







目录
一、ES简介
Elasticsearch 是由Apache开源的一个兼有搜索引擎和NoSQL数据库功能的系统,其特点主要如下。
l 基于Java/Lucene构建,支持全文搜索、结构化搜索
l 低延迟,支持实时搜索
l 分布式部署,可横向集群扩展
l 支持百万级数据
l 支持多条件复杂查询,如聚合查询
l 高可用性,数据可以进行切片备份
l 支持Restful风格的api调用
二、ES应用场景
ES作为全文检索的搜索引擎,在以下几个方面都存在着相应的应用:
l 监控。针对日志类数据进行存储、分析、可视化。针对日志数据,ES给出了ELK的解决方案。其中logstash采集日志,ES进行复杂的数据分析,kibana进行可视化展示。
l 电商网站。用于商品信息检索。
l Json文档数据库。用于存放json格式的文档。
l 维基百科。提供全文搜索并高亮关键字
三、ES核心概念
下面分别介绍ES中的核心概念词:
l 集群(Cluster): 包含一个或多个具有相同 cluster.name 的节点.
l 节点(node): 是一个逻辑上独立的服务,可以存储数据,并参与集群的索引和搜索功能, 每个节点都有其唯一的名字,集群通过节点名称进行管理和通信。节点可以充当一个或多个角色。ES集群中的每个节点都会存储集群状态,知道索引内各分片所在的节点位置。
l 主节点(master node):主要负责集群方面的操作,比如节点的加入和退出、索引的创建和删除、分片被分配到哪个节点、节点状态监测。
l 数据节点(Data Node):存储文档数据的节点,执行文档数据的查询和写入等操作。
l 协调节点(Coordinate Node):客户端请求可以发送到集群的任何节点,集群中的每个节点都知道所有文档的位置。接收到客户端请求的节点自动变为协调节点,进行请求的转发,并整合数据返回给客户端。比如创建索引的请求,就转发到主节点。
l 映射(Mapping): mapping是对索引库中的索引字段及其数据类型进行定义,类似于关系型数据库中的表结构。ES默认动态创建索引和索引类型的mapping,这就像是关系型数据库中无需定义表结构,更不用指定字段的数据类型。也可以手动指定mapping类型。mapping机制可以自动检测数据的结构和类型,创建索引并使数据可搜索。
l 分片(shard):索引数据量很大,超过硬件存放单个文件的限制,就会影响查询请求的速度,Es引入了分片技术。一个分片本身就是一个完整的搜索引擎,文档存储在分片中,而分片会被分配到集群中的各个节点中,随着集群的扩大和缩小,ES会自动的将分片在节点之间进行迁移,以保证集群能保持平衡。一个索引中含有shard的数量,默认值为5,在索引创建后这个值是不能被更改的。
l 副本(replica):切片(shard)的冗余备份,每个切片默认的副本数为1。副本数可以随时进行调整。
l 索引(Index): 索引与关系型数据库实例(Database)相当。索引只是一个逻辑命名空间。ES可以把索引数据存放到服务器中,也可以sharding(分片)后存储到多台服务器上。每个索引有一个或多个分片,每个分片可以有多个副本。
l 文档类型(Type):相当于数据库中的table概念。每个文档在ElasticSearch中都必须设定它的类型。文档类型使得同一个索引中在存储结构不同文档时,只需要依据文档类型就可以找到对应的参数映射(Mapping)信息,方便文档的存取。
在 5.X 版本中,一个 index 下可以创建多个 type;
在 6.X 版本中,一个 index 下只能存在一个 type;
在 7.X 版本中,直接去除了 type 的概念,就是说 index 不再会有 type。
原因分析:
为何要去除 type 的概念?
答: 因为 Elasticsearch 设计初期,是直接查考了关系型数据库的设计模式,存在了 type(数据表)的概念。
但是,其搜索引擎是基于 Lucene 的,这种 “基因”决定了 type 是多余的。 Lucene 的全文检索功能之所以快,是因为 倒序索引 的存在。
而这种 倒序索引 的生成是基于 index 的,而并非 type。多个type 反而会减慢搜索的速度。
为了保持 Elasticsearch “一切为了搜索” 的宗旨,适当的做些改变(去除 type)也是无可厚非的,也是值得的。
l 文档(Document) :相当于数据库中的row, 是可以被索引的基本单位。其可以理解为关系型数据库中表的一行数据记录。每个文档由多个字段(field)组成,区别于关系型数据库的是,ES是一个非结构化的数据库,每个文档可以有不同的字段,并且有一个唯一标识。
ES和关系型数据库概念对比如下:
| ES |
关系型数据库 |
| 索引(Index) |
数据库(DataBase) |
| 类型(Type) |
表(Table) |
| 映射(mapping) |
表结构(Schema) |
| 文档(Document) |
行(Row) |
| 字段(Field) |
列(Column) |
| 反向索引 |
正向索引 |
| DSL查询 |
SQL查询 |
l Segment:段,Lucence中存储是按段来进行存储,每个段相当于一个数据集。
l Commit Point:提交点,记录着Lucence中所有段的集合。
l Lucene Index:Lucene索引,由一堆Segment段集合和commit point组成。
l Lucene:Apache开源的全文检索开发工具包,通俗理解是一个java的jar包。
四、ES架构
4.1整体架构
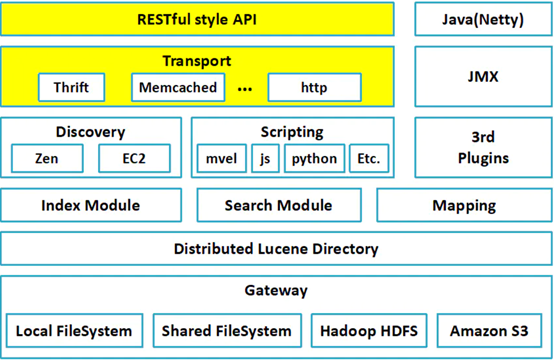
ES整体架构图
下面将由下到上的对ES整体架构图中的各个部分进行介绍:
-
最底层的Gateway部分是ES的数据持久化,ES中的数据可以存储在本地,也可以通过分片的形式进行集群存储,还可以使用hadoop的hdfs分布式文件系统和亚马逊的s3来进行分布式存储。
-
Distributed Lucence Directory:顾名思义,指的是每个索引下切片的Lucence目录
-
ES中间的三个模块分别为索引模块、搜索模块、映
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2560
2560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









