







在广告/推荐/搜索场景,目前主流算法采用embedding+DNN的模型结构,随着数据量越来越多,单机训练已经无法满足实时要求。针对广告/推荐场景,一般采用Parameter Server的方式进行分布式训练,简称ps,ps可以同时做到对数据和模型的并行训练。Parameter Server直译就是参数服务器,这里的参数,指的是模型权重,以及中间的过程变量。
一、基本原理
以往的分布式计算,比如mapreduce的原理,是将任务和数据分配到多个节点中做并行计算,来缩短任务的执行时间。对于分布式训练来说,同样是希望将训练任务部署到多个节点上并行计算,但是因为反向传播涉及到梯度的汇总和权重的更新,相比之前的分布式计算更加复杂。也有采用hadoop或者spark的分布式训练,用单个driver或者master节点来汇总梯度及更新权重,但是受限于单节点的内存容量,支持的模型大小有限。另外,集群中运行最慢的那个worker,会拖累整个训练的迭代速度。为了解决这些问题,Parameter Server做了新的设计。
Parameter Server主要包括两类节点,一类是server节点,server节点可以有若干个,模型的权重和参数存储在这些server节点中,并在server节点中进行更新,每个server节点都存储和管理一部分模型参数,避免单个master节点内存和算力的不足,从而实现了模型的并行;另外一类是worker节点,也可以有若干个,全部训练样本均匀分配给所有worker节点,worker节点并行执行前向和后向计算,从而实现数据的并行。
worker节点主要通过pull和push这两个操作,和server节点进行通信和交互,pull和push是ps中的重要操作。在训练之前,所有server节点完成对模型权重的初始化。第一次训练,worker节点从全部server节点中,pull相应的权重,进行前后向计算得到梯度,然后把梯度push到对应的多个server节点。server节点获取到所有worker的梯度并做汇总之后,对权重进行一次更新。之后worker节点再一次进行pull和push操作,反复循环,直到worker节点跑完所有的训练数据。
每一次迭代,worker只拉取部分权重,而不需要拉取全部的权重。这是为什么?这要从广告/推荐场景的特点说起,就是特征高维稀疏。所谓高维,就是特征非常多,比如特征数量的规模可以从千万到千亿级别,单机都无法存储,需要分布式存储。所谓稀疏,就是每个训练样本用到的特征非常少,几十几百或者几千,所以每一次训练迭代,只更新了极少部分特征权重,绝大多数权重都没有更新,所以worker只需要拉取部分权重即可,不必把所有的权重都拉到本地,而且模型太大的情况下,worker也放不下。
每个server节点只存储部分权重,如果有多个worker同时用到这部分权重,那么server需要把所有worker的梯度都汇总起来,再去更新权重。而一个worker用到的权重,也可能分布在多个server上,需要从多个server做pull和push。所以worker和server在通信的时候是多对多的关系。
逻辑回归是广告/推荐场景中广泛使用的算法,论文以逻辑回归为例对算法做了描述。逻辑回归目标函数如下,包括loss和正则化这两项,一般采用L1正则化,目的是让大量权重为0,得到稀疏权重,降低线上推理复杂度。
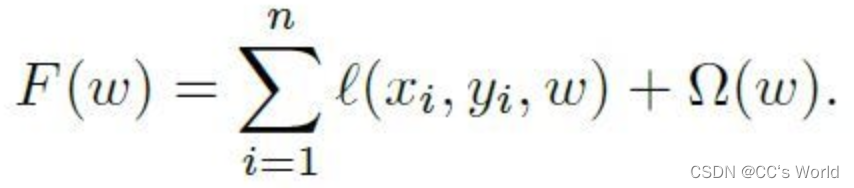
对照下图,完整的算法描述如下:
- 任务调度器:调用LoadData函数,将训练样本分配给所有worker,然后对所有worker进行若干轮迭代;
- worker节点:获取到训练数据,以及初始化权重,进行迭代;
- server节点:从所有worker获取到梯度,并进行汇总aggregate,这里是采用求和,一般求和或平均都可以,计算正则化项的梯度,对权重进行更新。

