







Kuboard部署Prometheus+Grafana
1、监控的重要性
通过业务监控系统,全⾯掌握业务环境的运⾏状态,通过⽩盒监控能够提前预知业务瓶颈,通过⿊盒监 控能够第⼀时间发现业务故障并通过告警通告运维⼈员进⾏紧急恢复,从⽽将业务影响降到最低。
⿊盒监控,关注的是时时的状态,⼀般都是正在发⽣的事件,⽐如nginx web界⾯打开的是界⾯报错503、 磁盘⽆法报错数据等,即⿊盒监控重点在于能对正在发⽣的故障进⾏通知告警。 ⽩盒监控,关注的是原因,也就是系统内部暴露的⼀些指标数据,⽐如nginx 后端服务器的响应时⻓、磁盘 的I/O负载值等。
监控系统需要能够有效的⽀持⽩盒监控和⿊盒监控,通过⽩盒能够了解其内部的实际运⾏状态,以及对 监控指标的观察能够预判可能出现的潜在问题,从⽽对潜在的不确定因素进⾏提前优化并避免问题的发 ⽣,⽽通过⿊盒监控,⽐如常⻅的如HTTP探针、TCP探针等,可以在系统或者服务在发⽣故障时能够快 速通知相关的⼈员进⾏处理,通过建⽴完善的监控体系,从⽽达到以下⽬的:
1.1、⻓期趋势分析
通过对监控样本数据的持续收集和统计,对监控指标进⾏⻓期趋势分析。例如,通过对磁盘 空间增⻓率的判断,我们可以提前预测在未来什么时间节点上需要对资源进⾏扩容。
1.2、对照分析
两个版本的系统运⾏资源使⽤情况的差异如何?在不同容量情况下系统的并发和负载变化如何? 通过监控能够⽅便的对系统进⾏跟踪和⽐较。
1.3、告警通知
当系统出现或者即将出现故障时,监控系统需要迅速反应并通知管理员,从⽽能够对问题进⾏快速的 处理或者提前预防问题的发⽣,避免出现对业务的影响。
1.4、故障分析与定位
当问题发⽣后,需要对问题进⾏调查和处理。通过对不同监控监控以及历史数据的分析, 能够找到并解决根源问题。
1.5、故障分析与定位
通过可视化仪表盘能够直接获取系统的运⾏状态、资源使⽤情况、以及服务运⾏状态等直观的 信息。
2、prometheus 简介
Prometheus是基于go语⾔开发的⼀套开源的监控、报警和时间序列数据库的组合,是由SoundCloud 公司开发的开源监控系统,Prometheus于2016年加⼊CNCF(Cloud Native Computing Foundation, 云原⽣计算基⾦会),2018年8⽉9⽇prometheus成为CNCF继kubernetes 之后毕业的第⼆个项⽬, prometheus在容器和微服务领域中得到了⼴泛的应⽤,其特点主要如下:
使⽤key-value的多维度(多个⻆度,多个层⾯,多个⽅⾯)格式保存数据 数据不使⽤MySQL这样的传统数据库,⽽是使⽤时序数据库,⽬前是使⽤的TSDB ⽀持第三⽅dashboard实现更绚丽的图形界⾯,如grafana(Grafana 2.5.0版本及以上) 组件模块化 不需要依赖存储,数据可以本地保存也可以远程保存 平均每个采样点仅占3.5 bytes,且⼀个Prometheus server可以处理数百万级别的的metrics指标数据。 ⽀持服务⾃动化发现(基于consul等⽅式动态发现被监控的⽬标服务) 强⼤的数据查询语句功(PromQL,Prometheus Query Language) 数据可以直接进⾏算术运算 易于横向伸缩 众多官⽅和第三⽅的exporter实现不同的指标数据收集
