









联邦学习(Federated Learning)近几年很火,本文拟用最通俗语言解释联邦学习的来龙去脉。
分布式学习是什么
其实联邦学习没有那么新颖,任何技术都是有一条主链的,并不是从石头里蹦出来。联邦学习的前身就是分布式学习。(并不是说联邦学习就取代分布式学习,各有适合的场景)
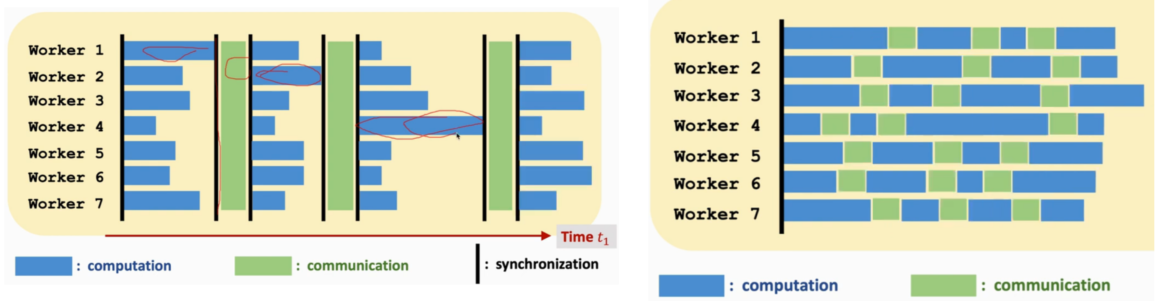
那先简单介绍一下分布式学习,就是你有一个模型要训练,而你手头上有多个CPU或GPU,这时你就想在多个计算节点上同时训练这个模型,来加快训练,这就是分布式学习。一般这些节点有一个老大哥,叫server;一群小弟,叫worker。那么很直观的有两招,同步(多个worker训练完模型的一部分,同时与server通信。),异步(每个worker训练完模型的一部分后就立刻可以与server通信,从而进入下一轮计算。)
左图为同步,右图为异步
同步(MapReduce)
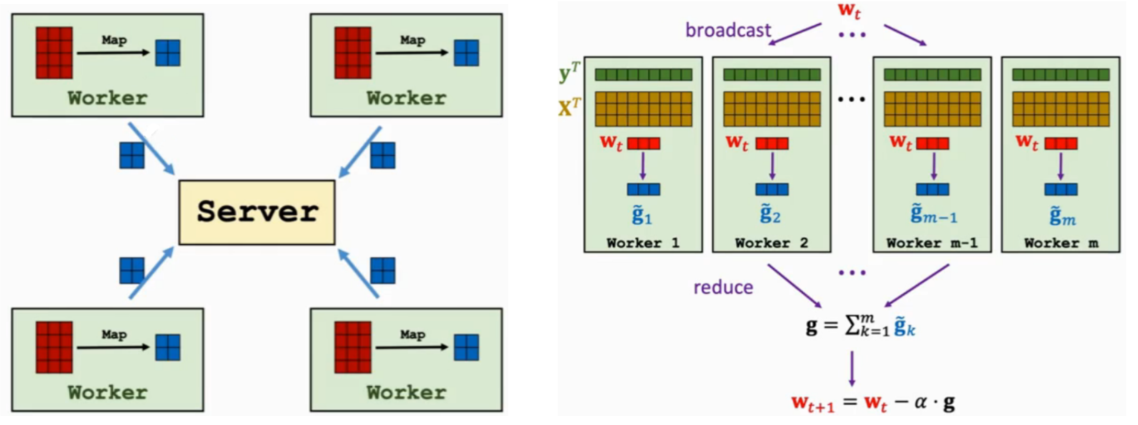
异步(Parameter Server)

现在一般都是异步,因为同步的代价很大,而且会有木桶效应,算力强的节点会被算力弱的节点拖住。但是异步也有它的挑战,比如如果一个算力强的节点已经算了7、8轮,一个算力弱的节点才计算完1轮,这时这个比较迟更新的梯度基于的是老参数,对模型有可能是有害的,即需要设备算力比较均匀。
去中心化
还有一个方案就是去中心化,简单来说就是没有老大哥server了,又或者个个都是server。

