







基础篇
-
final,finally,finalize之前的区别
- final关键字,代表着不可变,可以保证在过程中不被修改。final修饰的数据,只能读取,不能修改。final修饰的方法表示任何继承类都无法重写。final修饰的类,表示无派生子类,无法被继承。
- finally表示始终被执行的意思,和try,catch一起使用,无论是否发生异常finally内的的语句都会执行。
- finalize是Object的方法,但JVM 进行 GC时,如果对象没有被调用,需要清除,就会执行此方法类,做生前最后的事情(最终遗言),且仅被调用一次
-
重载(Overload)和重写(Override)的区别
- 多个同名的函数存在,有不同类型的参数和不同个数的的参数。(返回类型、访问权限大小和异常不同不算为重载)。
- 又叫覆盖,是子类继承父类的方法,并重新定义。
-
简单介绍一下反射机制,反射的用途和实现
-
反射在Java中有运行和编译两种状态。指在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象。
-
获取class对象的方法来使用反射
-
通过对象Object的getClass()方法、通过类的静态class属性、通过Class类的静态方法forName(String className)

-
-
抽象类和接口的区别
- 抽象类是被abstract修饰的类,抽象类中可以拥有任意范围的成员数据,可以定义非抽象方法。
- 接口时interface,接口中只能拥有静态的不可修改的数据且所有的方法都是抽象的
-
equals和==的区别
- ==可以比较基本数据类型,比较两者在内存中的值,当 == 比较的复合类型的时候是比较的堆内存地址。
- equals比较复合数据也是比较的堆内存地址和==的功能是一样的,底层equals也是 ==,但是String重写了equals()方法,比较的是内容是否相同。
-
各类内部类的区别
- 成员内部类:普通内部类,与外部类存在联系,需要依赖外部类方能实例化
- 静态内部类:与外部对象不存在联系。可直接实例化
- 匿名内部类:无名,继承或实现那个类
- 局部内部类:方法体内或作用域内可以使用
-
作用域 公开的public,受保护的protected默认friendly,私有的private的区别

