






 本文探讨了主机NFSServer与QEMU虚拟机Client之间的NFS问题,涉及网络连接问题、防火墙设置、协议版本不匹配等。通过ping测试、iptables调整和配置文件检查,作者逐步解决了noroutetohost和Protocolnotsupported错误。
本文探讨了主机NFSServer与QEMU虚拟机Client之间的NFS问题,涉及网络连接问题、防火墙设置、协议版本不匹配等。通过ping测试、iptables调整和配置文件检查,作者逐步解决了noroutetohost和Protocolnotsupported错误。
前提:主机侧为nfs server端,启动的qemu虚拟机为client客户端。打算将主机侧的指定文件夹与虚拟机侧共享,遇到的nfs问题。
1. nfs:no route to host 或者 Connection timed out(我遇到的都是网络不通)
一、问题描述
在挂载server服务端下的文件夹时,出现如下错误:
mount -t nfs -o nolock,vers=4 192.168.1.1:/home/data /data
mount.nfs::no route to host
二、问题分析
NFS(Network File System,网络文件系统),能使使用者访问网络上别处的文件,就像是在使用自己服务器下的文件一样。NFS 的默认传输协议是 UDP
我遇到上述问题可能存在的原因:
- 网络不通
- NFS服务没有配置好。
三、解决方案
关于配置的问题,先查一下
[root@host-26 zhyn]# showmount -e localhost
Export list for localhost:
/home/svp_docker_ci 10.89.235.0/24,10.234.72.0/24,192.168.1.0/24
1.确认虚拟机网络与主机侧server端是否是通的
在虚拟机内部ping server主机侧的虚拟网桥ip:
bash-4.4# ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1): 56 data bytes
64 bytes from 192.168.1.1: seq=0 ttl=64 time=0.401 ms
64 bytes from 192.168.1.1: seq=1 ttl=64 time=0.187 ms
同时在server主机侧对虚拟网桥进行抓包:
[root@host-26 zhyn]# tcpdump -i qemu-br0
dropped privs to tcpdump
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on qemu-br0, link-type EN10MB (Ethernet), capture size 262144 bytes
10:05:41.305274 IP 192.168.1.105 > nfs-server: ICMP echo request, id 29697, seq 19, length 64
10:05:41.305300 IP nfs-server > 192.168.1.105: ICMP echo reply, id 29697, seq 19, length 64
然后在server主机侧ping 虚拟机内部ip
[root@host-26 zhyn]# ping 192.168.1.105
PING 192.168.1.105 (192.168.1.105) 56(84) bytes of data.
64 bytes from 192.168.1.105: icmp_seq=1 ttl=64 time=0.273 ms
64 bytes from 192.168.1.105: icmp_seq=2 ttl=64 time=8.04 ms
同时在虚拟机内部对虚拟网卡 进行抓包:
bash-4.4# tcpdump -i eth0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
02:14:32.608971 IP 192.168.1.1 > 192.168.1.105: ICMP echo request, id 605, seq 27, length 64
02:14:32.609000 IP 192.168.1.105 > 192.168.1.1: ICMP echo reply, id 605, seq 27, length 64
如上述过程中可能存在任意一方不通,或者双方相互可以ping通,但是nfs挂载不上——大概率是防火墙的问题。我遇到的是在虚拟机内部ping主机侧是可以ping通的,但是在主机侧ping虚拟机内部,遇到类似这样的报错:
[root@host-26 zhyn]# ping 192.168.1.105
ping:sendmsg 不允许的操作
ping:sendmsg 不允许的操作
ping自己的虚拟网桥ip
[root@host-26 ~]# ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
ping: sendmsg: Operation not permitted
ping: sendmsg: Operation not permitted
同时在虚拟机内部抓包的情况是
bash-4.4# tcpdump -i eth0