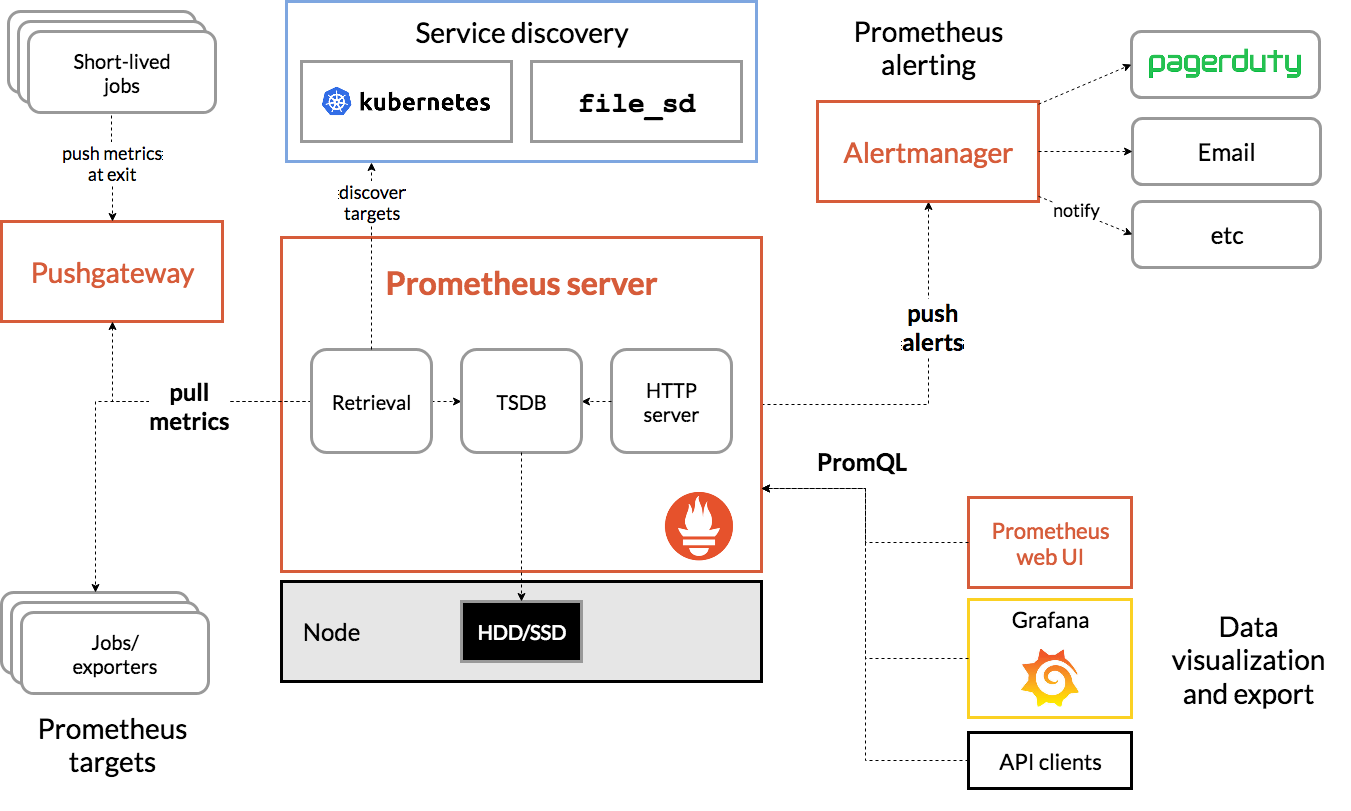
3、prometheus架构图
prometheus server:主服务,接受外部http请求,收集、存储与查询数据等
prometheus targets: 静态收集的⽬标服务数据
service discovery:动态发现服务
prometheus alerting:报警通知
push gateway:数据收集代理服务器(类似于zabbix proxy)
data visualization and export: 数据可视化与数据导出(访问客户端)
4、prometheus 部署使用
prometheus的方式有很多,为了兼容k8s环境,我们将prometheus搭建在k8s里,除了使用docker镜像的方式安装,还可以使用二进制的方式进行安装,支持mac、Linux、windows,本次我们使用kuboard里的监控套件来安装。
Kuboard 监控套件基于 https://github.com/prometheus-operator/kube-prometheus 构建,主要的工作是对其做 Kuboard 套件进行适配,修改的内容包括:
-
以 Kuboard 套件形式安装 kube-prometheus;
-
提供监控告警的配置界面。
4.1、安装NFS
因为prometheus是部署在K8S中的,生命周期和Pod生命周期是一致的,重启K8S后,数据也就丢失了,对应的监控数据也就没有了,所以我们需要对监控数据做持久化处理。
为了使 Pod 在任何节点上都能够使用同一份持久化存储数据,我们需要使用网络存储的解决方案为 Pod 提供 数据卷。常用的网络存储方案有:NFS、cephfs、glusterfs。
4.1.1、NFS服务端安装
在K8Smaster节点执行以下命令安装NFS服务器
sudo apt install nfs-kernel-server
要启动 NFS 服务器,您可以在终端提示符处运行以下命令
sudo systemctl start nfs-kernel-server.service
执行命令 vim /etc/exports,创建 exports 文件,文件内容如下:
/root/nfs_root/ *(insecure,rw,sync,no_subtree_check,no_root_squash)
创建共享目录
# 如果要使用自己的目录,请替换本文档中所有的 /root/nfs_root/
mkdir /root/nfs_root
通过以下方式应用新配置:
sudo exportfs -a
#检查配置是否生效
exportfs