题外话:并行计算和分布式学习其实就一个东西,严格点定义就是节点与server之间通信时是有线且在一个不大的区域内,就是并行计算;如果是无线通信,一般我们就叫它分布式计算。
联邦学习是什么
联邦学习是为了解决一些特殊场景下分布式学习,可以理解为分布式学习的一种,带约束的分布式学习。
比如现在想基于用户的手机上产生的数据来训练模型,那么多台手机,我们自然想到分布式学习,但是,现在手机上的数据因为隐私问题我们不希望传到server,手机(worker)对数据有绝对的控制权;同样的场景也有像银行、保险公司、医院等有数据隐私的地方,它们想参与分布式学习,但是还想对数据有绝对控制权。
所以联邦学习就是允许多个参与者协同训练共享模型,同时保持各自数据的隐私和安全。
在联邦学习中,数据不需要集中存储或处理,而是保留在本地。模型的更新(如梯度或模型参数)在本地计算,然后被发送到中央服务器进行聚合,最终形成更新后的全局模型。
分类
根据数据分布:
- 水平联邦学习(Horizontal FL):不同参与者的数据在特征空间上相似,但在样本空间上不同。
- 垂直联邦学习(Vertical FL):不同参与者的数据在样本空间上相似,但在特征空间上不同。

根据模型更新的方式分类:
- 同步更新:所有参与者同时进行本地更新,然后进行聚合。
- 异步更新:参与者在完成本地更新后即可发送更新,无需等待其他参与者。
联邦学习与分布式学习区别(Challenge)
联邦学习有它自己的特点:
- Worker对数据有绝对控制权,不上传到server。(分布式学习server有时会分发数据和要求worker上传数据)
- Worker不稳定,且异构性强。 比如手机有时会关机;手机和ipad不一样,且即使都是手机,型号也不一样。(分布式学习的worker默认是24小时工作,且设备差异不大)
- Worker与Server通信代价很大,大于计算的代价,比如手机有时离server很远,通信带宽小,延迟高等。
- 数据不平衡不均匀,不是独立同分布的。(数据孤岛)
个人理解,分布式学习:专职;联邦学习:兼职(不稳定,异构性强)
前沿方向
- 主流的一个研究问题就是怎么减少节点的通信次数(因为通信代价大嘛,所以想communication-efficient)。经典的方法为 Federated averaging。对于worker,它收到下发的权重w后,用本地data多次地更新w:算梯度g,然后梯度下降更新w,再算梯度g,再更新w。。多次计算后,将最终的w发往server。而server收到多个worker上发的w,对它们求个平均,搞定,再下发给worker。。整个过程很简单,与分布式学习的区别就是边缘节点做了大量的本地计算,以牺牲计算量为代价换取更少通信次数。(一定通信次数后,Federated averaging的方法能使模型收敛更快。)(许多研究已经表明联邦学习的数据不需要独立同分布)
- 隐私(Privacy):梯度只是对数据做了个变换,worker上传的梯度多少带有数据的一些特征,所以可以拿梯度反推数据(性别、种族、年龄、疾病。。) 直观的解决方法:为上传的梯度加噪声(noise),但是效果不好,因为加了noise会影响模型的训练,noise太小也没有什么意义,所以这方向我感觉还没有太有效的方法。
- 提高鲁棒性:如果worker中有不稳定的/异常的节点,它可能发送错误或有害的信息到server,影响模型训练。比较直观的方法,让server对收到的梯度或权重进行验证(但是因为worker的异构性,梯度或权重总是有些区别,所以这个区别正常worker和异常worker验证方法比较难设计)。或是让server用别的方法更新w,比如不用求平均,用求中位数,等等。
- 与其他学习范式的结合:如联邦学习与强化学习、迁移学习的结合,以解决更广泛的问题。
- 去中心化联邦学习:研究去中心化的方法,其中不依赖于中央服务器,而是通过点对点的方式进行模型的更新和聚合。















 2195
2195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