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
02:14:32.608971 IP 192.168.1.1 > 192.168.1.105: ICMP echo request, id 605, seq 27, length 0
02:14:32.609000 IP 192.168.1.105 > 192.168.1.1: ICMP echo reply, id 605, seq 27, length 0
上述情况主机侧的防火墙的问题:
1. 关闭防火墙和selinux
[root@host-26 ~]# systenctl stop firewalld
[root@host-26 ~]# setenforce 0
执行上述操作后,我的问题依然没有解决,主机侧任然无法ping通虚拟机
2.相关关于iptables的操作
iptables默认策略(Filter内建表)为拒绝所有:
iptables -P INPUT DROP
iptables -P OUTPUT DROP
查找相关资料的操作:
[root@host-26 ~]# systemctl stop iptables.service
[root@host-26 ~]# iptables -A INPUT -p icmp --icmp 8 -j ACCEPT #允许请求进来
[root@host-26 ~]# iptables -A OUTPUT -p icmp --icmp 0 -j ACCEPT #允许响应出去
经过上述操作以后,双方的的网络可以下相互ping通,但是nfs还是无法挂载
3.接着查找OpenStack相关帖子执行的操作:
修改iptables默认策略(Filter内建表,有三条内建链)为接收所有:
[root@host-26 ~]# iptables -P OUTPUT ACCEPT
[root@host-26 ~]# iptables -P INPUT ACCEPT
[root@host-26 ~]# iptables -P FORWARD ACCEPT
同时执行添加iptables规则
[root@host-26 ~]# iptables -A OUTPUT -p icmp --icmp-type echo-request -j ACCEPT
[root@host-26 ~]# iptables -A INPUT -p icmp --icmp-type echo-reply -j ACCEPT
讲过上述操作,我的问题已经解决。
注意:在执行到server主机侧和虚拟机侧可以相互ping通的情况下,如果继续报no route to host
则不要急着执行第3步OpenStack查找的步骤,先查看server主机侧的/etc/exports文件(为nfs的配置文件,即nfs的配置问题)
[root@host-26 zhyn]# cat /etc/exports
/home/data 192.168.1.0/24(rw,no_root_squash,async)
#/home/data为主机侧共享的目录,192.168.1.0/24对应可以挂载此目录的ip端,括号内部即为
#相关读写权限。自行查找资料看吧。查看ip段是否配对,以及相关读写权限设置是否正确。
2. nfs.mount:Protocol not supported
一、问题描述
在挂载server服务端下的文件夹时,出现如下错误:
mount -t nfs -o nolock,vers=4 192.168.1.1:/home/data /data
mount.nfs: Protocol not support
二、问题分析
查找过相关资料,可能是nfs server和nfs client版本不匹配的原因
三、解决方案
在server主机侧执行nfsstat -s
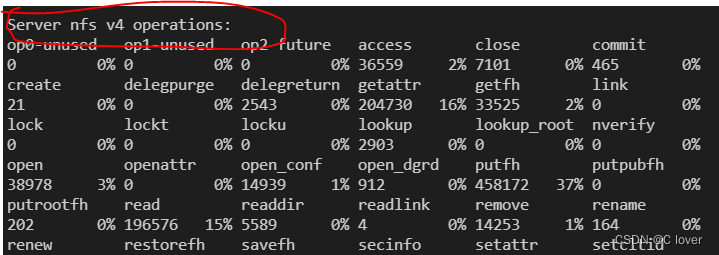
在client虚拟机侧执行nfsstat -c
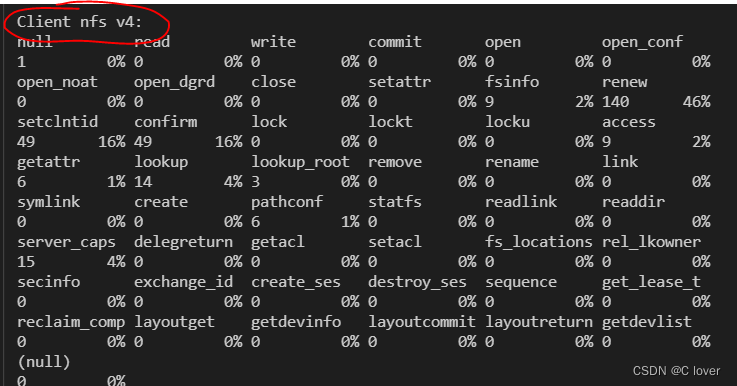
两个nfs版本一致即可。
mount -t nfs -o nolock,vers=4 192.168.1.1:/home/svp_docker_ci /svp_docker_ci
上述操作在client虚拟机内执行,vers对应指定版本,可以为2、3、4
这个配置文件在/etc/nfsmount.conf里面,找到和协议版本相关的内容:
[ NFSMount_Global_Options ]
# This statically named section defines global mount
# options that can be applied on all NFS mount.
#
# Protocol Version [2,3,4]
# This defines the default protocol version which will
# be used to start the negotiation with the server.
# Defaultvers=4
相关参考资料
nfs安装
nfs安装
iptables手册
Ping: sendmsg: operation not permitted
nfs client connection timeout

















 22万+
22万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