4.1.2、NFS客户端配置
在K8Snode节点执行以下命令安装NFS客户端
#安装
sudo apt install nfs-common
#检查 nfs 服务器端是否有设置共享目录
# showmount -e $(nfs服务器的IP)
执行以下命令检查 nfs 服务器端是否有设置共享目录
showmount -e 172.17.216.82
# 输出结果如下所示
Export list for 172.17.216.82:
/root/nfs_root *
#执行以下命令挂载 nfs 服务器上的共享目录到本机路径 /root/nfsmount
mkdir /root/nfsmount
# mount -t nfs $(nfs服务器的IP):/root/nfs_root /root/nfsmount
mount -t nfs 172.17.216.82:/root/nfs_root /root/nfsmount
# 写入一个测试文件
echo "hello nfs server" > /root/nfsmount/test.txt
#在 nfs 服务器上执行以下命令,验证文件写入成功
cat /root/nfs_root/test.txt
#客户端解除挂载
umount ~/nfsmount



4.2、在Kuboard中创建 NFS 存储类
打开 Kuboard 的集群概览页面,点击 创建存储类 按钮,如下图所示
| 字段名称 | 填入内容 | 备注 |
|---|---|---|
| 名称 | nfs-storage | nfs名称 |
| NFS Server | 192.168.110.244 | NFS服务的IP地址 |
| NFS Path | /root/nfs_root | NFS服务所共享的路径 |

4.3、安装监控套件
在 Kuboard 界面中导航到 集群导入 --> 套件 --> 套件仓库 --> 资源层监控套件,然后在界面的引导下完成 资源层监控套件 的安装。如下图所示:

点击查看,按照安装指引,完成1,2,3,4步
第一步

点击保存,之后的2,3,4步,一直点击下一步即可
第二步是预安装,会检查所需要的配置是否齐全

第二步完成后,开始第三步,第三步为正式安装

第三步安装需要等待一段时间,成功后会弹出提示框,点击确定


点击确定,刷新后进到第4步

安装完成后,可以配置告警规则,此处以配置钉钉告警为例

切换到 联系人组 标签页,点击 添加钉钉机器人,并填写相关信息,如下图所示:
默认有三个联系人组,建议每个联系人组至少配置一个联系人邮件地址。
- 将 配置钉钉机器人 时获得的
access_token以及加签填入对应位置。

-
点击
保存按钮,保存您做的配置修改 -
切换到
告警规则-->kubernetes-monitoring-->kubernetes-apps的标签页,在该标签页修改告警名称KubePodCrashLooping的持续时间为1m(代表 1 分钟),如下图所示:

- 模拟错误
在任意名称空间创建一个 Deployment,将其中的容器 image 设置为 busybox,命令行参数为空。此时,busybox 将在启动后就立刻退出,我们就可以模拟出应用程序不断崩溃重启的现象。

- 查看告警事件
切换到 告警事件 标签页,如下图所示:
大约 1 分钟后,KubePodCrashLooping 的事件将从
PENDING状态切换到FIRING状态,表明告警事件已发送到 AlertManager

-
查看钉钉告警
登录钉钉,可以查看该告警消息如下所示:
AlertManager 在收到告警事件后,大约需要等 1 分钟左右(取决于告警路由中的配置)才发送邮件给告警联系人。

4.3、查看prometheus主页
-
导航到
资源监控套件的安装页面 -
点击右上角的prometheus主页按钮

打开后即为prometheus主页,在此可以查看K8S的状态及告警


4.4、查看Grafana主页

点击后会自动免登录跳转到Grafana主页

kuboard已经默认为Grafana配置了Prometheus的数据源,直接点击查看即可



















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