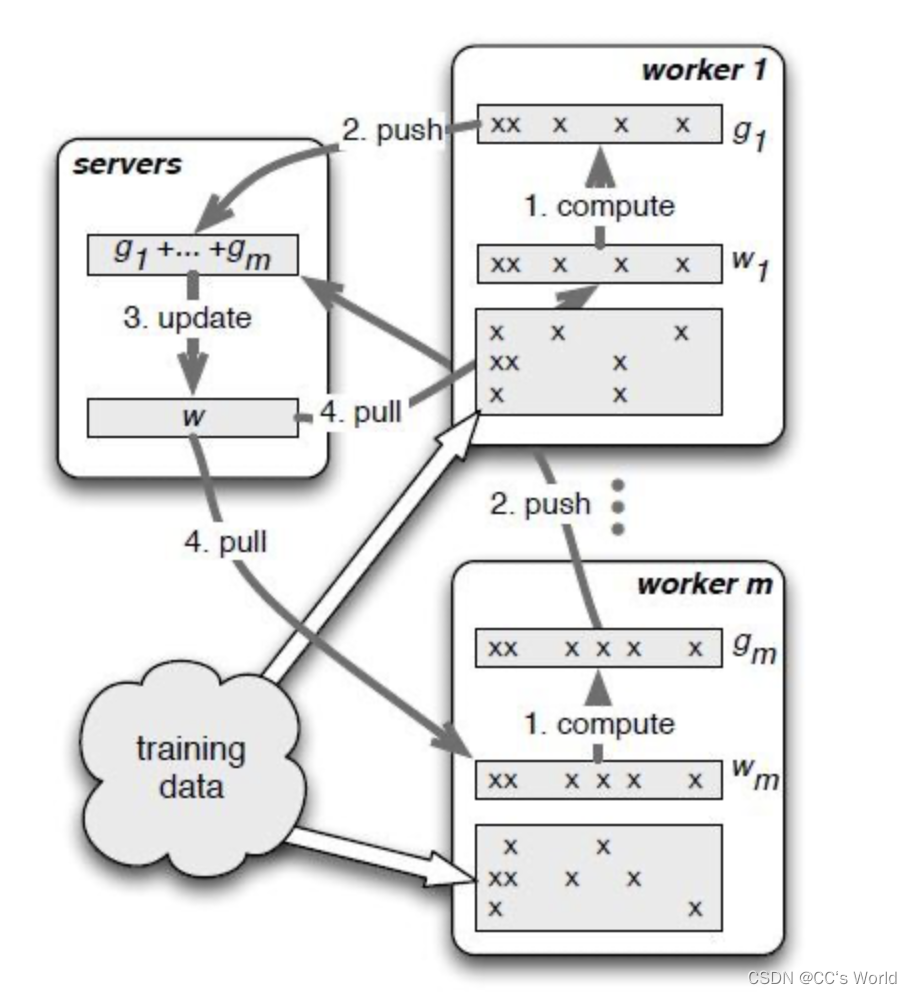
结合下图进一步说明训练过程,在训练之前先将训练样本分配到各个worker上。
- worker根据本地的训练数据和权重w,计算得到梯度g。下图worker的细节很有意思,这里有m个worker,每个worker只分配到部分训练数据,每一部分训练数据只用到了部分特征,对应也只用到了部分权重w,反向传播计算出这部分权重的梯度g。特征,权重w,梯度g,在worker中非空的列是对应的,为空的列表示该worker没有用到的特征/权重/梯度。
- 将计算好的梯度push到servers,servers进行汇总。
- 根据汇总之后的梯度,对权重进行更新。
- worker将更新之后的权重pull到本地。反复循环上述过程,直到迭代结束。
二、整体架构
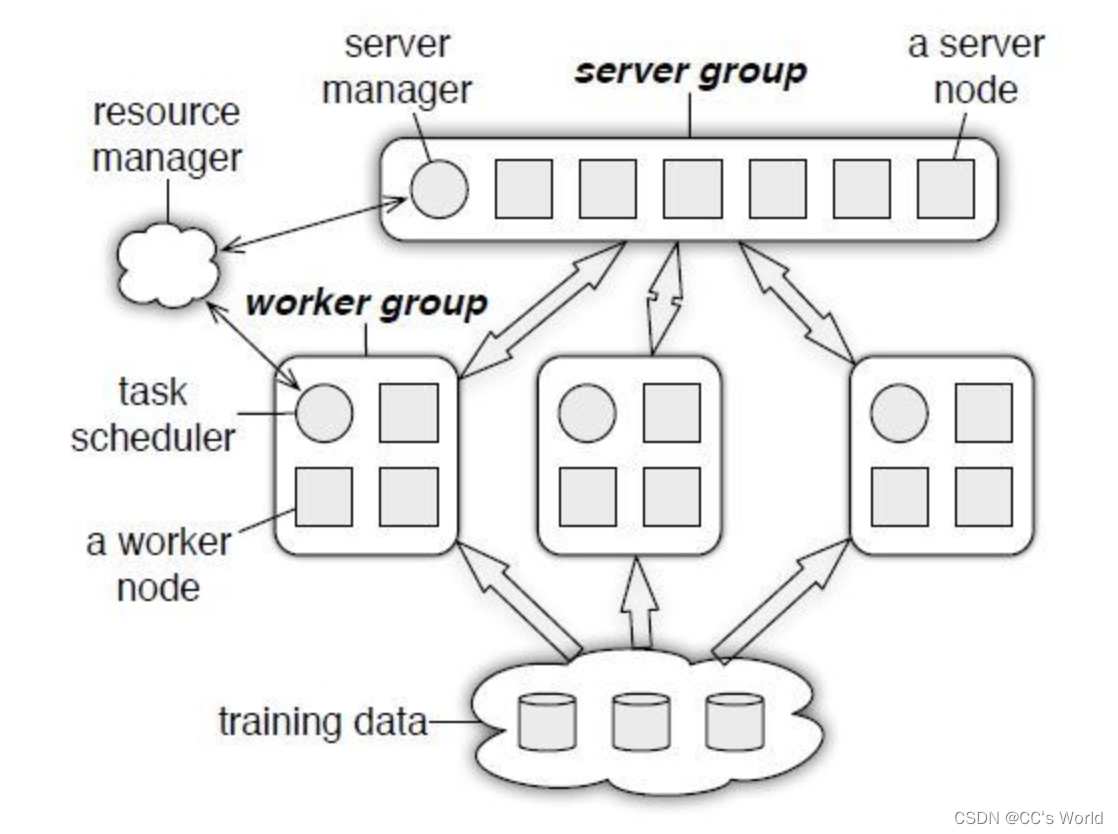
论文中提出的架构下图所示。系统包括一个server group和多个worker group,server group包括一个server manager和若干个server节点,每个worker group包含一个任务调度器task scheduler和多个worker节点,worker group连接分布式文件系统,例如hdfs/s3等,获取到training data。
为了保证伸缩性
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1102
1102

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









