此,很难保证两个子网能够学习到彼此有用的语义信息。
为了解决该问题,本文提出了一种基于冲突的伪标记(CPL)方法。在这里,我们使用二进制值 来定义预测是否冲突,其
来定义预测是否冲突,其 在
在 时等于1,否则等于0。因此,当使用这些预测来生成伪标签以微调模型时,我们为这些伪标签监督的交叉熵损失分配更高的权重
时等于1,否则等于0。因此,当使用这些预测来生成伪标签以微调模型时,我们为这些伪标签监督的交叉熵损失分配更高的权重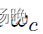 。然而,训练过程中也可能会受到确认偏差[48]的影响,因为一些伪标签可能是错误的。因此,** 按照之前设置置信阈值y来确定预测是否置信的方法 ,
。然而,训练过程中也可能会受到确认偏差[48]的影响,因为一些伪标签可能是错误的。因此,** 按照之前设置置信阈值y来确定预测是否置信的方法 ,
我们进一步将冲突的预测分为两类,即 冲突且置信(CC)预测和冲突但不置信(CU)预测,我们只将 分配给CC预测(冲突且置信(CC)预测)生成的伪标签。
分配给CC预测(冲突且置信(CC)预测)生成的伪标签。
在这里,我们使用二进制值 来定义CC预测,其中,当
来定义CC预测,其中,当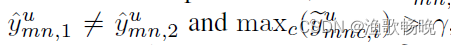 时,
时,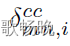 =1,否则
=1,否则 等于0。类似地,我们可以使用
等于0。类似地,我们可以使用 来表示CU冲突且不置信预测和无冲突预测的并集(the union of CU predictions and no-conflicting predictions)
来表示CU冲突且不置信预测和无冲突预测的并集(the union of CU predictions and no-conflicting predictions)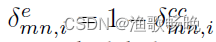 。我们仍然使用CU冲突且不置信预测生成的伪标签来用正常的权重对模型进行微调,而不是直接丢弃它们,主要原因是这些CU冲突且不置信预测也可以包含关于类间关系[44]的潜在信息**。因此,我们可以将等式4重写为
。我们仍然使用CU冲突且不置信预测生成的伪标签来用正常的权重对模型进行微调,而不是直接丢弃它们,主要原因是这些CU冲突且不置信预测也可以包含关于类间关系[44]的潜在信息**。因此,我们可以将等式4重写为

 ,其中
,其中
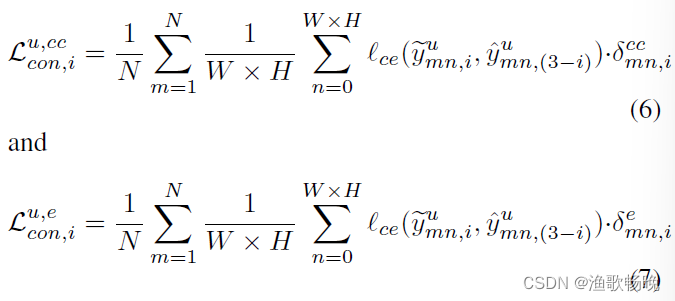
最后,我们可以重新计算总损失L等式5来训练模型。
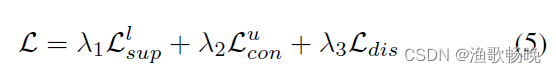
四、实验结果

(1) Pascal VOC 2012数据集上将我们的方法与其他方法进行了比较,结果见表1。采用ResNet-101作为编码器的主干。
(2) 即使所提出模型只训练了40个epoch,而其他模型则训练了80个epoch。
(3) 值得注意的是,当标记数据数量较少时,所提方法表现出了很好的性能,例如,当只有92个或183个标记数据时,所提方法比当前SOTA方法分别提高了2.2%和2.4%。
(4) 我们进一步验证了CCVC方法在渲染的Pascal VOC 2012数据集上的有效性,结果见表2。
(5) 本文报告了分别使用ResNet-50和ResNet-101作为编码器骨干的结果。
(6) 实验结果表明,CCVC方法在使用不同的骨干网时,也可以在所有分区协议下实现SOTA结果,特别是在1/16分区协议下,在使用ResNet-50和ResNet-101作为骨干网时,CCVC方法比目前的SOTA方法分别高出1.7%和1.7%,验证了所提方法的有效性。
从表中可以推断,我们的方法可以取得很好的性能,特别是在标记数据数量较少时,这表明我们的方法可以更好地利用未标记数据。
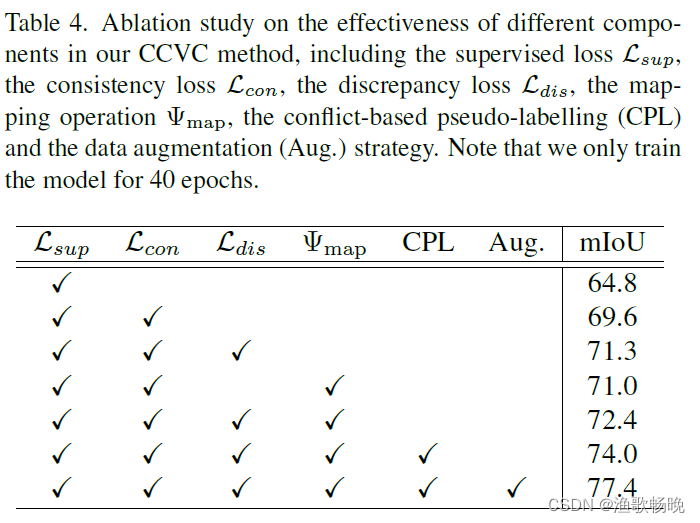
五、消融实验
在本节中,我们分析了CCVC方法详细模块设计的有效性。我们以ResNet-101作为DeepLabv3+的主干,在原始Pascal VOC 2012数据集上进行所有的消融实验,并将其划分为1/4。
组件的有效性。回想一下,我们的CCVC方法包括CVC模块、CPL模块和数据增强(Aug)。请注意,我们的CVC方法中使用了三个损失,即监督损失Csup、一致性损失Lcon和差异损失ldi,以及一个额外的映射模块map。分析结果见表4。
我们计算了在训练过程中每种方法的可靠预测的比例f以及响应的mIoU。可靠预测的阈值
设为0.9。
六、结论
本文提出了一种基于协同训练框架的半监督语义分割方法,引入了跨视图一致性策略,以迫使两个子网学习从不相关的视图中推理相同的输入,然后相互交换信息以产生一致的预测。因此,该方法可以有效地减少崩溃并扩大网络的感知,以产生更可靠的预测,并进一步减少确认偏差问题。在基准数据集上的大量实验验证了新提出方法的有效性。















 2419
2419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