-
Object常用的方法有哪些?
equals()、toString()、finalize()、getClass()、hashCode()、clone()、wait()、notify()、notifyAll()
-
wait和sleep的区别
- sleep是线程中的方法,但是wait是Object中的方法。
- sleep方法不会释放lock,但是wait会释放,而且会加入到等待队列中。
- sleep方法不依赖于同步器synchronized,但是wait需要依赖synchronized关键字。
- sleep不需要被唤醒(休眠之后推出阻塞),但是wait需要(不指定时间需要被别人中断)。
-
notify()、notifyAll()是什么,有什么区别
-
当线程执行wait()方法时候,会释放当前的锁,然后让出CPU,进入等待状态。
-
notify/notifyAll() 的执行只是唤醒沉睡的线程,而不会立即释放锁,锁的释放要看代码块的具体执行情况。所以在编程中,尽量在使用了notify/notifyAll() 后立即退出临界区,以唤醒其他线程让其获得锁。
-
notify 和wait 的顺序不能错,如果A线程先执行notify方法,B线程在执行wait方法,那么B线程是无法被唤醒的。
区别
notify()是只唤醒一个等待的线程,如果存在多个线程的情况,由操作系统对多线程管理来决定。notifyAll 会唤醒所有等待(对象的)线程,尽管哪一个线程将会第一个处理取决于操作系统的实现。如果当前情况下有多个线程需要被唤醒,推荐使用notifyAll 方法。比如在生产者-消费者里面的使用,每次都需要唤醒所有的消费者或是生产者,以判断程序是否可以继续往下执行。在多线程中如果根据条件决定是否执行,使用while不用if。因为while 具有判断条件成立后在执行。
-
-
String和StringBuffer、StringBuilder的区别
- String是一个Java的基础数据类型,在内存堆上被创建。因为被final修饰,String 一旦被创建后出来,值不能改变,String的所有方法都不能改变本身的值,而是返回一个新的String对象。String是使用字符数组保存字符串
- 共同的父类。StringBuffer是和StringBuilder的父类是AbstracStringBuilder,这两种对象都是可变的。
- 线程安全性。String不可变,可以理解为常量,所以是线程安全的,StringBuffer引入了同步锁或者对调用的方法使用了线程锁,所以也是线程安全的。
- StringBuilder没有线程锁,是线程不安全的。
-
可变与不可变化性
不可改变的都是一定是线程安全的,因为只有一种状态,被final修饰,对象创建后不可修改。
-
hashCode和equals方法的关系
- 对于两个对象,如果调用equals方法得到的结果为true,则两个对象的hashcode值必定相等;
- 如果equals方法得到的结果为false,则两个对象的hashcode值不一定不同;
- 如果两个对象的hashcode值不等,则equals方法得到的结果必定为false;
- 如果两个对象的hashcode值相等,则equals方法得到的结果未知。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u4VriB2c-1592905800334)(C:%5CUsers%5Csuiqu%5CAppData%5CRoaming%5CTypora%5Ctypora-user-images)]
-
HTTP 请求的 GET 与 POST 方式的区别
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iAzPzZbu-1592905583769)(C:\Users\suiqu\AppData\Roaming\Typora\typora-user-images\image-20200603221720943.png)]](https://i-blog.csdnimg.cn/blog_migrate/f1162e0d1d28261a358b47122e34d754.png)
-
session 与 cookie 区别
-
cookie数据存放在客户的浏览器上,session数据放在服务器上。
-
cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,考虑到安全应当使用session。
-
session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能考虑到减轻服务器性能方面,应当使用cookie。
-
单个cookie保存的数据不能超过4K,很多浏览器都限制一个站点最多保存20个cookie。
所以个人建议:将登陆信息等重要信息存放为session。其他信息如果需要保留,可以放在cookie中
-
集合篇
-
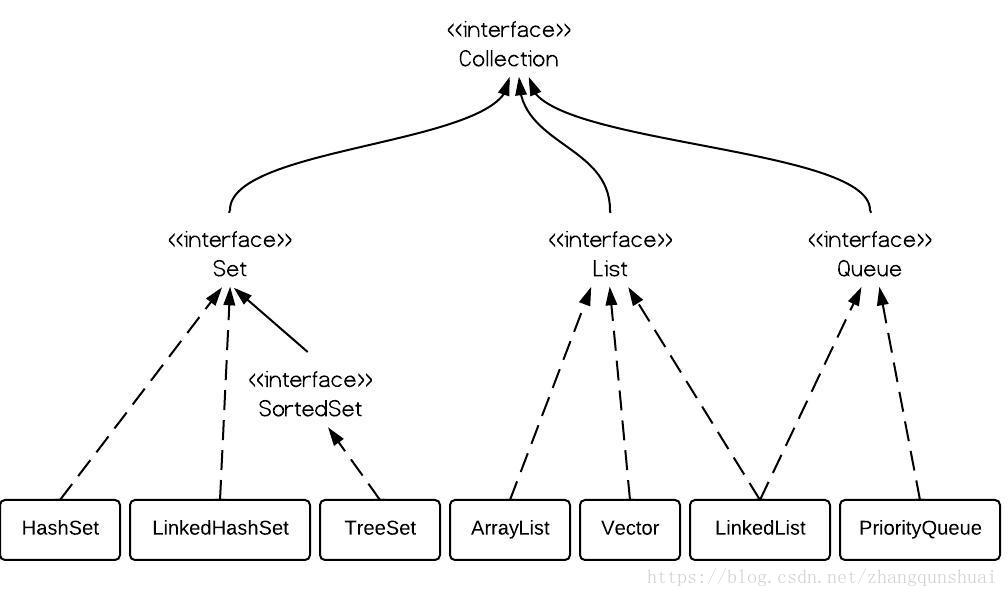
List,Set,Map之间的区别
-
List,Set,Map都是接口,但是List,Set是继承Collection接口,Map为单独的接口
-
Set下有HashSet,LinkedHashSet,TreeSet
-
List下有ArrayList,Vector,LinkedList
-
Map下有Hashtable,LinkedHashMap,HashMap,TreeMap
-
Collection接口下还有个Queue接口,有PriorityQueue类
-
注意:
Queue接口与List、Set同一级别,都是继承了Collection接口。
看图你会发现,LinkedList既可以实现Queue接口,也可以实现List接口.只不过呢, LinkedList实现了Queue接口。Queue接口窄化了对LinkedList的方法的访问权限(即在方法中的参数类型如果是Queue时,就完全只能访问Queue接口所定义的方法 了,而不能直接访问 LinkedList的非Queue的方法),以使得只有恰当的方法才可以使用。SortedSet是个接口,它里面的(只有TreeSet这一个实现可用)中的元素一定是有序的。
-
-
集合类分析总结
-
— List 有序,可重复
ArrayList
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程不安全,效率高
LinkedList
优点: 底层数据结构是链表,查询慢,增删快。
缺点: 线程不安全,效率高Vector
优点: 底层数据结构是数组,查询快,增删慢。
缺点: 线程安全,效率低 -
Set 无序,唯一
HashSet
底层数据结构是哈希表。(无序,唯一)
如何来保证元素唯一性?
1.依赖两个方法:hashCode()和equals()LinkedHashSet
底层数据结构是链表和哈希表。(FIFO插入有序,唯一)
1.由链表保证元素有序
2.由哈希表保证元素唯一TreeSet
底层数据结构是红黑树。(唯一,有序)- 如何保证元素排序的呢?
自然排序
比较器排序
2.如何保证元素唯一性的呢?
根据比较的返回值是否是0来决定
- 如何保证元素排序的呢?
-
针对Collection集合我们到底使用谁呢?(掌握)
if(唯一?){ 使用Set if(排序?){ TreeSet或LinkedHashSet }else{ HashSet(默认) } }else{ List if(线程安全吗?){ Vector }else{ ArrayList:查询速度快,增删慢 LinkedList: 查询速度慢,增删快 } } -
Map的一些东西。

