







一、背景
当前的RNN建模方法仅通过考虑用户在过去与之交互的item序列来总结用户状态,而不考虑其他必要类型的上下文信息,例如相关的user-item交互类型,事件之间的时间间隔和每个交互的时间间隔。如:
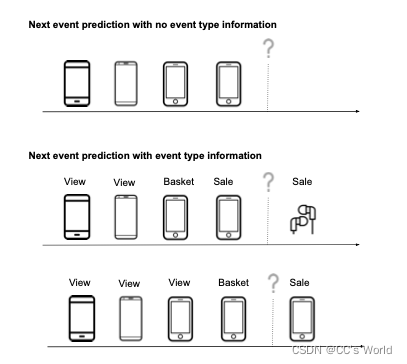
在过去item ID的相同序列上,事件类型的差异导致最有可能的下一个item出现较大差异。最上面的未标记序列代表表示标准RNN可用的信息,导致下面两种可能结果之间的平均预测。在下面的标记序列中,我们观察到用户在上一次活动中购买了手机,因此最有可能访问的下一个项目是补充item,如耳机。在底部标记的序列中,用户将手机添加到购物车中,因此下一个最有可能的事件是用户购买手机。
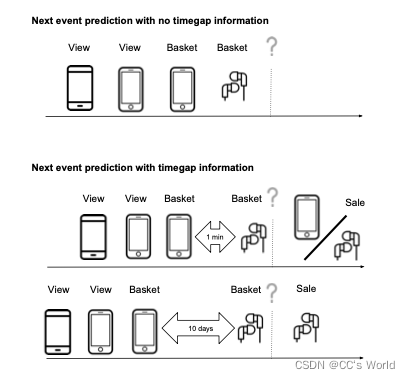
在过去的项目ID的相同序列上,时间间隔的差异导致最有可能的下一个项目出现较大差异。这一次知道最后一个事件与之前的其他事件之间有很大的差距,导致可能性发生很大的变化。
为了解决这个问题,本文提出了一类新的上下文递归推荐神经网络(CRNNs),它可以考虑输入层和输出层的上下文信息,并通过将上下文嵌入与item嵌入相结合来修改RNN的行为,更明确地说,在动态模型中,通过将hidden单元参数化转换为上下文信息的函数。
二、亮点
本文研究了在序列模型中引入上下文的两种方法:
- 上下文相关的输入/输出模型,其中item表示通过一系列非线性变换与上下文相结合;
- 上下文相关的动态模型,其中上下文用于参数化隐藏状态转换的dynamics
三、模型具体结构
给定输入序列
X
=
{
(
x
t
,
c
t
)
,
t
=
1
,
.
.
.
,
T
}
X=\{(x_t,c_t), t=1,...,T\}
X={(xt,ct),t=1,...,T},
其中,
x
t
∈
R
V
x
x_t∈R^{V_x}
xt∈RVx,是t时刻的item id的one-hot编码
c
t
∈
R
V
c
c_t∈R^{V_c}
ct∈RVc,是t时刻的上下文向量
为此定义了序列P(X)上的概率分布,联合概率P(X)可以使用链式规则分解为条件概率的乘积:
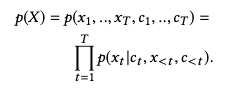
因此,我们的任务简化为在给定当前上下文以及item和上下文的历史的情况下建模下一个item的概率。
整个模型由输入模块、循环结构模块、输出模块组成,模型架构为:

1. 输入模块
输入模块是把稀疏的原始输入数据转化成密集的输入数据。

2. 循环结构模块
用当前输入和上一个输入更新隐藏状态向量,即:
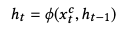
3. 输出模块
基于更新的状态向量和下一个上下文向量返回item的概率分布:

最终基于输出向量
o
t
o_t
ot的softmax给出item的概率分布:
优化目标为:
四、上下文条件的应用
1. 上下文相关的输入/输出表示
concatenation假设补充信息对输入表示没有影响。而乘法交互为item表示提供了更紧密的上下文绑定,比如能捕获相似性。
2. 上下文相关的隐藏动态
大多数循环结构共享同样的计算block:
通过修改这个计算块来引入上下文相关的转换
对于GRU cell,计算块修改为:
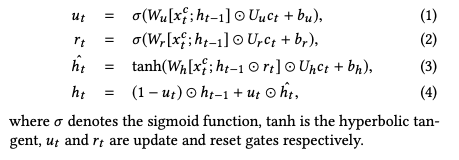















 637
637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