- Map接口有三个比较重要的实现类,分别是HashMap、TreeMap和HashTable。
- TreeMap是有序的,HashMap和HashTable是无序的。
- Hashtable的方法是同步的,也是线程安全,HashMap的方法不是同步的,也是线程不安全。这是两者最主要的区别。
-
HashTable和HashMap的区别
- 线程安全,HashTable 是同步的也是线程安全的,而HashMap是不同步的,也是线程不安全。
- 效率。HashTable的执行效率要比HashMap低一些,但是如果对同步性和线程问题没要求的情况下推荐使用HashMap
- Null值。在HashTable 中是不允许使用Null值,但是在Hash Map中Key和Value 都可以为Null。
- 父类不同。HashTable 的父类是Dictionary而HashMap的父类是AbstractMap。
-
HashSet 和 HashMap 区别
- HashMap实现了Maps HashSet继承的是Collection接口
- HashMap存储kay-value,HashSet只存储对象
- 两者都使用hashCode来计算kay和对象,equals方法判断对象相同 也相同
-
ConcurrentHashMap 的工作原理
-
ConcurrentHashMap 的加锁粒度要比HashTable更细一点。将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。(分段锁)
-
Segment继承了ReentrantLock,所以它就是一种可重入锁(ReentrantLock)。在ConcurrentHashMap,一个Segment就是一个子哈希表,Segment里维护了一个HashEntry数组,并发环境下,对于不同Segment的数据进行操作是不用考虑锁竞争的。(就按默认的ConcurrentLeve为16来讲,理论上就允许16个线程并发执行)
-
具体解释和总结,很棒!
https://www.baidu.com/link?url=f3UWlcJcGkMogsmnsGc_Hrgbnh1Qfkdl8ojdzZM73lZIpjvOAXK0n8fCRHY-nKAWyhbe0wrA0TdJA1qEkmBgaa&wd=&eqid=bfc65ebf00036d59000000065b9a2f25
-
-
ConcurrentHashMap与HashMap的区别
- HashMap和concurrentHashMap都是基于散列,数组和链表
- 最大的区别就是线程安全问题,ConcurrentHashMap有分段锁的机制。当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
-
CopyOnWriteArrayList和CopyOnWriteArraySet的工作原理
CopyOnWriteArraySet是基于CopyOnWriteArrayList实现的,只有add的方法稍微有些不同,因为CopyOnWriteArraySet是Set也就是不能有重复的元素,故在CopyOnWriteArraySet中用了addIfAbsent(e)这样的方法。
写入时复制一个数组,对复制后产生的新数组进行操作,而旧的数组不会有影响,所以旧的数组可以依旧就行读取(可以看出来,读的时候如果有新的数据正在写是无法实时的读取到的,有延时,得等新数据写完以后,然后才可以读到新的数据)
多个线程同时去写,多线程写的时候会Copy出N个副本出来,那么可能内存花销很大,所以用一个重入显式锁ReetrantLock锁住,一次只能一个线程去添加。
读取时,不用进行线程同步。可重入就意味着:线程可以进入任何一个它已经拥有的锁所同步着的代码块
java中常用的可重入锁
synchronized
java.util.concurrent.locks.ReentrantLock
-
线程篇
-
启动线程是run() 还是start()?
-
Strat()方法是启动(开辟)线程的方法,因此线程的启动必须通过此方法.
读取时,不用进行线程同步。可重入就意味着:线程可以进入任何一个它已经拥有的锁所同步着的代码块
java中常用的可重入锁
synchronized
java.util.concurrent.locks.ReentrantLock
-
















 914
914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









